Covert our documentation links to GH absolute links (#14344)
Signed-off-by: Tasos Katsoulas <tasos@netdata.cloud>
This commit is contained in:
parent
caf18920aa
commit
9f1403de7d
42
README.md
42
README.md
|
|
@ -22,7 +22,7 @@ It gives you the ability to automatically identify processes, collect and store
|
|||
|
||||
[Netdata Cloud](https://www.netdata.cloud) is a hosted web interface that gives you **Free**, real-time visibility into your **Entire Infrastructure** with secure access to your Netdata Agents. It provides an ability to automatically route your requests to the most relevant agents to display your metrics, based on the stored metadata (Agents topology, what metrics are collected on specific Agents as well as the retention information for each metric).
|
||||
|
||||
It gives you some extra features, like [Metric Correlations](https://learn.netdata.cloud/docs/cloud/insights/metric-correlations), [Anomaly Advisor](https://learn.netdata.cloud/docs/cloud/insights/anomaly-advisor), [anomaly rates on every chart](https://blog.netdata.cloud/anomaly-rate-in-every-chart/) and much more.
|
||||
It gives you some extra features, like [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md), [Anomaly Advisor](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.mdx), [anomaly rates on every chart](https://blog.netdata.cloud/anomaly-rate-in-every-chart/) and much more.
|
||||
|
||||
Try it for yourself right now by checking out the Netdata Cloud [demo space](https://app.netdata.cloud/spaces/netdata-demo/rooms/all-nodes/overview) (No sign up or login needed).
|
||||
|
||||
|
|
@ -77,7 +77,7 @@ Here's what you can expect from Netdata:
|
|||
synchronize charts as you pan through time, zoom in on anomalies, and more.
|
||||
- **Visual anomaly detection**: Our UI/UX emphasizes the relationships between charts to help you detect the root
|
||||
cause of anomalies.
|
||||
- **Machine learning (ML) features out of the box**: Unsupervised ML-based [anomaly detection](https://learn.netdata.cloud/docs/cloud/insights/anomaly-advisor), every second, every metric, zero-config! [Metric correlations](https://learn.netdata.cloud/docs/cloud/insights/metric-correlations) to help with short-term change detection. And other [additional](https://learn.netdata.cloud/guides/monitor/anomaly-detection) ML-based features to help make your life easier.
|
||||
- **Machine learning (ML) features out of the box**: Unsupervised ML-based [anomaly detection](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.mdx), every second, every metric, zero-config! [Metric correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md) to help with short-term change detection. And other [additional](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection.md) ML-based features to help make your life easier.
|
||||
- **Scales to infinity**: You can install it on all your servers, containers, VMs, and IoT devices. Metrics are not
|
||||
centralized by default, so there is no limit.
|
||||
- **Several operating modes**: Autonomous host monitoring (the default), headless data collector, forwarding proxy,
|
||||
|
|
@ -88,17 +88,17 @@ Netdata works with tons of applications, notifications platforms, and other time
|
|||
|
||||
- **300+ system, container, and application endpoints**: Collectors autodetect metrics from default endpoints and
|
||||
immediately visualize them into meaningful charts designed for troubleshooting. See [everything we
|
||||
support](https://learn.netdata.cloud/docs/agent/collectors/collectors).
|
||||
support](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md).
|
||||
- **20+ notification platforms**: Netdata's health watchdog sends warning and critical alarms to your [favorite
|
||||
platform](https://learn.netdata.cloud/docs/monitor/enable-notifications) to inform you of anomalies just seconds
|
||||
platform](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md) to inform you of anomalies just seconds
|
||||
after they affect your node.
|
||||
- **30+ external time-series databases**: Export resampled metrics as they're collected to other [local- and
|
||||
Cloud-based databases](https://learn.netdata.cloud/docs/export/external-databases) for best-in-class
|
||||
Cloud-based databases](https://github.com/netdata/netdata/blob/master/docs/export/external-databases.md) for best-in-class
|
||||
interoperability.
|
||||
|
||||
> 💡 **Want to leverage the monitoring power of Netdata across entire infrastructure**? View metrics from
|
||||
> any number of distributed nodes in a single interface and unlock even more
|
||||
> [features](https://learn.netdata.cloud/docs/overview/why-netdata) with [Netdata
|
||||
> [features](https://github.com/netdata/netdata/blob/master/docs/overview/why-netdata.md) with [Netdata
|
||||
> Cloud](https://learn.netdata.cloud/docs/overview/what-is-netdata#netdata-cloud).
|
||||
|
||||
## Get Netdata
|
||||
|
|
@ -117,7 +117,7 @@ Netdata works with tons of applications, notifications platforms, and other time
|
|||
|
||||
### Infrastructure view
|
||||
|
||||
Due to the distributed nature of the Netdata ecosystem, it is recommended to setup not only one Netdata Agent on your production system, but also an additional Netdata Agent acting as a [Parent](https://learn.netdata.cloud/docs/agent/streaming). A local Netdata Agent (child), without any database or alarms, collects metrics and sends them to another Netdata Agent (parent). The same parent can collect data for any number of child nodes and serves as a centralized health check engine for each child by triggering alerts on their behalf.
|
||||
Due to the distributed nature of the Netdata ecosystem, it is recommended to setup not only one Netdata Agent on your production system, but also an additional Netdata Agent acting as a [Parent](https://github.com/netdata/netdata/blob/master/streaming/README.md). A local Netdata Agent (child), without any database or alarms, collects metrics and sends them to another Netdata Agent (parent). The same parent can collect data for any number of child nodes and serves as a centralized health check engine for each child by triggering alerts on their behalf.
|
||||
|
||||

|
||||
|
||||
|
|
@ -127,7 +127,7 @@ Community version is free to use forever. No restriction on number of nodes, clu
|
|||
|
||||
#### Claiming existing Agents
|
||||
|
||||
You can easily [connect (claim)](https://learn.netdata.cloud/docs/agent/claim) your existing Agents to the Cloud to unlock features for free and to find weaknesses before they turn into outages.
|
||||
You can easily [connect (claim)](https://github.com/netdata/netdata/blob/master/claim/README.md) your existing Agents to the Cloud to unlock features for free and to find weaknesses before they turn into outages.
|
||||
|
||||
### Single Node view
|
||||
|
||||
|
|
@ -138,7 +138,7 @@ installation script](https://learn.netdata.cloud/docs/agent/packaging/installer/
|
|||
and builds all dependencies, including those required to connect to [Netdata Cloud](https://netdata.cloud/cloud) if you
|
||||
choose, and enables [automatic nightly
|
||||
updates](https://learn.netdata.cloud/docs/agent/packaging/installer#nightly-vs-stable-releases) and [anonymous
|
||||
statistics](https://learn.netdata.cloud/docs/agent/anonymous-statistics).
|
||||
statistics](https://github.com/netdata/netdata/blob/master/docs/anonymous-statistics.md).
|
||||
<!-- candidate for reuse -->
|
||||
```bash
|
||||
wget -O /tmp/netdata-kickstart.sh https://my-netdata.io/kickstart.sh && sh /tmp/netdata-kickstart.sh
|
||||
|
|
@ -149,7 +149,7 @@ To view the Netdata dashboard, navigate to `http://localhost:19999`, or `http://
|
|||
### Docker
|
||||
|
||||
You can also try out Netdata's capabilities in a [Docker
|
||||
container](https://learn.netdata.cloud/docs/agent/packaging/docker/):
|
||||
container](https://github.com/netdata/netdata/blob/master/packaging/docker/README.md):
|
||||
|
||||
```bash
|
||||
docker run -d --name=netdata \
|
||||
|
|
@ -173,16 +173,16 @@ To view the Netdata dashboard, navigate to `http://localhost:19999`, or `http://
|
|||
### Other operating systems
|
||||
|
||||
See our documentation for [additional operating
|
||||
systems](/packaging/installer/README.md#have-a-different-operating-system-or-want-to-try-another-method), including
|
||||
[Kubernetes](/packaging/installer/methods/kubernetes.md), [`.deb`/`.rpm`
|
||||
packages](/packaging/installer/methods/kickstart.md#native-packages), and more.
|
||||
systems](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md#have-a-different-operating-system-or-want-to-try-another-method), including
|
||||
[Kubernetes](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/kubernetes.md), [`.deb`/`.rpm`
|
||||
packages](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/kickstart.md#native-packages), and more.
|
||||
|
||||
### Post-installation
|
||||
|
||||
When you're finished with installation, check out our [single-node](/docs/quickstart/single-node.md) or
|
||||
[infrastructure](/docs/quickstart/infrastructure.md) monitoring quickstart guides based on your use case.
|
||||
When you're finished with installation, check out our [single-node](https://github.com/netdata/netdata/blob/master/docs/quickstart/single-node.md) or
|
||||
[infrastructure](https://github.com/netdata/netdata/blob/master/docs/quickstart/infrastructure.md) monitoring quickstart guides based on your use case.
|
||||
|
||||
Or, skip straight to [configuring the Netdata Agent](/docs/configure/nodes.md).
|
||||
Or, skip straight to [configuring the Netdata Agent](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md).
|
||||
|
||||
Read through Netdata's [documentation](https://learn.netdata.cloud/docs), which is structured based on actions and
|
||||
solutions, to enable features like health monitoring, alarm notifications, long-term metrics storage, exporting to
|
||||
|
|
@ -215,7 +215,7 @@ to collect metrics, troubleshoot via charts, export to external databases, and m
|
|||
|
||||
## Community
|
||||
|
||||
Netdata is an inclusive open-source project and community. Please read our [Code of Conduct](https://learn.netdata.cloud/contribute/code-of-conduct).
|
||||
Netdata is an inclusive open-source project and community. Please read our [Code of Conduct](https://github.com/netdata/.github/blob/main/CODE_OF_CONDUCT.md).
|
||||
|
||||
Find most of the Netdata team in our [community forums](https://community.netdata.cloud). It's the best place to
|
||||
ask questions, find resources, and engage with passionate professionals. The team is also available and active in our [Discord](https://discord.com/invite/mPZ6WZKKG2) too.
|
||||
|
|
@ -235,18 +235,18 @@ You can also find Netdata on:
|
|||
|
||||
Contributions are the lifeblood of open-source projects. While we continue to invest in and improve Netdata, we need help to democratize monitoring!
|
||||
|
||||
- Read our [Contributing Guide](https://learn.netdata.cloud/contribute/handbook), which contains all the information you need to contribute to Netdata, such as improving our documentation, engaging in the community, and developing new features. We've made it as frictionless as possible, but if you need help, just ping us on our community forums!
|
||||
- Read our [Contributing Guide](https://github.com/netdata/.github/blob/main/CONTRIBUTING.md), which contains all the information you need to contribute to Netdata, such as improving our documentation, engaging in the community, and developing new features. We've made it as frictionless as possible, but if you need help, just ping us on our community forums!
|
||||
- We have a whole category dedicated to contributing and extending Netdata on our [community forums](https://community.netdata.cloud/c/agent-development/9)
|
||||
- Found a bug? Open a [GitHub issue](https://github.com/netdata/netdata/issues/new?assignees=&labels=bug%2Cneeds+triage&template=BUG_REPORT.yml&title=%5BBug%5D%3A+).
|
||||
- View our [Security Policy](https://github.com/netdata/netdata/security/policy).
|
||||
|
||||
Package maintainers should read the guide on [building Netdata from source](/packaging/installer/methods/source.md) for
|
||||
Package maintainers should read the guide on [building Netdata from source](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/source.md) for
|
||||
instructions on building each Netdata component from source and preparing a package.
|
||||
|
||||
## License
|
||||
|
||||
The Netdata Agent is [GPLv3+](/LICENSE). Netdata re-distributes other open-source tools and libraries. Please check the
|
||||
[third party licenses](/REDISTRIBUTED.md).
|
||||
The Netdata Agent is [GPLv3+](https://github.com/netdata/netdata/blob/master/LICENSE). Netdata re-distributes other open-source tools and libraries. Please check the
|
||||
[third party licenses](https://github.com/netdata/netdata/blob/master/REDISTRIBUTED.md).
|
||||
|
||||
## Is it any good?
|
||||
|
||||
|
|
|
|||
|
|
@ -29,8 +29,8 @@ this is not an option in your case always verify the current domain resolution (
|
|||
:::
|
||||
|
||||
For a guide to connecting a node using the ACLK, plus additional troubleshooting and reference information, read our [get
|
||||
started with Cloud](https://learn.netdata.cloud/docs/cloud/get-started) guide or the full [connect to Cloud
|
||||
documentation](/claim/README.md).
|
||||
started with Cloud](https://github.com/netdata/netdata/blob/master/docs/cloud/get-started.mdx) guide or the full [connect to Cloud
|
||||
documentation](https://github.com/netdata/netdata/blob/master/claim/README.md).
|
||||
|
||||
## Data privacy
|
||||
[Data privacy](https://netdata.cloud/privacy/) is very important to us. We firmly believe that your data belongs to
|
||||
|
|
@ -41,7 +41,7 @@ The data passes through our systems, but it isn't stored.
|
|||
|
||||
However, to be able to offer the stunning visualizations and advanced functionality of Netdata Cloud, it does store a limited number of _metadata_.
|
||||
|
||||
Read more about [Data privacy in the Netdata Cloud](https://learn.netdata.cloud/docs/cloud/data-privacy) in the documentation.
|
||||
Read more about [Data privacy in the Netdata Cloud](https://github.com/netdata/netdata/blob/master/docs/cloud/data-privacy.mdx) in the documentation.
|
||||
|
||||
|
||||
## Enable and configure the ACLK
|
||||
|
|
@ -57,7 +57,7 @@ configuration uses two settings:
|
|||
```
|
||||
|
||||
If your Agent needs to use a proxy to access the internet, you must [set up a proxy for
|
||||
connecting to cloud](/claim/README.md#connect-through-a-proxy).
|
||||
connecting to cloud](https://github.com/netdata/netdata/blob/master/claim/README.md#connect-through-a-proxy).
|
||||
|
||||
You can configure following keys in the `netdata.conf` section `[cloud]`:
|
||||
```
|
||||
|
|
@ -76,8 +76,8 @@ You have two options if you prefer to disable the ACLK and not use Netdata Cloud
|
|||
### Disable at installation
|
||||
|
||||
You can pass the `--disable-cloud` parameter to the Agent installation when using a kickstart script
|
||||
([kickstart.sh](/packaging/installer/methods/kickstart.md), or a [manual installation from
|
||||
Git](/packaging/installer/methods/manual.md).
|
||||
([kickstart.sh](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/kickstart.md), or a [manual installation from
|
||||
Git](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/manual.md).
|
||||
|
||||
When you pass this parameter, the installer does not download or compile any extra libraries. Once running, the Agent
|
||||
kills the thread responsible for the ACLK and connecting behavior, and behaves as though the ACLK, and thus Netdata Cloud,
|
||||
|
|
@ -131,12 +131,12 @@ Restart your Agent to disable the ACLK.
|
|||
### Re-enable the ACLK
|
||||
|
||||
If you first disable the ACLK and any Cloud functionality and then decide you would like to use Cloud, you must either
|
||||
[reinstall Netdata](/packaging/installer/REINSTALL.md) with Cloud enabled or change the runtime setting in your
|
||||
[reinstall Netdata](https://github.com/netdata/netdata/blob/master/packaging/installer/REINSTALL.md) with Cloud enabled or change the runtime setting in your
|
||||
`cloud.conf` file.
|
||||
|
||||
If you passed `--disable-cloud` to `netdata-installer.sh` during installation, you must
|
||||
[reinstall](/packaging/installer/REINSTALL.md) your Agent. Use the same method as before, but pass `--require-cloud` to
|
||||
the installer. When installation finishes you can [connect your node](/claim/README.md#how-to-connect-a-node).
|
||||
[reinstall](https://github.com/netdata/netdata/blob/master/packaging/installer/REINSTALL.md) your Agent. Use the same method as before, but pass `--require-cloud` to
|
||||
the installer. When installation finishes you can [connect your node](https://github.com/netdata/netdata/blob/master/claim/README.md#how-to-connect-a-node).
|
||||
|
||||
If you changed the runtime setting in your `var/lib/netdata/cloud.d/cloud.conf` file, edit the file again and change
|
||||
`enabled` to `yes`:
|
||||
|
|
@ -146,6 +146,6 @@ If you changed the runtime setting in your `var/lib/netdata/cloud.d/cloud.conf`
|
|||
enabled = yes
|
||||
```
|
||||
|
||||
Restart your Agent and [connect your node](/claim/README.md#how-to-connect-a-node).
|
||||
Restart your Agent and [connect your node](https://github.com/netdata/netdata/blob/master/claim/README.md#how-to-connect-a-node).
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -12,10 +12,10 @@ learn_rel_path: "Setup"
|
|||
|
||||
You can securely connect a Netdata Agent, running on a distributed node, to Netdata Cloud. A Space's
|
||||
administrator creates a **claiming token**, which is used to add an Agent to their Space via the [Agent-Cloud link
|
||||
(ACLK)](/aclk/README.md).
|
||||
(ACLK)](https://github.com/netdata/netdata/blob/master/aclk/README.md).
|
||||
|
||||
Are you just starting out with Netdata Cloud? See our [get started with
|
||||
Cloud](https://learn.netdata.cloud/docs/cloud/get-started) guide for a walkthrough of the process and simplified
|
||||
Cloud](https://github.com/netdata/netdata/blob/master/docs/cloud/cloud.mdx) guide for a walkthrough of the process and simplified
|
||||
instructions.
|
||||
|
||||
When connecting an agent (also referred to as a node) to Netdata Cloud, you must complete a verification process that proves you have some level of authorization to manage the node itself. This verification is a security feature that helps prevent unauthorized users from seeing the data on your node.
|
||||
|
|
@ -26,13 +26,13 @@ Netdata Cloud.
|
|||
> The connection process ensures no third party can add your node, and then view your node's metrics, in a Cloud account,
|
||||
> Space, or War Room that you did not authorize.
|
||||
|
||||
By connecting a node, you opt-in to sending data from your Agent to Netdata Cloud via the [ACLK](/aclk/README.md). This
|
||||
By connecting a node, you opt-in to sending data from your Agent to Netdata Cloud via the [ACLK](https://github.com/netdata/netdata/blob/master/aclk/README.md). This
|
||||
data is encrypted by TLS while it is in transit. We use the RSA keypair created during the connection process to authenticate the
|
||||
identity of the Netdata Agent when it connects to the Cloud. While the data does flow through Netdata Cloud servers on its way
|
||||
from Agents to the browser, we do not store or log it.
|
||||
|
||||
You can connect a node during the Netdata Cloud onboarding process, or after you created a Space by clicking on **Connect
|
||||
Nodes** in the [Spaces management area](https://learn.netdata.cloud/docs/cloud/spaces#manage-spaces).
|
||||
Nodes** in the [Spaces management area](https://github.com/netdata/netdata/blob/master/docs/cloud/cloud.mdx#manage-spaces).
|
||||
|
||||
There are two important notes regarding connecting nodes:
|
||||
|
||||
|
|
@ -46,7 +46,7 @@ There will be three main flows from where you might want to connect a node to Ne
|
|||
* when you are on an [
|
||||
War Room](#empty-war-room) and you want to connect your first node
|
||||
* when you are at the [Manage Space](#manage-space-or-war-room) area and you select **Connect Nodes** to connect a node, coming from Manage Space or Manage War Room
|
||||
* when you are on the [Nodes view page](https://learn.netdata.cloud/docs/cloud/visualize/nodes) and want to connect a node - this process falls into the [Manage Space](#manage-space-or-war-room) flow
|
||||
* when you are on the [Nodes view page](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/nodes.md) and want to connect a node - this process falls into the [Manage Space](#manage-space-or-war-room) flow
|
||||
|
||||
Please note that only the administrators of a Space in Netdata Cloud can view the claiming token and accompanying script, generated by Netdata Cloud, to trigger the connection process.
|
||||
|
||||
|
|
@ -70,11 +70,11 @@ finished onboarding.
|
|||
To connect a node, select which War Rooms you want to add this node to with the dropdown, then copy and paste the script
|
||||
given by Netdata Cloud into your node's terminal.
|
||||
|
||||
When coming from [Nodes view page](https://learn.netdata.cloud/docs/cloud/visualize/nodes) the room parameter is already defined to current War Room.
|
||||
When coming from [Nodes view page](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/nodes.md) the room parameter is already defined to current War Room.
|
||||
|
||||
### Connect an agent running in Linux
|
||||
|
||||
If you want to connect a node that is running on a Linux environment, the script that will be provided to you by Netdata Cloud is the [kickstart](/packaging/installer/README.md#automatic-one-line-installation-script) which will install the Netdata Agent on your node, if it isn't already installed, and connect the node to Netdata Cloud. It should be similar to:
|
||||
If you want to connect a node that is running on a Linux environment, the script that will be provided to you by Netdata Cloud is the [kickstart](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md#automatic-one-line-installation-script) which will install the Netdata Agent on your node, if it isn't already installed, and connect the node to Netdata Cloud. It should be similar to:
|
||||
|
||||
```
|
||||
wget -O /tmp/netdata-kickstart.sh https://my-netdata.io/kickstart.sh && sh /tmp/netdata-kickstart.sh --claim-token TOKEN --claim-rooms ROOM1,ROOM2 --claim-url https://api.netdata.cloud
|
||||
|
|
@ -84,7 +84,7 @@ the node in your Space after 60 seconds, see the [troubleshooting information](#
|
|||
|
||||
Please note that to run it you will either need to have root privileges or run it with the user that is running the agent, more details on the [Connect an agent without root privileges](#connect-an-agent-without-root-privileges) section.
|
||||
|
||||
For more details on what are the extra parameters `claim-token`, `claim-rooms` and `claim-url` please refer to [Connect node to Netdata Cloud during installation](/packaging/installer/methods/kickstart.md#connect-node-to-netdata-cloud-during-installation).
|
||||
For more details on what are the extra parameters `claim-token`, `claim-rooms` and `claim-url` please refer to [Connect node to Netdata Cloud during installation](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/kickstart.md#connect-node-to-netdata-cloud-during-installation).
|
||||
|
||||
### Connect an agent without root privileges
|
||||
|
||||
|
|
@ -118,7 +118,7 @@ connected on startup or restart.
|
|||
|
||||
For the connection process to work, the contents of `/var/lib/netdata` _must_ be preserved across container
|
||||
restarts using a persistent volume. See our [recommended `docker run` and Docker Compose
|
||||
examples](/packaging/docker/README.md#create-a-new-netdata-agent-container) for details.
|
||||
examples](https://github.com/netdata/netdata/blob/master/packaging/docker/README.md#create-a-new-netdata-agent-container) for details.
|
||||
|
||||
#### Known issues on older hosts with seccomp enabled
|
||||
|
||||
|
|
@ -289,7 +289,7 @@ you don't see the node in your Space after 60 seconds, see the [troubleshooting
|
|||
|
||||
### Connect an agent running in macOS
|
||||
|
||||
To connect a node that is running on a macOS environment the script that will be provided to you by Netdata Cloud is the [kickstart](/packaging/installer/methods/macos.md#install-netdata-with-our-automatic-one-line-installation-script) which will install the Netdata Agent on your node, if it isn't already installed, and connect the node to Netdata Cloud. It should be similar to:
|
||||
To connect a node that is running on a macOS environment the script that will be provided to you by Netdata Cloud is the [kickstart](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/macos.md#install-netdata-with-our-automatic-one-line-installation-script) which will install the Netdata Agent on your node, if it isn't already installed, and connect the node to Netdata Cloud. It should be similar to:
|
||||
|
||||
```bash
|
||||
curl https://my-netdata.io/kickstart.sh > /tmp/netdata-kickstart.sh && sh /tmp/netdata-kickstart.sh --install-prefix /usr/local/ --claim-token TOKEN --claim-rooms ROOM1,ROOM2 --claim-url https://api.netdata.cloud
|
||||
|
|
@ -299,7 +299,7 @@ the node in your Space after 60 seconds, see the [troubleshooting information](#
|
|||
|
||||
### Connect a Kubernetes cluster's parent Netdata pod
|
||||
|
||||
Read our [Kubernetes installation](/packaging/installer/methods/kubernetes.md#connect-your-kubernetes-cluster-to-netdata-cloud)
|
||||
Read our [Kubernetes installation](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/kubernetes.md#connect-your-kubernetes-cluster-to-netdata-cloud)
|
||||
for details on connecting a parent Netdata pod.
|
||||
|
||||
### Connect through a proxy
|
||||
|
|
@ -328,7 +328,7 @@ For example, a HTTP proxy setting may look like the following:
|
|||
proxy = http://proxy.example.com:1080 # With a URL
|
||||
```
|
||||
|
||||
You can now move on to connecting. When you connect with the [kickstart](/packaging/installer/README.md#automatic-one-line-installation-script) script, add the `--claim-proxy=` parameter and
|
||||
You can now move on to connecting. When you connect with the [kickstart](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md#automatic-one-line-installation-script) script, add the `--claim-proxy=` parameter and
|
||||
append the same proxy setting you added to `netdata.conf`.
|
||||
|
||||
```bash
|
||||
|
|
@ -340,7 +340,7 @@ you don't see the node in your Space after 60 seconds, see the [troubleshooting
|
|||
|
||||
### Troubleshooting
|
||||
|
||||
If you're having trouble connecting a node, this may be because the [ACLK](/aclk/README.md) cannot connect to Cloud.
|
||||
If you're having trouble connecting a node, this may be because the [ACLK](https://github.com/netdata/netdata/blob/master/aclk/README.md) cannot connect to Cloud.
|
||||
|
||||
With the Netdata Agent running, visit `http://NODE:19999/api/v1/info` in your browser, replacing `NODE` with the IP
|
||||
address or hostname of your Agent. The returned JSON contains four keys that will be helpful to diagnose any issues you
|
||||
|
|
@ -373,7 +373,7 @@ If you run the kickstart script and get the following error `Existing install ap
|
|||
|
||||
If you are using an unsupported package, such as a third-party `.deb`/`.rpm` package provided by your distribution,
|
||||
please remove that package and reinstall using our [recommended kickstart
|
||||
script](/docs/get-started.mdx#install-on-linux-with-one-line-installer).
|
||||
script](https://github.com/netdata/netdata/blob/master/docs/get-started.mdx#install-on-linux-with-one-line-installer).
|
||||
|
||||
#### kickstart: Failed to write new machine GUID
|
||||
|
||||
|
|
@ -393,7 +393,7 @@ if you installed Netdata to `/opt/netdata`, use `/opt/netdata/bin/netdata-claim.
|
|||
|
||||
If you are using an unsupported package, such as a third-party `.deb`/`.rpm` package provided by your distribution,
|
||||
please remove that package and reinstall using our [recommended kickstart
|
||||
script](/docs/get-started.mdx#install-on-linux-with-one-line-installer).
|
||||
script](https://github.com/netdata/netdata/blob/master/docs/get-started.mdx#install-on-linux-with-one-line-installer).
|
||||
|
||||
#### Connecting on older distributions (Ubuntu 14.04, Debian 8, CentOS 6)
|
||||
|
||||
|
|
@ -402,7 +402,7 @@ If you're running an older Linux distribution or one that has reached EOL, such
|
|||
versions of OpenSSL cannot perform [hostname validation](https://wiki.openssl.org/index.php/Hostname_validation), which
|
||||
helps securely encrypt SSL connections.
|
||||
|
||||
We recommend you reinstall Netdata with a [static build](/packaging/installer/methods/kickstart.md#static-builds), which uses an
|
||||
We recommend you reinstall Netdata with a [static build](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/kickstart.md#static-builds), which uses an
|
||||
up-to-date version of OpenSSL with hostname validation enabled.
|
||||
|
||||
If you choose to continue using the outdated version of OpenSSL, your node will still connect to Netdata Cloud, albeit
|
||||
|
|
@ -420,7 +420,7 @@ Additionally, check that the `enabled` setting in `var/lib/netdata/cloud.d/cloud
|
|||
enabled = true
|
||||
```
|
||||
|
||||
To fix this issue, reinstall Netdata using your [preferred method](/packaging/installer/README.md) and do not add the
|
||||
To fix this issue, reinstall Netdata using your [preferred method](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md) and do not add the
|
||||
`--disable-cloud` option.
|
||||
|
||||
#### cloud-available is false / ACLK Available: No
|
||||
|
|
@ -510,20 +510,20 @@ tool, and details about the files found in `cloud.d`.
|
|||
|
||||
### The `cloud.conf` file
|
||||
|
||||
This section defines how and whether your Agent connects to [Netdata Cloud](https://learn.netdata.cloud/docs/cloud/)
|
||||
using the [ACLK](/aclk/README.md).
|
||||
This section defines how and whether your Agent connects to [Netdata Cloud](https://github.com/netdata/netdata/blob/master/docs/cloud/cloud.mdx)
|
||||
using the [ACLK](https://github.com/netdata/netdata/blob/master/aclk/README.md).
|
||||
|
||||
| setting | default | info |
|
||||
|:-------------- |:------------------------- |:-------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| cloud base url | https://api.netdata.cloud | The URL for the Netdata Cloud web application. You should not change this. If you want to disable Cloud, change the `enabled` setting. |
|
||||
| enabled | yes | The runtime option to disable the [Agent-Cloud link](/aclk/README.md) and prevent your Agent from connecting to Netdata Cloud. |
|
||||
| enabled | yes | The runtime option to disable the [Agent-Cloud link](https://github.com/netdata/netdata/blob/master/aclk/README.md) and prevent your Agent from connecting to Netdata Cloud. |
|
||||
|
||||
### kickstart script
|
||||
|
||||
The best way to install Netdata and connect your nodes to Netdata Cloud is with our automatic one-line installation script, [kickstart](/packaging/installer/README.md#automatic-one-line-installation-script). This script will install the Netdata Agent, in case it isn't already installed, and connect your node to Netdata Cloud.
|
||||
The best way to install Netdata and connect your nodes to Netdata Cloud is with our automatic one-line installation script, [kickstart](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md#automatic-one-line-installation-script). This script will install the Netdata Agent, in case it isn't already installed, and connect your node to Netdata Cloud.
|
||||
|
||||
This works with:
|
||||
* most Linux distributions, see [Netdata's platform support policy](/packaging/PLATFORM_SUPPORT.md)
|
||||
* most Linux distributions, see [Netdata's platform support policy](https://github.com/netdata/netdata/blob/master/packaging/PLATFORM_SUPPORT.md)
|
||||
* macOS
|
||||
|
||||
For details on how to run this script please check [How to connect a node](#how-to-connect-a-node) and choose your environment.
|
||||
|
|
@ -578,7 +578,7 @@ netdatacli reload-claiming-state
|
|||
|
||||
This reloads the Agent connection state from disk.
|
||||
|
||||
Our recommendation is to trigger the connection process using the [kickstart](/packaging/installer/README.md#automatic-one-line-installation-script) whenever possible.
|
||||
Our recommendation is to trigger the connection process using the [kickstart](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md#automatic-one-line-installation-script) whenever possible.
|
||||
|
||||
### Netdata Agent command line
|
||||
|
||||
|
|
|
|||
|
|
@ -39,6 +39,6 @@ aclk-state [json]
|
|||
Returns current state of ACLK and Cloud connection. (optionally in json)
|
||||
```
|
||||
|
||||
Those commands are the same that can be sent to netdata via [signals](/daemon/README.md#command-line-options).
|
||||
Those commands are the same that can be sent to netdata via [signals](https://github.com/netdata/netdata/blob/master/daemon/README.md#command-line-options).
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -14,16 +14,19 @@ Netdata uses collectors to help you gather metrics from your favorite applicatio
|
|||
real-time, interactive charts. The following list includes collectors for both external services/applications and
|
||||
internal system metrics.
|
||||
|
||||
Learn more about [how collectors work](/docs/collect/how-collectors-work.md), and then learn how to [enable or
|
||||
configure](/docs/collect/enable-configure.md) any of the below collectors using the same process.
|
||||
Learn more
|
||||
about [how collectors work](https://github.com/netdata/netdata/blob/master/docs/collect/how-collectors-work.md), and
|
||||
then learn how to [enable or
|
||||
configure](https://github.com/netdata/netdata/blob/master/docs/collect/enable-configure.md) any of the below collectors using the same process.
|
||||
|
||||
Some collectors have both Go and Python versions as we continue our effort to migrate all collectors to Go. In these
|
||||
cases, _Netdata always prioritizes the Go version_, and we highly recommend you use the Go versions for the best
|
||||
experience.
|
||||
|
||||
If you want to use a Python version of a collector, you need to explicitly [disable the Go
|
||||
version](/docs/collect/enable-configure.md), and enable the Python version. Netdata then skips the Go version and
|
||||
attempts to load the Python version and its accompanying configuration file.
|
||||
If you want to use a Python version of a collector, you need to
|
||||
explicitly [disable the Go version](https://github.com/netdata/netdata/blob/masterhttps://github.com/netdata/netdata/blob/master/docs/collect/enable-configure.md),
|
||||
and enable the Python version. Netdata then skips the Go version and attempts to load the Python version and its
|
||||
accompanying configuration file.
|
||||
|
||||
If you don't see the app/service you'd like to monitor in this list:
|
||||
|
||||
|
|
@ -33,7 +36,7 @@ If you don't see the app/service you'd like to monitor in this list:
|
|||
a [feature request](https://github.com/netdata/netdata/issues/new/choose) on GitHub.
|
||||
- If you have basic software development skills, you can add your own plugin
|
||||
in [Go](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin#how-to-develop-a-collector)
|
||||
or [Python](https://learn.netdata.cloud/guides/python-collector)
|
||||
or [Python](https://github.com/netdata/netdata/blob/master/docs/guides/python-collector.md)
|
||||
|
||||
Supported Collectors List:
|
||||
|
||||
|
|
@ -76,256 +79,300 @@ configure any of these collectors according to your setup and infrastructure.
|
|||
|
||||
### Generic
|
||||
|
||||
- [Prometheus endpoints](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/prometheus): Gathers
|
||||
- [Prometheus endpoints](https://github.com/netdata/go.d.plugin/blob/master/modules/prometheus/README.md): Gathers
|
||||
metrics from any number of Prometheus endpoints, with support to autodetect more than 600 services and applications.
|
||||
- [Pandas](https://learn.netdata.cloud/docs/agent/collectors/python.d.plugin/pandas): A Python collector that gathers
|
||||
metrics from a [pandas](https://pandas.pydata.org/) dataframe. Pandas is a high level data processing library in
|
||||
Python that can read various formats of data from local files or web endpoints. Custom processing and transformation
|
||||
- [Pandas](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/pandas/README.md): A Python
|
||||
collector that gathers
|
||||
metrics from a [pandas](https://pandas.pydata.org/) dataframe. Pandas is a high level data processing library in
|
||||
Python that can read various formats of data from local files or web endpoints. Custom processing and transformation
|
||||
logic can also be expressed as part of the collector configuration.
|
||||
|
||||
### APM (application performance monitoring)
|
||||
|
||||
- [Go applications](/collectors/python.d.plugin/go_expvar/README.md): Monitor any Go application that exposes its
|
||||
- [Go applications](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/go_expvar/README.md):
|
||||
Monitor any Go application that exposes its
|
||||
metrics with the `expvar` package from the Go standard library.
|
||||
- [Java Spring Boot 2
|
||||
applications](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/springboot2/):
|
||||
- [Java Spring Boot 2 applications](https://github.com/netdata/go.d.plugin/blob/master/modules/springboot2/README.md):
|
||||
Monitor running Java Spring Boot 2 applications that expose their metrics with the use of the Spring Boot Actuator.
|
||||
- [statsd](/collectors/statsd.plugin/README.md): Implement a high performance `statsd` server for Netdata.
|
||||
- [phpDaemon](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/phpdaemon/): Collect worker
|
||||
- [statsd](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/README.md): Implement a high
|
||||
performance `statsd` server for Netdata.
|
||||
- [phpDaemon](https://github.com/netdata/go.d.plugin/blob/master/modules/phpdaemon/README.md): Collect worker
|
||||
statistics (total, active, idle), and uptime for web and network applications.
|
||||
- [uWSGI](/collectors/python.d.plugin/uwsgi/README.md): Monitor performance metrics exposed by the uWSGI Stats
|
||||
- [uWSGI](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/uwsgi/README.md): Monitor
|
||||
performance metrics exposed by the uWSGI Stats
|
||||
Server.
|
||||
|
||||
### Containers and VMs
|
||||
|
||||
- [Docker containers](/collectors/cgroups.plugin/README.md): Monitor the health and performance of individual Docker
|
||||
containers using the cgroups collector plugin.
|
||||
- [DockerD](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/docker/): Collect container health statistics.
|
||||
- [Docker Engine](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/docker_engine/): Collect
|
||||
- [Docker containers](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md): Monitor the
|
||||
health and performance of individual Docker containers using the cgroups collector plugin.
|
||||
- [DockerD](https://github.com/netdata/go.d.plugin/blob/master/modules/docker/README.md): Collect container health
|
||||
statistics.
|
||||
- [Docker Engine](https://github.com/netdata/go.d.plugin/blob/master/modules/docker_engine/README.md): Collect
|
||||
runtime statistics from the `docker` daemon using the `metrics-address` feature.
|
||||
- [Docker Hub](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/dockerhub/): Collect statistics
|
||||
- [Docker Hub](https://github.com/netdata/go.d.plugin/blob/master/modules/dockerhub/README.md): Collect statistics
|
||||
about Docker repositories, such as pulls, starts, status, time since last update, and more.
|
||||
- [Libvirt](/collectors/cgroups.plugin/README.md): Monitor the health and performance of individual Libvirt containers
|
||||
- [Libvirt](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md): Monitor the health and
|
||||
performance of individual Libvirt containers
|
||||
using the cgroups collector plugin.
|
||||
- [LXC](/collectors/cgroups.plugin/README.md): Monitor the health and performance of individual LXC containers using
|
||||
- [LXC](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md): Monitor the health and
|
||||
performance of individual LXC containers using
|
||||
the cgroups collector plugin.
|
||||
- [LXD](/collectors/cgroups.plugin/README.md): Monitor the health and performance of individual LXD containers using
|
||||
- [LXD](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md): Monitor the health and
|
||||
performance of individual LXD containers using
|
||||
the cgroups collector plugin.
|
||||
- [systemd-nspawn](/collectors/cgroups.plugin/README.md): Monitor the health and performance of individual
|
||||
- [systemd-nspawn](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md): Monitor the
|
||||
health and performance of individual
|
||||
systemd-nspawn containers using the cgroups collector plugin.
|
||||
- [vCenter Server Appliance](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/vcsa/): Monitor
|
||||
- [vCenter Server Appliance](https://github.com/netdata/go.d.plugin/blob/master/modules/vcsa/README.md): Monitor
|
||||
appliance system, components, and software update health statuses via the Health API.
|
||||
- [vSphere](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/vsphere/): Collect host and virtual
|
||||
- [vSphere](https://github.com/netdata/go.d.plugin/blob/master/modules/vsphere/README.md): Collect host and virtual
|
||||
machine performance metrics.
|
||||
- [Xen/XCP-ng](/collectors/xenstat.plugin/README.md): Collect XenServer and XCP-ng metrics using `libxenstat`.
|
||||
- [Xen/XCP-ng](https://github.com/netdata/netdata/blob/master/collectors/xenstat.plugin/README.md): Collect XenServer
|
||||
and XCP-ng metrics using `libxenstat`.
|
||||
|
||||
### Data stores
|
||||
|
||||
- [CockroachDB](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/cockroachdb/): Monitor various
|
||||
- [CockroachDB](https://github.com/netdata/go.d.plugin/blob/master/modules/cockroachdb/README.md): Monitor various
|
||||
database components using `_status/vars` endpoint.
|
||||
- [Consul](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/consul/): Capture service and unbound
|
||||
- [Consul](https://github.com/netdata/go.d.plugin/blob/master/modules/consul/README.md): Capture service and unbound
|
||||
checks status (passing, warning, critical, maintenance).
|
||||
- [Couchbase](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/couchbase/): Gather per-bucket
|
||||
- [Couchbase](https://github.com/netdata/go.d.plugin/blob/master/modules/couchbase/README.md): Gather per-bucket
|
||||
metrics from any number of instances of the distributed JSON document database.
|
||||
- [CouchDB](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/couchdb): Monitor database health and
|
||||
- [CouchDB](https://github.com/netdata/go.d.plugin/blob/master/modules/couchdb/README.md): Monitor database health and
|
||||
performance metrics
|
||||
(reads/writes, HTTP traffic, replication status, etc).
|
||||
- [MongoDB](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/mongodb): Collect server, database,
|
||||
- [MongoDB](https://github.com/netdata/go.d.plugin/blob/master/modules/mongodb/README.md): Collect server, database,
|
||||
replication and sharding performance and health metrics.
|
||||
- [MySQL](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/mysql/): Collect database global,
|
||||
- [MySQL](https://github.com/netdata/go.d.plugin/blob/master/modules/mysql/README.md): Collect database global,
|
||||
replication and per user statistics.
|
||||
- [OracleDB](/collectors/python.d.plugin/oracledb/README.md): Monitor database performance and health metrics.
|
||||
- [Pika](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/pika/): Gather metric, such as clients,
|
||||
- [OracleDB](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/oracledb/README.md): Monitor
|
||||
database performance and health metrics.
|
||||
- [Pika](https://github.com/netdata/go.d.plugin/blob/master/modules/pika/README.md): Gather metric, such as clients,
|
||||
memory usage, queries, and more from the Redis interface-compatible database.
|
||||
- [Postgres](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/postgres): Collect database health
|
||||
- [Postgres](https://github.com/netdata/go.d.plugin/blob/master/modules/postgres/README.md): Collect database health
|
||||
and performance metrics.
|
||||
- [ProxySQL](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/proxysql): Monitor database backend
|
||||
- [ProxySQL](https://github.com/netdata/go.d.plugin/blob/master/modules/proxysql/README.md): Monitor database backend
|
||||
and frontend performance metrics.
|
||||
- [Redis](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/redis/): Monitor status from any
|
||||
- [Redis](https://github.com/netdata/go.d.plugin/blob/master/modules/redis/README.md): Monitor status from any
|
||||
number of database instances by reading the server's response to the `INFO ALL` command.
|
||||
- [RethinkDB](/collectors/python.d.plugin/rethinkdbs/README.md): Collect database server and cluster statistics.
|
||||
- [Riak KV](/collectors/python.d.plugin/riakkv/README.md): Collect database stats from the `/stats` endpoint.
|
||||
- [Zookeeper](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/zookeeper/): Monitor application
|
||||
- [RethinkDB](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/rethinkdbs/README.md): Collect
|
||||
database server and cluster statistics.
|
||||
- [Riak KV](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/riakkv/README.md): Collect
|
||||
database stats from the `/stats` endpoint.
|
||||
- [Zookeeper](https://github.com/netdata/go.d.plugin/blob/master/modules/zookeeper/README.md): Monitor application
|
||||
health metrics reading the server's response to the `mntr` command.
|
||||
- [Memcached](/collectors/python.d.plugin/memcached/README.md): Collect memory-caching system performance metrics.
|
||||
- [Memcached](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/memcached/README.md): Collect
|
||||
memory-caching system performance metrics.
|
||||
|
||||
### Distributed computing
|
||||
|
||||
- [BOINC](/collectors/python.d.plugin/boinc/README.md): Monitor the total number of tasks, open tasks, and task
|
||||
- [BOINC](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/boinc/README.md): Monitor the total
|
||||
number of tasks, open tasks, and task
|
||||
states for the distributed computing client.
|
||||
- [Gearman](/collectors/python.d.plugin/gearman/README.md): Collect application summary (queued, running) and per-job
|
||||
- [Gearman](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/gearman/README.md): Collect
|
||||
application summary (queued, running) and per-job
|
||||
worker statistics (queued, idle, running).
|
||||
|
||||
### Email
|
||||
|
||||
- [Dovecot](/collectors/python.d.plugin/dovecot/README.md): Collect email server performance metrics by reading the
|
||||
- [Dovecot](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/dovecot/README.md): Collect email
|
||||
server performance metrics by reading the
|
||||
server's response to the `EXPORT global` command.
|
||||
- [EXIM](/collectors/python.d.plugin/exim/README.md): Uses the `exim` tool to monitor the queue length of a
|
||||
- [EXIM](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/exim/README.md): Uses the `exim` tool
|
||||
to monitor the queue length of a
|
||||
mail/message transfer agent (MTA).
|
||||
- [Postfix](/collectors/python.d.plugin/postfix/README.md): Uses the `postqueue` tool to monitor the queue length of a
|
||||
- [Postfix](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/postfix/README.md): Uses
|
||||
the `postqueue` tool to monitor the queue length of a
|
||||
mail/message transfer agent (MTA).
|
||||
|
||||
### Kubernetes
|
||||
|
||||
- [Kubelet](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/k8s_kubelet/): Monitor one or more
|
||||
- [Kubelet](https://github.com/netdata/go.d.plugin/blob/master/modules/k8s_kubelet/README.md): Monitor one or more
|
||||
instances of the Kubelet agent and collects metrics on number of pods/containers running, volume of Docker
|
||||
operations, and more.
|
||||
- [kube-proxy](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/k8s_kubeproxy/): Collect
|
||||
- [kube-proxy](https://github.com/netdata/go.d.plugin/blob/master/modules/k8s_kubeproxy/README.md): Collect
|
||||
metrics, such as syncing proxy rules and REST client requests, from one or more instances of `kube-proxy`.
|
||||
- [Service discovery](https://github.com/netdata/agent-service-discovery/): Find what services are running on a
|
||||
- [Service discovery](https://github.com/netdata/agent-service-discovery/README.md): Find what services are running on a
|
||||
cluster's pods, converts that into configuration files, and exports them so they can be monitored by Netdata.
|
||||
|
||||
### Logs
|
||||
|
||||
- [Fluentd](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/fluentd/): Gather application
|
||||
- [Fluentd](https://github.com/netdata/go.d.plugin/blob/master/modules/fluentd/README.md): Gather application
|
||||
plugins metrics from an endpoint provided by `in_monitor plugin`.
|
||||
- [Logstash](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/logstash/): Monitor JVM threads,
|
||||
- [Logstash](https://github.com/netdata/go.d.plugin/blob/master/modules/logstash/README.md): Monitor JVM threads,
|
||||
memory usage, garbage collection statistics, and more.
|
||||
- [OpenVPN status logs](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/openvpn_status_log): Parse
|
||||
- [OpenVPN status logs](https://github.com/netdata/go.d.plugin/blob/master/modules/openvpn_status_log/README.md): Parse
|
||||
server log files and provide summary (client, traffic) metrics.
|
||||
- [Squid web server logs](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/squidlog/): Tail Squid
|
||||
- [Squid web server logs](https://github.com/netdata/go.d.plugin/blob/master/modules/squidlog/README.md): Tail Squid
|
||||
access logs to return the volume of requests, types of requests, bandwidth, and much more.
|
||||
- [Web server logs (Go version for Apache,
|
||||
NGINX)](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/weblog/): Tail access logs and provide
|
||||
NGINX)](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md/): Tail access logs and provide
|
||||
very detailed web server performance statistics. This module is able to parse 200k+ rows in less than half a second.
|
||||
- [Web server logs (Apache, NGINX)](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/weblog): Tail
|
||||
- [Web server logs (Apache, NGINX)](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md): Tail
|
||||
access log
|
||||
file and collect web server/caching proxy metrics.
|
||||
|
||||
### Messaging
|
||||
|
||||
- [ActiveMQ](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/activemq/): Collect message broker
|
||||
- [ActiveMQ](https://github.com/netdata/go.d.plugin/blob/master/modules/activemq/README.md): Collect message broker
|
||||
queues and topics statistics using the ActiveMQ Console API.
|
||||
- [Beanstalk](/collectors/python.d.plugin/beanstalk/README.md): Collect server and tube-level statistics, such as CPU
|
||||
- [Beanstalk](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/beanstalk/README.md): Collect
|
||||
server and tube-level statistics, such as CPU
|
||||
usage, jobs rates, commands, and more.
|
||||
- [Pulsar](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/pulsar/): Collect summary,
|
||||
- [Pulsar](https://github.com/netdata/go.d.plugin/blob/master/modules/pulsar/README.md): Collect summary,
|
||||
namespaces, and topics performance statistics.
|
||||
- [RabbitMQ (Go)](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/rabbitmq/): Collect message
|
||||
- [RabbitMQ (Go)](https://github.com/netdata/go.d.plugin/blob/master/modules/rabbitmq/README.md): Collect message
|
||||
broker overview, system and per virtual host metrics.
|
||||
- [RabbitMQ (Python)](/collectors/python.d.plugin/rabbitmq/README.md): Collect message broker global and per virtual
|
||||
- [RabbitMQ (Python)](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/rabbitmq/README.md):
|
||||
Collect message broker global and per virtual
|
||||
host metrics.
|
||||
- [VerneMQ](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/vernemq/): Monitor MQTT broker
|
||||
- [VerneMQ](https://github.com/netdata/go.d.plugin/blob/master/modules/vernemq/README.md): Monitor MQTT broker
|
||||
health and performance metrics. It collects all available info for both MQTTv3 and v5 communication
|
||||
|
||||
### Network
|
||||
|
||||
- [Bind 9](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/bind/): Collect nameserver summary
|
||||
- [Bind 9](https://github.com/netdata/go.d.plugin/blob/master/modules/bind/README.md): Collect nameserver summary
|
||||
performance statistics via a web interface (`statistics-channels` feature).
|
||||
- [Chrony](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/chrony): Monitor the precision and
|
||||
- [Chrony](https://github.com/netdata/go.d.plugin/blob/master/modules/chrony/README.md): Monitor the precision and
|
||||
statistics of a local `chronyd` server.
|
||||
- [CoreDNS](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/coredns/): Measure DNS query round
|
||||
- [CoreDNS](https://github.com/netdata/go.d.plugin/blob/master/modules/coredns/README.md): Measure DNS query round
|
||||
trip time.
|
||||
- [Dnsmasq](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/dnsmasq_dhcp/): Automatically
|
||||
- [Dnsmasq](https://github.com/netdata/go.d.plugin/blob/master/modules/dnsmasq_dhcp/README.md): Automatically
|
||||
detects all configured `Dnsmasq` DHCP ranges and Monitor their utilization.
|
||||
- [DNSdist](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/dnsdist/): Collect
|
||||
- [DNSdist](https://github.com/netdata/go.d.plugin/blob/master/modules/dnsdist/README.md): Collect
|
||||
load-balancer performance and health metrics.
|
||||
- [Dnsmasq DNS Forwarder](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/dnsmasq/): Gather
|
||||
- [Dnsmasq DNS Forwarder](https://github.com/netdata/go.d.plugin/blob/master/modules/dnsmasq/README.md): Gather
|
||||
queries, entries, operations, and events for the lightweight DNS forwarder.
|
||||
- [DNS Query Time](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/dnsquery/): Monitor the round
|
||||
- [DNS Query Time](https://github.com/netdata/go.d.plugin/blob/master/modules/dnsquery/README.md): Monitor the round
|
||||
trip time for DNS queries in milliseconds.
|
||||
- [Freeradius](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/freeradius/): Collect
|
||||
- [Freeradius](https://github.com/netdata/go.d.plugin/blob/master/modules/freeradius/README.md): Collect
|
||||
server authentication and accounting statistics from the `status server`.
|
||||
- [Libreswan](/collectors/charts.d.plugin/libreswan/README.md): Collect bytes-in, bytes-out, and uptime metrics.
|
||||
- [Icecast](/collectors/python.d.plugin/icecast/README.md): Monitor the number of listeners for active sources.
|
||||
- [ISC Bind (RDNC)](/collectors/python.d.plugin/bind_rndc/README.md): Collect nameserver summary performance
|
||||
- [Libreswan](https://github.com/netdata/netdata/blob/master/collectors/charts.d.plugin/libreswan/README.md): Collect
|
||||
bytes-in, bytes-out, and uptime metrics.
|
||||
- [Icecast](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/icecast/README.md): Monitor the
|
||||
number of listeners for active sources.
|
||||
- [ISC Bind (RDNC)](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/bind_rndc/README.md):
|
||||
Collect nameserver summary performance
|
||||
statistics using the `rndc` tool.
|
||||
- [ISC DHCP](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/isc_dhcpd): Reads a
|
||||
- [ISC DHCP](https://github.com/netdata/go.d.plugin/blob/master/modules/isc_dhcpd/README.md): Reads a
|
||||
`dhcpd.leases` file and collects metrics on total active leases, pool active leases, and pool utilization.
|
||||
- [OpenLDAP](/collectors/python.d.plugin/openldap/README.md): Provides statistics information from the OpenLDAP
|
||||
- [OpenLDAP](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/openldap/README.md): Provides
|
||||
statistics information from the OpenLDAP
|
||||
(`slapd`) server.
|
||||
- [NSD](/collectors/python.d.plugin/nsd/README.md): Monitor nameserver performance metrics using the `nsd-control`
|
||||
- [NSD](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/nsd/README.md): Monitor nameserver
|
||||
performance metrics using the `nsd-control`
|
||||
tool.
|
||||
- [NTP daemon](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/ntpd): Monitor the system variables
|
||||
of the local `ntpd` daemon (optionally including variables of the polled peers) using the NTP Control Message Protocol
|
||||
via a UDP socket.
|
||||
- [OpenSIPS](/collectors/charts.d.plugin/opensips/README.md): Collect server health and performance metrics using the
|
||||
- [OpenSIPS](https://github.com/netdata/netdata/blob/master/collectors/charts.d.plugin/opensips/README.md): Collect
|
||||
server health and performance metrics using the
|
||||
`opensipsctl` tool.
|
||||
- [OpenVPN](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/openvpn/): Gather server summary
|
||||
- [OpenVPN](https://github.com/netdata/go.d.plugin/blob/master/modules/openvpn/README.md): Gather server summary
|
||||
(client, traffic) and per user metrics (traffic, connection time) stats using `management-interface`.
|
||||
- [Pi-hole](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/pihole/): Monitor basic (DNS
|
||||
- [Pi-hole](https://github.com/netdata/go.d.plugin/blob/master/modules/pihole/README.md): Monitor basic (DNS
|
||||
queries, clients, blocklist) and extended (top clients, top permitted, and blocked domains) statistics using the PHP
|
||||
API.
|
||||
- [PowerDNS Authoritative Server](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/powerdns):
|
||||
- [PowerDNS Authoritative Server](https://github.com/netdata/go.d.plugin/blob/master/modules/powerdns/README.md):
|
||||
Monitor one or more instances of the nameserver software to collect questions, events, and latency metrics.
|
||||
- [PowerDNS Recursor](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/powerdns_recursor):
|
||||
- [PowerDNS Recursor](https://github.com/netdata/go.d.plugin/blob/master/modules/powerdns/README.md_recursor):
|
||||
Gather incoming/outgoing questions, drops, timeouts, and cache usage from any number of DNS recursor instances.
|
||||
- [RetroShare](/collectors/python.d.plugin/retroshare/README.md): Monitor application bandwidth, peers, and DHT
|
||||
- [RetroShare](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/retroshare/README.md): Monitor
|
||||
application bandwidth, peers, and DHT
|
||||
metrics.
|
||||
- [Tor](/collectors/python.d.plugin/tor/README.md): Capture traffic usage statistics using the Tor control port.
|
||||
- [Unbound](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/unbound/): Collect DNS resolver
|
||||
- [Tor](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/tor/README.md): Capture traffic usage
|
||||
statistics using the Tor control port.
|
||||
- [Unbound](https://github.com/netdata/go.d.plugin/blob/master/modules/unbound/README.md): Collect DNS resolver
|
||||
summary and extended system and per thread metrics via the `remote-control` interface.
|
||||
|
||||
### Provisioning
|
||||
|
||||
- [Puppet](/collectors/python.d.plugin/puppet/README.md): Monitor the status of Puppet Server and Puppet DB.
|
||||
- [Puppet](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/puppet/README.md): Monitor the
|
||||
status of Puppet Server and Puppet DB.
|
||||
|
||||
### Remote devices
|
||||
|
||||
- [AM2320](/collectors/python.d.plugin/am2320/README.md): Monitor sensor temperature and humidity.
|
||||
- [Access point](/collectors/charts.d.plugin/ap/README.md): Monitor client, traffic and signal metrics using the `aw`
|
||||
- [AM2320](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/am2320/README.md): Monitor sensor
|
||||
temperature and humidity.
|
||||
- [Access point](https://github.com/netdata/netdata/blob/master/collectors/charts.d.plugin/ap/README.md): Monitor
|
||||
client, traffic and signal metrics using the `aw`
|
||||
tool.
|
||||
- [APC UPS](/collectors/charts.d.plugin/apcupsd/README.md): Capture status information using the `apcaccess` tool.
|
||||
- [Energi Core](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/energid): Monitor
|
||||
- [APC UPS](https://github.com/netdata/netdata/blob/master/collectors/charts.d.plugin/apcupsd/README.md): Capture status
|
||||
information using the `apcaccess` tool.
|
||||
- [Energi Core](https://github.com/netdata/go.d.plugin/blob/master/modules/energid/README.md): Monitor
|
||||
blockchain indexes, memory usage, network usage, and transactions of wallet instances.
|
||||
- [UPS/PDU](/collectors/charts.d.plugin/nut/README.md): Read the status of UPS/PDU devices using the `upsc` tool.
|
||||
- [SNMP devices](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/snmp): Gather data using the SNMP
|
||||
- [UPS/PDU](https://github.com/netdata/netdata/blob/master/collectors/charts.d.plugin/nut/README.md): Read the status of
|
||||
UPS/PDU devices using the `upsc` tool.
|
||||
- [SNMP devices](https://github.com/netdata/go.d.plugin/blob/master/modules/snmp/README.md): Gather data using the SNMP
|
||||
protocol.
|
||||
- [1-Wire sensors](/collectors/python.d.plugin/w1sensor/README.md): Monitor sensor temperature.
|
||||
- [1-Wire sensors](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/w1sensor/README.md):
|
||||
Monitor sensor temperature.
|
||||
|
||||
### Search
|
||||
|
||||
- [Elasticsearch](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/elasticsearch): Collect
|
||||
- [Elasticsearch](https://github.com/netdata/go.d.plugin/blob/master/modules/elasticsearch/README.md): Collect
|
||||
dozens of metrics on search engine performance from local nodes and local indices. Includes cluster health and
|
||||
statistics.
|
||||
- [Solr](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/solr/): Collect application search
|
||||
- [Solr](https://github.com/netdata/go.d.plugin/blob/master/modules/solr/README.md): Collect application search
|
||||
requests, search errors, update requests, and update errors statistics.
|
||||
|
||||
### Storage
|
||||
|
||||
- [Ceph](/collectors/python.d.plugin/ceph/README.md): Monitor the Ceph cluster usage and server data consumption.
|
||||
- [HDFS](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/hdfs/): Monitor health and performance
|
||||
- [Ceph](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/ceph/README.md): Monitor the Ceph
|
||||
cluster usage and server data consumption.
|
||||
- [HDFS](https://github.com/netdata/go.d.plugin/blob/master/modules/hdfs/README.md): Monitor health and performance
|
||||
metrics for filesystem datanodes and namenodes.
|
||||
- [IPFS](/collectors/python.d.plugin/ipfs/README.md): Collect file system bandwidth, peers, and repo metrics.
|
||||
- [Scaleio](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/scaleio/): Monitor storage system,
|
||||
- [IPFS](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/ipfs/README.md): Collect file system
|
||||
bandwidth, peers, and repo metrics.
|
||||
- [Scaleio](https://github.com/netdata/go.d.plugin/blob/master/modules/scaleio/README.md): Monitor storage system,
|
||||
storage pools, and SDCS health and performance metrics via VxFlex OS Gateway API.
|
||||
- [Samba](/collectors/python.d.plugin/samba/README.md): Collect file sharing metrics using the `smbstatus` tool.
|
||||
- [Samba](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/samba/README.md): Collect file
|
||||
sharing metrics using the `smbstatus` tool.
|
||||
|
||||
### Web
|
||||
|
||||
- [Apache](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/apache/): Collect Apache web
|
||||
- [Apache](https://github.com/netdata/go.d.plugin/blob/master/modules/apache/README.md): Collect Apache web
|
||||
server performance metrics via the `server-status?auto` endpoint.
|
||||
- [HAProxy](/collectors/python.d.plugin/haproxy/README.md): Collect frontend, backend, and health metrics.
|
||||
- [HTTP endpoints](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/httpcheck/): Monitor
|
||||
- [HAProxy](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/haproxy/README.md): Collect
|
||||
frontend, backend, and health metrics.
|
||||
- [HTTP endpoints](https://github.com/netdata/go.d.plugin/blob/master/modules/httpcheck/README.md): Monitor
|
||||
any HTTP endpoint's availability and response time.
|
||||
- [Lighttpd](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/lighttpd/): Collect web server
|
||||
- [Lighttpd](https://github.com/netdata/go.d.plugin/blob/master/modules/lighttpd/README.md): Collect web server
|
||||
performance metrics using the `server-status?auto` endpoint.
|
||||
- [Lighttpd2](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/lighttpd2/): Collect web server
|
||||
- [Lighttpd2](https://github.com/netdata/go.d.plugin/blob/master/modules/lighttpd2/README.md): Collect web server
|
||||
performance metrics using the `server-status?format=plain` endpoint.
|
||||
- [Litespeed](/collectors/python.d.plugin/litespeed/README.md): Collect web server data (network, connection,
|
||||
- [Litespeed](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/litespeed/README.md): Collect
|
||||
web server data (network, connection,
|
||||
requests, cache) by reading `.rtreport*` files.
|
||||
- [Nginx](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/nginx/): Monitor web server
|
||||
- [Nginx](https://github.com/netdata/go.d.plugin/blob/master/modules/nginx/README.md): Monitor web server
|
||||
status information by gathering metrics via `ngx_http_stub_status_module`.
|
||||
- [Nginx VTS](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/nginxvts/): Gathers metrics from
|
||||
- [Nginx VTS](https://github.com/netdata/go.d.plugin/blob/master/modules/nginxvts/README.md): Gathers metrics from
|
||||
any Nginx deployment with the _virtual host traffic status module_ enabled, including metrics on uptime, memory
|
||||
usage, and cache, and more.
|
||||
- [PHP-FPM](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/phpfpm/): Collect application
|
||||
- [PHP-FPM](https://github.com/netdata/go.d.plugin/blob/master/modules/phpfpm/README.md): Collect application
|
||||
summary and processes health metrics by scraping the status page (`/status?full`).
|
||||
- [TCP endpoints](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/portcheck/): Monitor any
|
||||
- [TCP endpoints](https://github.com/netdata/go.d.plugin/blob/master/modules/portcheck/README.md): Monitor any
|
||||
TCP endpoint's availability and response time.
|
||||
- [Spigot Minecraft servers](/collectors/python.d.plugin/spigotmc/README.md): Monitor average ticket rate and number
|
||||
- [Spigot Minecraft servers](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/spigotmc/README.md):
|
||||
Monitor average ticket rate and number
|
||||
of users.
|
||||
- [Squid](/collectors/python.d.plugin/squid/README.md): Monitor client and server bandwidth/requests by gathering
|
||||
- [Squid](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/squid/README.md): Monitor client and
|
||||
server bandwidth/requests by gathering
|
||||
data from the Cache Manager component.
|
||||
- [Tengine](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/tengine/): Monitor web server
|
||||
- [Tengine](https://github.com/netdata/go.d.plugin/blob/master/modules/tengine/README.md): Monitor web server
|
||||
statistics using information provided by `ngx_http_reqstat_module`.
|
||||
- [Tomcat](/collectors/python.d.plugin/tomcat/README.md): Collect web server performance metrics from the Manager App
|
||||
- [Tomcat](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/tomcat/README.md): Collect web
|
||||
server performance metrics from the Manager App
|
||||
(`/manager/status?XML=true`).
|
||||
- [Traefik](/collectors/python.d.plugin/traefik/README.md): Uses Traefik's Health API to provide statistics.
|
||||
- [Varnish](/collectors/python.d.plugin/varnish/README.md): Provides HTTP accelerator global, backends (VBE), and
|
||||
- [Traefik](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/traefik/README.md): Uses Traefik's
|
||||
Health API to provide statistics.
|
||||
- [Varnish](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/varnish/README.md): Provides HTTP
|
||||
accelerator global, backends (VBE), and
|
||||
disks (SMF) statistics using the `varnishstat` tool.
|
||||
- [x509 check](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/x509check/): Monitor certificate
|
||||
- [x509 check](https://github.com/netdata/go.d.plugin/blob/master/modules/x509check/README.md): Monitor certificate
|
||||
expiration time.
|
||||
- [Whois domain expiry](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/whoisquery/): Checks the
|
||||
- [Whois domain expiry](https://github.com/netdata/go.d.plugin/blob/master/modules/whoisquery/README.md): Checks the
|
||||
remaining time until a given domain is expired.
|
||||
|
||||
## System collectors
|
||||
|
|
@ -335,139 +382,198 @@ The Netdata Agent can collect these system- and hardware-level metrics using a v
|
|||
|
||||
### Applications
|
||||
|
||||
- [Fail2ban](/collectors/python.d.plugin/fail2ban/README.md): Parses configuration files to detect all jails, then
|
||||
- [Fail2ban](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/fail2ban/README.md): Parses
|
||||
configuration files to detect all jails, then
|
||||
uses log files to report ban rates and volume of banned IPs.
|
||||
- [Monit](/collectors/python.d.plugin/monit/README.md): Monitor statuses of targets (service-checks) using the XML
|
||||
- [Monit](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/monit/README.md): Monitor statuses
|
||||
of targets (service-checks) using the XML
|
||||
stats interface.
|
||||
- [WMI (Windows Management Instrumentation)
|
||||
exporter](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/wmi/): Collect CPU, memory,
|
||||
exporter](https://github.com/netdata/go.d.plugin/blob/master/modules/wmi/README.md): Collect CPU, memory,
|
||||
network, disk, OS, system, and log-in metrics scraping `wmi_exporter`.
|
||||
|
||||
### Disks and filesystems
|
||||
|
||||
- [BCACHE](/collectors/proc.plugin/README.md): Monitor BCACHE statistics with the the `proc.plugin` collector.
|
||||
- [Block devices](/collectors/proc.plugin/README.md): Gather metrics about the health and performance of block
|
||||
- [BCACHE](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Monitor BCACHE statistics
|
||||
with the the `proc.plugin` collector.
|
||||
- [Block devices](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Gather metrics about
|
||||
the health and performance of block
|
||||
devices using the the `proc.plugin` collector.
|
||||
- [Btrfs](/collectors/proc.plugin/README.md): Monitors Btrfs filesystems with the the `proc.plugin` collector.
|
||||
- [Device mapper](/collectors/proc.plugin/README.md): Gather metrics about the Linux device mapper with the proc
|
||||
- [Btrfs](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Monitors Btrfs filesystems
|
||||
with the the `proc.plugin` collector.
|
||||
- [Device mapper](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Gather metrics about
|
||||
the Linux device mapper with the proc
|
||||
collector.
|
||||
- [Disk space](/collectors/diskspace.plugin/README.md): Collect disk space usage metrics on Linux mount points.
|
||||
- [Clock synchronization](/collectors/timex.plugin/README.md): Collect the system clock synchronization status on Linux.
|
||||
- [Files and directories](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/filecheck): Gather
|
||||
- [Disk space](https://github.com/netdata/netdata/blob/master/collectors/diskspace.plugin/README.md): Collect disk space
|
||||
usage metrics on Linux mount points.
|
||||
- [Clock synchronization](https://github.com/netdata/netdata/blob/master/collectors/timex.plugin/README.md): Collect the
|
||||
system clock synchronization status on Linux.
|
||||
- [Files and directories](https://github.com/netdata/go.d.plugin/blob/master/modules/filecheck/README.md): Gather
|
||||
metrics about the existence, modification time, and size of files or directories.
|
||||
- [ioping.plugin](/collectors/ioping.plugin/README.md): Measure disk read/write latency.
|
||||
- [NFS file servers and clients](/collectors/proc.plugin/README.md): Gather operations, utilization, and space usage
|
||||
- [ioping.plugin](https://github.com/netdata/netdata/blob/master/collectors/ioping.plugin/README.md): Measure disk
|
||||
read/write latency.
|
||||
- [NFS file servers and clients](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md):
|
||||
Gather operations, utilization, and space usage
|
||||
using the the `proc.plugin` collector.
|
||||
- [RAID arrays](/collectors/proc.plugin/README.md): Collect health, disk status, operation status, and more with the
|
||||
- [RAID arrays](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Collect health, disk
|
||||
status, operation status, and more with the
|
||||
the `proc.plugin` collector.
|
||||
- [Veritas Volume Manager](/collectors/proc.plugin/README.md): Gather metrics about the Veritas Volume Manager (VVM).
|
||||
- [ZFS](/collectors/proc.plugin/README.md): Monitor bandwidth and utilization of ZFS disks/partitions using the proc
|
||||
- [Veritas Volume Manager](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Gather
|
||||
metrics about the Veritas Volume Manager (VVM).
|
||||
- [ZFS](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Monitor bandwidth and
|
||||
utilization of ZFS disks/partitions using the proc
|
||||
collector.
|
||||
|
||||
### eBPF
|
||||
|
||||
- [Files](/collectors/ebpf.plugin/README.md): Provides information about how often a system calls kernel
|
||||
- [Files](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md): Provides information about
|
||||
how often a system calls kernel
|
||||
functions related to file descriptors using the eBPF collector.
|
||||
- [Virtual file system (VFS)](/collectors/ebpf.plugin/README.md): Monitor IO, errors, deleted objects, and
|
||||
- [Virtual file system (VFS)](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md): Monitor
|
||||
IO, errors, deleted objects, and
|
||||
more for kernel virtual file systems (VFS) using the eBPF collector.
|
||||
- [Processes](/collectors/ebpf.plugin/README.md): Monitor threads, task exits, and errors using the eBPF collector.
|
||||
- [Processes](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md): Monitor threads, task
|
||||
exits, and errors using the eBPF collector.
|
||||
|
||||
### Hardware
|
||||
|
||||
- [Adaptec RAID](/collectors/python.d.plugin/adaptec_raid/README.md): Monitor logical and physical devices health
|
||||
- [Adaptec RAID](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/adaptec_raid/README.md):
|
||||
Monitor logical and physical devices health
|
||||
metrics using the `arcconf` tool.
|
||||
- [CUPS](/collectors/cups.plugin/README.md): Monitor CUPS.
|
||||
- [FreeIPMI](/collectors/freeipmi.plugin/README.md): Uses `libipmimonitoring-dev` or `libipmimonitoring-devel` to
|
||||
- [CUPS](https://github.com/netdata/netdata/blob/master/collectors/cups.plugin/README.md): Monitor CUPS.
|
||||
- [FreeIPMI](https://github.com/netdata/netdata/blob/master/collectors/freeipmi.plugin/README.md):
|
||||
Uses `libipmimonitoring-dev` or `libipmimonitoring-devel` to
|
||||
monitor the number of sensors, temperatures, voltages, currents, and more.
|
||||
- [Hard drive temperature](/collectors/python.d.plugin/hddtemp/README.md): Monitor the temperature of storage
|
||||
- [Hard drive temperature](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/hddtemp/README.md):
|
||||
Monitor the temperature of storage
|
||||
devices.
|
||||
- [HP Smart Storage Arrays](/collectors/python.d.plugin/hpssa/README.md): Monitor controller, cache module, logical
|
||||
- [HP Smart Storage Arrays](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/hpssa/README.md):
|
||||
Monitor controller, cache module, logical
|
||||
and physical drive state, and temperature using the `ssacli` tool.
|
||||
- [MegaRAID controllers](/collectors/python.d.plugin/megacli/README.md): Collect adapter, physical drives, and
|
||||
- [MegaRAID controllers](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/megacli/README.md):
|
||||
Collect adapter, physical drives, and
|
||||
battery stats using the `megacli` tool.
|
||||
- [NVIDIA GPU](/collectors/python.d.plugin/nvidia_smi/README.md): Monitor performance metrics (memory usage, fan
|
||||
- [NVIDIA GPU](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/nvidia_smi/README.md): Monitor
|
||||
performance metrics (memory usage, fan
|
||||
speed, pcie bandwidth utilization, temperature, and more) using the `nvidia-smi` tool.
|
||||
- [Sensors](/collectors/python.d.plugin/sensors/README.md): Reads system sensors information (temperature, voltage,
|
||||
- [Sensors](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/sensors/README.md): Reads system
|
||||
sensors information (temperature, voltage,
|
||||
electric current, power, and more) from `/sys/devices/`.
|
||||
- [S.M.A.R.T](/collectors/python.d.plugin/smartd_log/README.md): Reads SMART Disk Monitoring daemon logs.
|
||||
- [S.M.A.R.T](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/smartd_log/README.md): Reads
|
||||
SMART Disk Monitoring daemon logs.
|
||||
|
||||
### Memory
|
||||
|
||||
- [Available memory](/collectors/proc.plugin/README.md): Tracks changes in available RAM using the the `proc.plugin`
|
||||
- [Available memory](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Tracks changes in
|
||||
available RAM using the the `proc.plugin`
|
||||
collector.
|
||||
- [Committed memory](/collectors/proc.plugin/README.md): Monitor committed memory using the `proc.plugin` collector.
|
||||
- [Huge pages](/collectors/proc.plugin/README.md): Gather metrics about huge pages in Linux and FreeBSD with the
|
||||
- [Committed memory](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Monitor committed
|
||||
memory using the `proc.plugin` collector.
|
||||
- [Huge pages](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Gather metrics about
|
||||
huge pages in Linux and FreeBSD with the
|
||||
`proc.plugin` collector.
|
||||
- [KSM](/collectors/proc.plugin/README.md): Measure the amount of merging, savings, and effectiveness using the
|
||||
- [KSM](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Measure the amount of merging,
|
||||
savings, and effectiveness using the
|
||||
`proc.plugin` collector.
|
||||
- [Numa](/collectors/proc.plugin/README.md): Gather metrics on the number of non-uniform memory access (NUMA) events
|
||||
- [Numa](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Gather metrics on the number
|
||||
of non-uniform memory access (NUMA) events
|
||||
every second using the `proc.plugin` collector.
|
||||
- [Page faults](/collectors/proc.plugin/README.md): Collect the number of memory page faults per second using the
|
||||
- [Page faults](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Collect the number of
|
||||
memory page faults per second using the
|
||||
`proc.plugin` collector.
|
||||
- [RAM](/collectors/proc.plugin/README.md): Collect metrics on system RAM, available RAM, and more using the
|
||||
- [RAM](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Collect metrics on system RAM,
|
||||
available RAM, and more using the
|
||||
`proc.plugin` collector.
|
||||
- [SLAB](/collectors/slabinfo.plugin/README.md): Collect kernel SLAB details on Linux systems.
|
||||
- [swap](/collectors/proc.plugin/README.md): Monitor the amount of free and used swap at every second using the
|
||||
- [SLAB](https://github.com/netdata/netdata/blob/master/collectors/slabinfo.plugin/README.md): Collect kernel SLAB
|
||||
details on Linux systems.
|
||||
- [swap](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Monitor the amount of free
|
||||
and used swap at every second using the
|
||||
`proc.plugin` collector.
|
||||
- [Writeback memory](/collectors/proc.plugin/README.md): Collect how much memory is actively being written to disk at
|
||||
- [Writeback memory](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Collect how much
|
||||
memory is actively being written to disk at
|
||||
every second using the `proc.plugin` collector.
|
||||
|
||||
### Networks
|
||||
|
||||
- [Access points](/collectors/charts.d.plugin/ap/README.md): Visualizes data related to access points.
|
||||
- [Ping](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/ping/): Measure network latency, jitter and packet loss between the monitored node
|
||||
- [Access points](https://github.com/netdata/netdata/blob/master/collectors/charts.d.plugin/ap/README.md): Visualizes
|
||||
data related to access points.
|
||||
- [Ping](https://github.com/netdata/go.d.plugin/blob/master/modules/ping/README.md): Measure network latency, jitter and
|
||||
packet loss between the monitored node
|
||||
and any number of remote network end points.
|
||||
- [Netfilter](/collectors/nfacct.plugin/README.md): Collect netfilter firewall, connection tracker, and accounting
|
||||
- [Netfilter](https://github.com/netdata/netdata/blob/master/collectors/nfacct.plugin/README.md): Collect netfilter
|
||||
firewall, connection tracker, and accounting
|
||||
metrics using `libmnl` and `libnetfilter_acct`.
|
||||
- [Network stack](/collectors/proc.plugin/README.md): Monitor the networking stack for errors, TCP connection aborts,
|
||||
- [Network stack](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Monitor the
|
||||
networking stack for errors, TCP connection aborts,
|
||||
bandwidth, and more.
|
||||
- [Network QoS](/collectors/tc.plugin/README.md): Collect traffic QoS metrics (`tc`) of Linux network interfaces.
|
||||
- [SYNPROXY](/collectors/proc.plugin/README.md): Monitor entries uses, SYN packets received, TCP cookies, and more.
|
||||
- [Network QoS](https://github.com/netdata/netdata/blob/master/collectors/tc.plugin/README.md): Collect traffic QoS
|
||||
metrics (`tc`) of Linux network interfaces.
|
||||
- [SYNPROXY](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Monitor entries uses, SYN
|
||||
packets received, TCP cookies, and more.
|
||||
|
||||
### Operating systems
|
||||
|
||||
- [freebsd.plugin](freebsd.plugin/README.md): Collect resource usage and performance data on FreeBSD systems.
|
||||
- [macOS](/collectors/macos.plugin/README.md): Collect resource usage and performance data on macOS systems.
|
||||
- [freebsd.plugin](https://github.com/netdata/netdata/blob/master/collectors/freebsd.plugin/README.md): Collect resource
|
||||
usage and performance data on FreeBSD systems.
|
||||
- [macOS](https://github.com/netdata/netdata/blob/master/collectors/macos.plugin/README.md): Collect resource usage and
|
||||
performance data on macOS systems.
|
||||
|
||||
### Processes
|
||||
|
||||
- [Applications](/collectors/apps.plugin/README.md): Gather CPU, disk, memory, network, eBPF, and other metrics per
|
||||
- [Applications](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md): Gather CPU, disk,
|
||||
memory, network, eBPF, and other metrics per
|
||||
application using the `apps.plugin` collector.
|
||||
- [systemd](/collectors/cgroups.plugin/README.md): Monitor the CPU and memory usage of systemd services using the
|
||||
- [systemd](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md): Monitor the CPU and
|
||||
memory usage of systemd services using the
|
||||
`cgroups.plugin` collector.
|
||||
- [systemd unit states](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/systemdunits): See the
|
||||
- [systemd unit states](https://github.com/netdata/go.d.plugin/blob/master/modules/systemdunits/README.md): See the
|
||||
state (active, inactive, activating, deactivating, failed) of various systemd unit types.
|
||||
- [System processes](/collectors/proc.plugin/README.md): Collect metrics on system load and total processes running
|
||||
- [System processes](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Collect metrics
|
||||
on system load and total processes running
|
||||
using `/proc/loadavg` and the `proc.plugin` collector.
|
||||
- [Uptime](/collectors/proc.plugin/README.md): Monitor the uptime of a system using the `proc.plugin` collector.
|
||||
- [Uptime](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Monitor the uptime of a
|
||||
system using the `proc.plugin` collector.
|
||||
|
||||
### Resources
|
||||
|
||||
- [CPU frequency](/collectors/proc.plugin/README.md): Monitor CPU frequency, as set by the `cpufreq` kernel module,
|
||||
- [CPU frequency](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Monitor CPU
|
||||
frequency, as set by the `cpufreq` kernel module,
|
||||
using the `proc.plugin` collector.
|
||||
- [CPU idle](/collectors/proc.plugin/README.md): Measure CPU idle every second using the `proc.plugin` collector.
|
||||
- [CPU performance](/collectors/perf.plugin/README.md): Collect CPU performance metrics using performance monitoring
|
||||
- [CPU idle](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Measure CPU idle every
|
||||
second using the `proc.plugin` collector.
|
||||
- [CPU performance](https://github.com/netdata/netdata/blob/master/collectors/perf.plugin/README.md): Collect CPU
|
||||
performance metrics using performance monitoring
|
||||
units (PMU).
|
||||
- [CPU throttling](/collectors/proc.plugin/README.md): Gather metrics about thermal throttling using the `/proc/stat`
|
||||
- [CPU throttling](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Gather metrics
|
||||
about thermal throttling using the `/proc/stat`
|
||||
module and the `proc.plugin` collector.
|
||||
- [CPU utilization](/collectors/proc.plugin/README.md): Capture CPU utilization, both system-wide and per-core, using
|
||||
- [CPU utilization](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Capture CPU
|
||||
utilization, both system-wide and per-core, using
|
||||
the `/proc/stat` module and the `proc.plugin` collector.
|
||||
- [Entropy](/collectors/proc.plugin/README.md): Monitor the available entropy on a system using the `proc.plugin`
|
||||
- [Entropy](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Monitor the available
|
||||
entropy on a system using the `proc.plugin`
|
||||
collector.
|
||||
- [Interprocess Communication (IPC)](/collectors/proc.plugin/README.md): Monitor IPC semaphores and shared memory
|
||||
- [Interprocess Communication (IPC)](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md):
|
||||
Monitor IPC semaphores and shared memory
|
||||
using the `proc.plugin` collector.
|
||||
- [Interrupts](/collectors/proc.plugin/README.md): Monitor interrupts per second using the `proc.plugin` collector.
|
||||
- [IdleJitter](/collectors/idlejitter.plugin/README.md): Measure CPU latency and jitter on all operating systems.
|
||||
- [SoftIRQs](/collectors/proc.plugin/README.md): Collect metrics on SoftIRQs, both system-wide and per-core, using the
|
||||
- [Interrupts](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Monitor interrupts per
|
||||
second using the `proc.plugin` collector.
|
||||
- [IdleJitter](https://github.com/netdata/netdata/blob/master/collectors/idlejitter.plugin/README.md): Measure CPU
|
||||
latency and jitter on all operating systems.
|
||||
- [SoftIRQs](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Collect metrics on
|
||||
SoftIRQs, both system-wide and per-core, using the
|
||||
`proc.plugin` collector.
|
||||
- [SoftNet](/collectors/proc.plugin/README.md): Capture SoftNet events per second, both system-wide and per-core,
|
||||
- [SoftNet](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md): Capture SoftNet events per
|
||||
second, both system-wide and per-core,
|
||||
using the `proc.plugin` collector.
|
||||
|
||||
### Users
|
||||
|
||||
- [systemd-logind](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/logind/): Monitor active sessions, users, and seats tracked
|
||||
- [systemd-logind](https://github.com/netdata/go.d.plugin/blob/master/modules/logind/README.md): Monitor active
|
||||
sessions, users, and seats tracked
|
||||
by `systemd-logind` or `elogind`.
|
||||
- [User/group usage](/collectors/apps.plugin/README.md): Gather CPU, disk, memory, network, and other metrics per user
|
||||
- [User/group usage](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md): Gather CPU, disk,
|
||||
memory, network, and other metrics per user
|
||||
and user group using the `apps.plugin` collector.
|
||||
|
||||
## Netdata collectors
|
||||
|
|
@ -476,13 +582,18 @@ These collectors are recursive in nature, in that they monitor some function of
|
|||
collectors are described only in code and associated charts in Netdata dashboards.
|
||||
|
||||
- [ACLK (code only)](https://github.com/netdata/netdata/blob/master/aclk/legacy/aclk_stats.c): View whether a Netdata
|
||||
Agent is connected to Netdata Cloud via the [ACLK](/aclk/README.md), the volume of queries, process times, and more.
|
||||
- [Alarms](https://learn.netdata.cloud/docs/agent/collectors/python.d.plugin/alarms): This collector creates an
|
||||
Agent is connected to Netdata Cloud via the [ACLK](https://github.com/netdata/netdata/blob/master/aclk/README.md), the
|
||||
volume of queries, process times, and more.
|
||||
- [Alarms](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/alarms/README.md): This collector
|
||||
creates an
|
||||
**Alarms** menu with one line plot showing the alarm states of a Netdata Agent over time.
|
||||
- [Anomalies](https://learn.netdata.cloud/docs/agent/collectors/python.d.plugin/anomalies): This collector uses the
|
||||
- [Anomalies](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/anomalies/README.md): This
|
||||
collector uses the
|
||||
Python PyOD library to perform unsupervised anomaly detection on your Netdata charts and/or dimensions.
|
||||
- [Exporting (code only)](https://github.com/netdata/netdata/blob/master/exporting/send_internal_metrics.c): Gather
|
||||
metrics on CPU utilization for the [exporting engine](/exporting/README.md), and specific metrics for each enabled
|
||||
metrics on CPU utilization for
|
||||
the [exporting engine](https://github.com/netdata/netdata/blob/master/exporting/README.md), and specific metrics for
|
||||
each enabled
|
||||
exporting connector.
|
||||
- [Global statistics (code only)](https://github.com/netdata/netdata/blob/master/daemon/global_statistics.c): See
|
||||
metrics on the CPU utilization, network traffic, volume of web clients, API responses, database engine usage, and
|
||||
|
|
@ -496,8 +607,10 @@ If you're interested in developing a new collector that you'd like to contribute
|
|||
the `go.d.plugin`.
|
||||
|
||||
- [go.d.plugin](https://github.com/netdata/go.d.plugin): An orchestrator for data collection modules written in `go`.
|
||||
- [python.d.plugin](python.d.plugin/README.md): An orchestrator for data collection modules written in `python` v2/v3.
|
||||
- [charts.d.plugin](charts.d.plugin/README.md): An orchestrator for data collection modules written in `bash` v4+.
|
||||
- [python.d.plugin](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/README.md): An
|
||||
orchestrator for data collection modules written in `python` v2/v3.
|
||||
- [charts.d.plugin](https://github.com/netdata/netdata/blob/master/collectors/charts.d.plugin/README.md): An
|
||||
orchestrator for data collection modules written in `bash` v4+.
|
||||
|
||||
## Third-party collectors
|
||||
|
||||
|
|
@ -509,13 +622,17 @@ default. To use a third-party collector, visit their GitHub/documentation page a
|
|||
|
||||
In general the below steps should be sufficient to use a third party collector.
|
||||
|
||||
1. Download collector code file into [folder expected by Netdata](https://learn.netdata.cloud/docs/agent/collectors/plugins.d#environment-variables).
|
||||
2. Download default collector configuration file into [folder expected by Netdata](https://learn.netdata.cloud/docs/agent/collectors/plugins.d#environment-variables).
|
||||
3. [Edit configuration file](/docs/collect/enable-configure#configure-a-collector) from step 2 if required.
|
||||
4. [Enable collector](/docs/collect/enable-configure#enable-a-collector-or-its-orchestrator).
|
||||
5. [Restart Netdata](/docs/configure/start-stop-restart.md)
|
||||
1. Download collector code file
|
||||
into [folder expected by Netdata](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md#environment-variables).
|
||||
2. Download default collector configuration file
|
||||
into [folder expected by Netdata](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md#environment-variables).
|
||||
3. [Edit configuration file](https://github.com/netdata/netdata/blob/master/docs/collect/enable-configure#configure-a-collector)
|
||||
from step 2 if required.
|
||||
4. [Enable collector](https://github.com/netdata/netdata/blob/master/docs/collect/enable-configure#enable-a-collector-or-its-orchestrator).
|
||||
5. [Restart Netdata](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md)
|
||||
|
||||
For example below are the steps to enable the [Python ClickHouse collector](https://github.com/netdata/community/tree/main/collectors/python.d.plugin/clickhouse).
|
||||
For example below are the steps to enable
|
||||
the [Python ClickHouse collector](https://github.com/netdata/community/tree/main/collectors/python.d.plugin/clickhouse).
|
||||
|
||||
```bash
|
||||
# download python collector script to /usr/libexec/netdata/python.d/
|
||||
|
|
@ -538,7 +655,6 @@ $ sudo systemctl restart netdata
|
|||
|
||||
</details>
|
||||
|
||||
|
||||
- [CyberPower UPS](https://github.com/HawtDogFlvrWtr/netdata_cyberpwrups_plugin): Polls CyberPower UPS data using
|
||||
PowerPanel® Personal Linux.
|
||||
- [Logged-in users](https://github.com/veksh/netdata-numsessions): Collect the number of currently logged-on users.
|
||||
|
|
@ -549,9 +665,12 @@ $ sudo systemctl restart netdata
|
|||
- [Teamspeak 3](https://github.com/coraxx/netdata_ts3_plugin): Pulls active users and bandwidth from TeamSpeak 3
|
||||
servers.
|
||||
- [SSH](https://github.com/Yaser-Amiri/netdata-ssh-module): Monitor failed authentication requests of an SSH server.
|
||||
- [ClickHouse](https://github.com/netdata/community/tree/main/collectors/python.d.plugin/clickhouse): Monitor [ClickHouse](https://clickhouse.com/) database.
|
||||
- [ClickHouse](https://github.com/netdata/community/tree/main/collectors/python.d.plugin/clickhouse):
|
||||
Monitor [ClickHouse](https://clickhouse.com/) database.
|
||||
|
||||
## Etc
|
||||
|
||||
- [charts.d example](charts.d.plugin/example/README.md): An example `charts.d` collector.
|
||||
- [python.d example](python.d.plugin/example/README.md): An example `python.d` collector.
|
||||
- [charts.d example](https://github.com/netdata/netdata/blob/master/collectors/charts.d.plugin/example/README.md): An
|
||||
example `charts.d` collector.
|
||||
- [python.d example](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/example/README.md): An
|
||||
example `python.d` collector.
|
||||
|
|
|
|||
|
|
@ -11,42 +11,44 @@ learn_rel_path: "References/Collectors"
|
|||
# Collecting metrics
|
||||
|
||||
Netdata can collect metrics from hundreds of different sources, be they internal data created by the system itself, or
|
||||
external data created by services or applications. To see _all_ of the sources Netdata collects from, view our [list of
|
||||
supported collectors](/collectors/COLLECTORS.md).
|
||||
external data created by services or applications. To see _all_ of the sources Netdata collects from, view our
|
||||
[list of supported collectors](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md).
|
||||
|
||||
There are two essential points to understand about how collecting metrics works in Netdata:
|
||||
|
||||
- All collectors are **installed by default** with every installation of Netdata. You do not need to install
|
||||
collectors manually to collect metrics from new sources.
|
||||
- Upon startup, Netdata will **auto-detect** any application or service that has a
|
||||
[collector](/collectors/COLLECTORS.md), as long as both the collector and the app/service are configured correctly.
|
||||
- All collectors are **installed by default** with every installation of Netdata. You do not need to install
|
||||
collectors manually to collect metrics from new sources.
|
||||
- Upon startup, Netdata will **auto-detect** any application or service that has a
|
||||
[collector](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md), as long as both the collector
|
||||
and the app/service are configured correctly.
|
||||
|
||||
Most users will want to enable a new Netdata collector for their app/service. For those details, see
|
||||
our [collectors' configuration reference](/collectors/REFERENCE.md).
|
||||
our [collectors' configuration reference](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md).
|
||||
|
||||
## Take your next steps with collectors
|
||||
|
||||
[Supported collectors list](/collectors/COLLECTORS.md)
|
||||
[Supported collectors list](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md)
|
||||
|
||||
[Collectors configuration reference](/collectors/REFERENCE.md)
|
||||
[Collectors configuration reference](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md)
|
||||
|
||||
## Guides
|
||||
|
||||
[Monitor Nginx or Apache web server log files with Netdata](/docs/guides/collect-apache-nginx-web-logs.md)
|
||||
[Monitor Nginx or Apache web server log files with Netdata](https://github.com/netdata/netdata/blob/master/docs/guides/collect-apache-nginx-web-logs.md)
|
||||
|
||||
[Monitor CockroachDB metrics with Netdata](/docs/guides/monitor-cockroachdb.md)
|
||||
[Monitor CockroachDB metrics with Netdata](https://github.com/netdata/netdata/blob/master/docs/guides/monitor-cockroachdb.md)
|
||||
|
||||
[Monitor Unbound DNS servers with Netdata](/docs/guides/collect-unbound-metrics.md)
|
||||
[Monitor Unbound DNS servers with Netdata](https://github.com/netdata/netdata/blob/master/docs/guides/collect-unbound-metrics.md)
|
||||
|
||||
[Monitor a Hadoop cluster with Netdata](/docs/guides/monitor-hadoop-cluster.md)
|
||||
[Monitor a Hadoop cluster with Netdata](https://github.com/netdata/netdata/blob/master/docs/guides/monitor-hadoop-cluster.md)
|
||||
|
||||
## Related features
|
||||
|
||||
**[Dashboards](/web/README.md)**: Visualize your newly-collect metrics in real-time using Netdata's [built-in
|
||||
dashboard](/web/gui/README.md).
|
||||
**[Dashboards](https://github.com/netdata/netdata/blob/master/web/README.md)**: Visualize your newly-collect metrics in
|
||||
real-time using Netdata's [built-in dashboard](https://github.com/netdata/netdata/blob/master/web/gui/README.md).
|
||||
|
||||
**[Exporting](/exporting/README.md)**: Extend our built-in [database engine](/database/engine/README.md), which supports
|
||||
long-term metrics storage, by archiving metrics to external databases like Graphite, Prometheus, MongoDB, TimescaleDB, and more.
|
||||
It can export metrics to multiple databases simultaneously.
|
||||
**[Exporting](https://github.com/netdata/netdata/blob/master/exporting/README.md)**: Extend our
|
||||
built-in [database engine](https://github.com/netdata/netdata/blob/master/database/engine/README.md), which supports
|
||||
long-term metrics storage, by archiving metrics to external databases like Graphite, Prometheus, MongoDB, TimescaleDB,
|
||||
and more. It can export metrics to multiple databases simultaneously.
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -23,7 +23,7 @@ independent processes in a variety of programming languages based on their purpo
|
|||
MySQL database, among many others.
|
||||
|
||||
For most users, enabling individual collectors for the application/service you're interested in is far more important
|
||||
than knowing which plugin it uses. See our [collectors list](/collectors/COLLECTORS.md) to see whether your favorite app/service has
|
||||
than knowing which plugin it uses. See our [collectors list](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md) to see whether your favorite app/service has
|
||||
a collector, and then read the documentation for that specific collector to figure out how to enable it.
|
||||
|
||||
There are three types of plugins:
|
||||
|
|
@ -35,7 +35,7 @@ There are three types of plugins:
|
|||
independent processes. They communicate with the daemon via pipes.
|
||||
- **Plugin orchestrators**, which are external plugins that instead support a number of **modules**. Modules are a
|
||||
type of collector. We have a few plugin orchestrators available for those who want to develop their own collectors,
|
||||
but focus most of our efforts on the [Go plugin](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/).
|
||||
but focus most of our efforts on the [Go plugin](https://github.com/netdata/go.d.plugin/blob/master/README.md).
|
||||
|
||||
## Enable, configure, and disable modules
|
||||
|
||||
|
|
@ -169,5 +169,5 @@ through this, is to examine what other similar plugins do.
|
|||
|
||||
## Write a custom collector
|
||||
|
||||
You can add custom collectors by following the [external plugins documentation](/collectors/plugins.d/README.md).
|
||||
You can add custom collectors by following the [external plugins documentation](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md).
|
||||
|
||||
|
|
|
|||
|
|
@ -66,8 +66,8 @@ Each of these sections provides the same number of charts:
|
|||
- Network
|
||||
- Sockets open (`apps.sockets`)
|
||||
|
||||
In addition, if the [eBPF collector](/collectors/ebpf.plugin/README.md) is running, your dashboard will also show an
|
||||
additional [list of charts](/collectors/ebpf.plugin/README.md#integration-with-appsplugin) using low-level Linux
|
||||
In addition, if the [eBPF collector](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md) is running, your dashboard will also show an
|
||||
additional [list of charts](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md#integration-with-appsplugin) using low-level Linux
|
||||
metrics.
|
||||
|
||||
The above are reported:
|
||||
|
|
@ -163,10 +163,10 @@ There are a few command line options you can pass to `apps.plugin`. The list of
|
|||
### Integration with eBPF
|
||||
|
||||
If you don't see charts under the **eBPF syscall** or **eBPF net** sections, you should edit your
|
||||
[`ebpf.d.conf`](/collectors/ebpf.plugin/README.md#configure-the-ebpf-collector) file to ensure the eBPF program is enabled.
|
||||
[`ebpf.d.conf`](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md#configure-the-ebpf-collector) file to ensure the eBPF program is enabled.
|
||||
|
||||
Also see our [guide on troubleshooting apps with eBPF
|
||||
metrics](/docs/guides/troubleshoot/monitor-debug-applications-ebpf.md) for ideas on how to interpret these charts in a
|
||||
metrics](https://github.com/netdata/netdata/blob/master/docs/guides/troubleshoot/monitor-debug-applications-ebpf.md) for ideas on how to interpret these charts in a
|
||||
few scenarios.
|
||||
|
||||
## Permissions
|
||||
|
|
@ -237,7 +237,7 @@ Examples below for process group `sql`:
|
|||
- Open Pipes 
|
||||
- Open Sockets 
|
||||
|
||||
For more information about badges check [Generating Badges](/web/api/badges/README.md)
|
||||
For more information about badges check [Generating Badges](https://github.com/netdata/netdata/blob/master/web/api/badges/README.md)
|
||||
|
||||
## Comparison with console tools
|
||||
|
||||
|
|
|
|||
|
|
@ -78,7 +78,7 @@ currently unsupported when using unified cgroups.
|
|||
### enabled cgroups
|
||||
|
||||
To provide a sane default, Netdata uses the
|
||||
following [pattern list](https://learn.netdata.cloud/docs/agent/libnetdata/simple_pattern):
|
||||
following [pattern list](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md):
|
||||
|
||||
- checks the pattern against the path of the cgroup
|
||||
|
||||
|
|
@ -309,4 +309,4 @@ cannot find, but immediately:
|
|||
- I/O full pressure
|
||||
|
||||
Network interfaces are monitored by means of
|
||||
the [proc plugin](/collectors/proc.plugin/README.md#monitored-network-interface-metrics).
|
||||
the [proc plugin](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md#monitored-network-interface-metrics).
|
||||
|
|
|
|||
|
|
@ -64,11 +64,11 @@ For a module called `X`, the following criteria must be met:
|
|||
the collector cannot be used).
|
||||
|
||||
- `X_create()` - creates the Netdata charts, following the standard Netdata plugin guides as described in
|
||||
**[External Plugins](/collectors/plugins.d/README.md)** (commands `CHART` and `DIMENSION`).
|
||||
**[External Plugins](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md)** (commands `CHART` and `DIMENSION`).
|
||||
The return value does matter: 0 = OK, 1 = FAILED.
|
||||
|
||||
- `X_update()` - collects the values for the defined charts, following the standard Netdata plugin guides
|
||||
as described in **[External Plugins](/collectors/plugins.d/README.md)** (commands `BEGIN`, `SET`, `END`).
|
||||
as described in **[External Plugins](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md)** (commands `BEGIN`, `SET`, `END`).
|
||||
The return value also matters: 0 = OK, 1 = FAILED.
|
||||
|
||||
5. The following global variables are available to be set:
|
||||
|
|
@ -76,7 +76,7 @@ For a module called `X`, the following criteria must be met:
|
|||
|
||||
The module script may use more functions or variables. But all of them must begin with `X_`.
|
||||
|
||||
The standard Netdata plugin variables are also available (check **[External Plugins](/collectors/plugins.d/README.md)**).
|
||||
The standard Netdata plugin variables are also available (check **[External Plugins](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md)**).
|
||||
|
||||
### X_check()
|
||||
|
||||
|
|
@ -90,7 +90,7 @@ connect to a local mysql database to find out if it can read the values it needs
|
|||
### X_create()
|
||||
|
||||
The purpose of the BASH function `X_create()` is to create the charts and dimensions using the standard Netdata
|
||||
plugin guides (**[External Plugins](/collectors/plugins.d/README.md)**).
|
||||
plugin guides (**[External Plugins](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md)**).
|
||||
|
||||
`X_create()` will be called just once and only after `X_check()` was successful.
|
||||
You can however call it yourself when there is need for it (for example to add a new dimension to an existing chart).
|
||||
|
|
@ -100,7 +100,7 @@ A non-zero return value will disable the collector.
|
|||
### X_update()
|
||||
|
||||
`X_update()` will be called repeatedly every `X_update_every` seconds, to collect new values and send them to Netdata,
|
||||
following the Netdata plugin guides (**[External Plugins](/collectors/plugins.d/README.md)**).
|
||||
following the Netdata plugin guides (**[External Plugins](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md)**).
|
||||
|
||||
The function will be called with one parameter: microseconds since the last time it was run. This value should be
|
||||
appended to the `BEGIN` statement of every chart updated by the collector script.
|
||||
|
|
|
|||
|
|
@ -86,7 +86,7 @@ Station 40:b8:37:5a:ed:5e (on wlan0)
|
|||
## Configuration
|
||||
|
||||
Edit the `charts.d/ap.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ Monitors different APC UPS models and retrieves status information using `apcacc
|
|||
## Configuration
|
||||
|
||||
Edit the `charts.d/apcupsd.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -25,7 +25,7 @@ The following charts are created, **per tunnel**:
|
|||
## Configuration
|
||||
|
||||
Edit the `charts.d/libreswan.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -54,7 +54,7 @@ The following charts will be created:
|
|||
## Configuration
|
||||
|
||||
Edit the `charts.d/nut.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ learn_rel_path: "References/Collectors references/Networking"
|
|||
## Configuration
|
||||
|
||||
Edit the `charts.d/opensips.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -31,7 +31,7 @@ One chart for every sensor chip found and each of the above will be created.
|
|||
## Enable the collector
|
||||
|
||||
The `sensors` collector is disabled by default. To enable it, edit the `charts.d.conf` file using `edit-config` from the
|
||||
Netdata [config directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
Netdata [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
@ -48,7 +48,7 @@ sensors=force
|
|||
## Configuration
|
||||
|
||||
Edit the `charts.d/sensors.conf` configuration file using `edit-config` from the
|
||||
Netdata [config directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
Netdata [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -42,6 +42,6 @@ Charts can be enabled/disabled for every mount separately:
|
|||
# inodes usage = auto
|
||||
```
|
||||
|
||||
> for disks performance monitoring, see the `proc` plugin, [here](/collectors/proc.plugin/README.md#monitoring-disks)
|
||||
> for disks performance monitoring, see the `proc` plugin, [here](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md#monitoring-disks)
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -15,7 +15,7 @@ The Netdata Agent provides many [eBPF](https://ebpf.io/what-is-ebpf/) programs t
|
|||
> ❗ eBPF monitoring only works on Linux systems and with specific Linux kernels, including all kernels newer than `4.11.0`, and all kernels on CentOS 7.6 or later. For kernels older than `4.11.0`, improved support is in active development.
|
||||
|
||||
This document provides comprehensive details about the `ebpf.plugin`.
|
||||
For hands-on configuration and troubleshooting tips see our [tutorial on troubleshooting apps with eBPF metrics](/docs/guides/troubleshoot/monitor-debug-applications-ebpf.md).
|
||||
For hands-on configuration and troubleshooting tips see our [tutorial on troubleshooting apps with eBPF metrics](https://github.com/netdata/netdata/blob/master/docs/guides/troubleshoot/monitor-debug-applications-ebpf.md).
|
||||
|
||||
<figure>
|
||||
<img src="https://user-images.githubusercontent.com/1153921/74746434-ad6a1e00-5222-11ea-858a-a7882617ae02.png" alt="An example of VFS charts, made possible by the eBPF collector plugin" />
|
||||
|
|
@ -44,12 +44,12 @@ If your Agent is v1.22 or older, you may to enable the collector yourself.
|
|||
|
||||
To enable or disable the entire eBPF collector:
|
||||
|
||||
1. Navigate to the [Netdata config directory](/docs/configure/nodes.md#the-netdata-config-directory).
|
||||
1. Navigate to the [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory).
|
||||
```bash
|
||||
cd /etc/netdata
|
||||
```
|
||||
|
||||
2. Use the [`edit-config`](/docs/configure/nodes.md#use-edit-config-to-edit-configuration-files) script to edit `netdata.conf`.
|
||||
2. Use the [`edit-config`](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#use-edit-config-to-edit-configuration-files) script to edit `netdata.conf`.
|
||||
|
||||
```bash
|
||||
./edit-config netdata.conf
|
||||
|
|
@ -69,11 +69,11 @@ You can configure the eBPF collector's behavior to fine-tune which metrics you r
|
|||
|
||||
To edit the `ebpf.d.conf`:
|
||||
|
||||
1. Navigate to the [Netdata config directory](/docs/configure/nodes.md#the-netdata-config-directory).
|
||||
1. Navigate to the [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory).
|
||||
```bash
|
||||
cd /etc/netdata
|
||||
```
|
||||
2. Use the [`edit-config`](/docs/configure/nodes.md#use-edit-config-to-edit-configuration-files) script to edit [`ebpf.d.conf`](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/ebpf.d.conf).
|
||||
2. Use the [`edit-config`](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#use-edit-config-to-edit-configuration-files) script to edit [`ebpf.d.conf`](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/ebpf.d.conf).
|
||||
|
||||
```bash
|
||||
./edit-config ebpf.d.conf
|
||||
|
|
@ -105,7 +105,7 @@ accepts the following values:
|
|||
#### Integration with `apps.plugin`
|
||||
|
||||
The eBPF collector also creates charts for each running application through an integration with the
|
||||
[`apps.plugin`](/collectors/apps.plugin/README.md). This integration helps you understand how specific applications
|
||||
[`apps.plugin`](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md). This integration helps you understand how specific applications
|
||||
interact with the Linux kernel.
|
||||
|
||||
If you want to enable `apps.plugin` integration, change the "apps" setting to "yes".
|
||||
|
|
@ -123,7 +123,7 @@ it runs.
|
|||
#### Integration with `cgroups.plugin`
|
||||
|
||||
The eBPF collector also creates charts for each cgroup through an integration with the
|
||||
[`cgroups.plugin`](/collectors/cgroups.plugin/README.md). This integration helps you understand how a specific cgroup
|
||||
[`cgroups.plugin`](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md). This integration helps you understand how a specific cgroup
|
||||
interacts with the Linux kernel.
|
||||
|
||||
The integration with `cgroups.plugin` is disabled by default to avoid creating overhead on your system. If you want to
|
||||
|
|
@ -245,7 +245,7 @@ The eBPF collector enables and runs the following eBPF programs by default:
|
|||
You can also enable the following eBPF programs:
|
||||
|
||||
- `cachestat`: Netdata's eBPF data collector creates charts about the memory page cache. When the integration with
|
||||
[`apps.plugin`](/collectors/apps.plugin/README.md) is enabled, this collector creates charts for the whole host _and_
|
||||
[`apps.plugin`](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md) is enabled, this collector creates charts for the whole host _and_
|
||||
for each application.
|
||||
- `dcstat` : This eBPF program creates charts that show information about file access using directory cache. It appends
|
||||
`kprobes` for `lookup_fast()` and `d_lookup()` to identify if files are inside directory cache, outside and files are
|
||||
|
|
@ -262,11 +262,11 @@ You can configure each thread of the eBPF data collector. This allows you to ove
|
|||
|
||||
To configure an eBPF thread:
|
||||
|
||||
1. Navigate to the [Netdata config directory](/docs/configure/nodes.md#the-netdata-config-directory).
|
||||
1. Navigate to the [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory).
|
||||
```bash
|
||||
cd /etc/netdata
|
||||
```
|
||||
2. Use the [`edit-config`](/docs/configure/nodes.md#use-edit-config-to-edit-configuration-files) script to edit a thread configuration file. The following configuration files are available:
|
||||
2. Use the [`edit-config`](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#use-edit-config-to-edit-configuration-files) script to edit a thread configuration file. The following configuration files are available:
|
||||
|
||||
- `network.conf`: Configuration for the [`network` thread](#network-configuration). This config file overwrites the global options and also
|
||||
lets you specify which network the eBPF collector monitors.
|
||||
|
|
@ -305,7 +305,7 @@ You can configure the information shown on `outbound` and `inbound` charts with
|
|||
|
||||
When you define a `ports` setting, Netdata will collect network metrics for that specific port. For example, if you
|
||||
write `ports = 19999`, Netdata will collect only connections for itself. The `hostnames` setting accepts
|
||||
[simple patterns](/libnetdata/simple_pattern/README.md). The `ports`, and `ips` settings accept negation (`!`) to deny
|
||||
[simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md). The `ports`, and `ips` settings accept negation (`!`) to deny
|
||||
specific values or asterisk alone to define all values.
|
||||
|
||||
In the above example, Netdata will collect metrics for all ports between 1 and 443, with the exception of 53 (domain)
|
||||
|
|
@ -882,7 +882,7 @@ significantly increases kernel memory usage by several hundred MB.
|
|||
|
||||
If your node is experiencing high memory usage and there is no obvious culprit to be found in the `apps.mem` chart,
|
||||
consider testing for high kernel memory usage by [disabling eBPF monitoring](#configuring-ebpfplugin). Next,
|
||||
[restart Netdata](/docs/configure/start-stop-restart.md) with `sudo systemctl restart netdata` to see if system memory
|
||||
[restart Netdata](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) with `sudo systemctl restart netdata` to see if system memory
|
||||
usage (see the `system.ram` chart) has dropped significantly.
|
||||
|
||||
Beginning with `v1.31`, kernel memory usage is configurable via the [`pid table size` setting](#ebpf-load-mode)
|
||||
|
|
|
|||
|
|
@ -16,18 +16,18 @@ from external processes, thus allowing Netdata to use **external plugins**.
|
|||
|
||||
|plugin|language|O/S|description|
|
||||
|:----:|:------:|:-:|:----------|
|
||||
|[apps.plugin](/collectors/apps.plugin/README.md)|`C`|linux, freebsd|monitors the whole process tree on Linux and FreeBSD and breaks down system resource usage by **process**, **user** and **user group**.|
|
||||
|[charts.d.plugin](/collectors/charts.d.plugin/README.md)|`BASH`|all|a **plugin orchestrator** for data collection modules written in `BASH` v4+.|
|
||||
|[cups.plugin](/collectors/cups.plugin/README.md)|`C`|all|monitors **CUPS**|
|
||||
|[apps.plugin](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md)|`C`|linux, freebsd|monitors the whole process tree on Linux and FreeBSD and breaks down system resource usage by **process**, **user** and **user group**.|
|
||||
|[charts.d.plugin](https://github.com/netdata/netdata/blob/master/collectors/charts.d.plugin/README.md)|`BASH`|all|a **plugin orchestrator** for data collection modules written in `BASH` v4+.|
|
||||
|[cups.plugin](https://github.com/netdata/netdata/blob/master/collectors/cups.plugin/README.md)|`C`|all|monitors **CUPS**|
|
||||
|[ebpf.plugin](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md)|`C`|linux|monitors different metrics on environments using kernel internal functions.|
|
||||
|[go.d.plugin](https://github.com/netdata/go.d.plugin/blob/master/README.md)|`GO`|all|collects metrics from the system, applications, or third-party APIs.|
|
||||
|[ioping.plugin](/collectors/ioping.plugin/README.md)|`C`|all|measures disk latency.|
|
||||
|[freeipmi.plugin](/collectors/freeipmi.plugin/README.md)|`C`|linux|collects metrics from enterprise hardware sensors, on Linux servers.|
|
||||
|[nfacct.plugin](/collectors/nfacct.plugin/README.md)|`C`|linux|collects netfilter firewall, connection tracker and accounting metrics using `libmnl` and `libnetfilter_acct`.|
|
||||
|[xenstat.plugin](/collectors/xenstat.plugin/README.md)|`C`|linux|collects XenServer and XCP-ng metrics using `lxenstat`.|
|
||||
|[perf.plugin](/collectors/perf.plugin/README.md)|`C`|linux|collects CPU performance metrics using performance monitoring units (PMU).|
|
||||
|[python.d.plugin](/collectors/python.d.plugin/README.md)|`python`|all|a **plugin orchestrator** for data collection modules written in `python` v2 or v3 (both are supported).|
|
||||
|[slabinfo.plugin](/collectors/slabinfo.plugin/README.md)|`C`|linux|collects kernel internal cache objects (SLAB) metrics.|
|
||||
|[ioping.plugin](https://github.com/netdata/netdata/blob/master/collectors/ioping.plugin/README.md)|`C`|all|measures disk latency.|
|
||||
|[freeipmi.plugin](https://github.com/netdata/netdata/blob/master/collectors/freeipmi.plugin/README.md)|`C`|linux|collects metrics from enterprise hardware sensors, on Linux servers.|
|
||||
|[nfacct.plugin](https://github.com/netdata/netdata/blob/master/collectors/nfacct.plugin/README.md)|`C`|linux|collects netfilter firewall, connection tracker and accounting metrics using `libmnl` and `libnetfilter_acct`.|
|
||||
|[xenstat.plugin](https://github.com/netdata/netdata/blob/master/collectors/xenstat.plugin/README.md)|`C`|linux|collects XenServer and XCP-ng metrics using `lxenstat`.|
|
||||
|[perf.plugin](https://github.com/netdata/netdata/blob/master/collectors/perf.plugin/README.md)|`C`|linux|collects CPU performance metrics using performance monitoring units (PMU).|
|
||||
|[python.d.plugin](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/README.md)|`python`|all|a **plugin orchestrator** for data collection modules written in `python` v2 or v3 (both are supported).|
|
||||
|[slabinfo.plugin](https://github.com/netdata/netdata/blob/master/collectors/slabinfo.plugin/README.md)|`C`|linux|collects kernel internal cache objects (SLAB) metrics.|
|
||||
|
||||
Plugin orchestrators may also be described as **modular plugins**. They are modular since they accept custom made modules to be included. Writing modules for these plugins is easier than accessing the native Netdata API directly. You will find modules already available for each orchestrator under the directory of the particular modular plugin (e.g. under python.d.plugin for the python orchestrator).
|
||||
Each of these modular plugins has each own methods for defining modules. Please check the examples and their documentation.
|
||||
|
|
@ -508,12 +508,12 @@ or do not output the line at all.
|
|||
## Modular Plugins
|
||||
|
||||
1. **python**, use `python.d.plugin`, there are many examples in the [python.d
|
||||
directory](/collectors/python.d.plugin/README.md)
|
||||
directory](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/README.md)
|
||||
|
||||
python is ideal for Netdata plugins. It is a simple, yet powerful way to collect data, it has a very small memory footprint, although it is not the most CPU efficient way to do it.
|
||||
|
||||
2. **BASH**, use `charts.d.plugin`, there are many examples in the [charts.d
|
||||
directory](/collectors/charts.d.plugin/README.md)
|
||||
directory](https://github.com/netdata/netdata/blob/master/collectors/charts.d.plugin/README.md)
|
||||
|
||||
BASH is the simplest scripting language for collecting values. It is the less efficient though in terms of CPU resources. You can use it to collect data quickly, but extensive use of it might use a lot of system resources.
|
||||
|
||||
|
|
|
|||
|
|
@ -404,7 +404,7 @@ You can set the following values for each configuration option:
|
|||
|
||||
There are several alarms defined in `health.d/net.conf`.
|
||||
|
||||
The tricky ones are `inbound packets dropped` and `inbound packets dropped ratio`. They have quite a strict policy so that they warn users about possible issues. These alarms can be annoying for some network configurations. It is especially true for some bonding configurations if an interface is a child or a bonding interface itself. If it is expected to have a certain number of drops on an interface for a certain network configuration, a separate alarm with different triggering thresholds can be created or the existing one can be disabled for this specific interface. It can be done with the help of the [families](/health/REFERENCE.md#alarm-line-families) line in the alarm configuration. For example, if you want to disable the `inbound packets dropped` alarm for `eth0`, set `families: !eth0 *` in the alarm definition for `template: inbound_packets_dropped`.
|
||||
The tricky ones are `inbound packets dropped` and `inbound packets dropped ratio`. They have quite a strict policy so that they warn users about possible issues. These alarms can be annoying for some network configurations. It is especially true for some bonding configurations if an interface is a child or a bonding interface itself. If it is expected to have a certain number of drops on an interface for a certain network configuration, a separate alarm with different triggering thresholds can be created or the existing one can be disabled for this specific interface. It can be done with the help of the [families](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alarm-line-families) line in the alarm configuration. For example, if you want to disable the `inbound packets dropped` alarm for `eth0`, set `families: !eth0 *` in the alarm definition for `template: inbound_packets_dropped`.
|
||||
|
||||
#### configuration
|
||||
|
||||
|
|
|
|||
|
|
@ -90,7 +90,7 @@ plugin](https://raw.githubusercontent.com/netdata/netdata/master/collectors/pyth
|
|||
Netdata (as opposed to having to install Netdata from source again with your new changes) to can copy over the relevant
|
||||
file to where Netdata expects it and then either `sudo systemctl restart netdata` to have it be picked up and used by
|
||||
Netdata or you can just run the updated collector in debug mode by following a process like below (this assumes you have
|
||||
[installed Netdata from a GitHub fork](https://learn.netdata.cloud/docs/agent/packaging/installer/methods/manual) you
|
||||
[installed Netdata from a GitHub fork](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/manual.md) you
|
||||
have made to do your development on).
|
||||
|
||||
```bash
|
||||
|
|
@ -129,7 +129,7 @@ CHART = {
|
|||
]}
|
||||
```
|
||||
|
||||
All names are better explained in the [External Plugins](/collectors/plugins.d/README.md) section.
|
||||
All names are better explained in the [External Plugins](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md) section.
|
||||
Parameters like `priority` and `update_every` are handled by `python.d.plugin`.
|
||||
|
||||
### `Service` class
|
||||
|
|
@ -231,7 +231,7 @@ For additional security it uses python `subprocess.Popen` (without `shell=True`
|
|||
|
||||
_Examples: `apache`, `nginx`, `tomcat`_
|
||||
|
||||
_Multiple Endpoints (urls) Examples: [`rabbitmq`](/collectors/python.d.plugin/rabbitmq/README.md) (simpler).
|
||||
_Multiple Endpoints (urls) Examples: [`rabbitmq`](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/rabbitmq/README.md) (simpler).
|
||||
|
||||
|
||||
_Variables from config file_: `url`, `user`, `pass`.
|
||||
|
|
|
|||
|
|
@ -55,7 +55,7 @@ systemctl restart netdata.service
|
|||
## Enable the collector
|
||||
|
||||
The `adaptec_raid` collector is disabled by default. To enable it, use `edit-config` from the
|
||||
Netdata [config directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`, to edit the `python.d.conf`
|
||||
Netdata [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`, to edit the `python.d.conf`
|
||||
file.
|
||||
|
||||
```bash
|
||||
|
|
@ -64,12 +64,12 @@ sudo ./edit-config python.d.conf
|
|||
```
|
||||
|
||||
Change the value of the `adaptec_raid` setting to `yes`. Save the file and restart the Netdata Agent with `sudo
|
||||
systemctl restart netdata`, or the [appropriate method](/docs/configure/start-stop-restart.md) for your system.
|
||||
systemctl restart netdata`, or the [appropriate method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system.
|
||||
|
||||
## Configuration
|
||||
|
||||
Edit the `python.d/adaptec_raid.conf` configuration file using `edit-config` from the
|
||||
Netdata [config directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
Netdata [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -26,7 +26,7 @@ Below is an example of the chart produced when running `stress-ng --all 2` for a
|
|||
|
||||
## Configuration
|
||||
|
||||
Enable the collector and [restart Netdata](/docs/configure/start-stop-restart.md).
|
||||
Enable the collector and [restart Netdata](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md).
|
||||
|
||||
```bash
|
||||
cd /etc/netdata/
|
||||
|
|
@ -36,7 +36,7 @@ sudo systemctl restart netdata
|
|||
```
|
||||
|
||||
If needed, edit the `python.d/alarms.conf` configuration file using `edit-config` from the your agent's [config
|
||||
directory](/docs/configure/nodes.md), which is usually at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is usually at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -24,7 +24,7 @@ It produces the following charts:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/am2320.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -11,7 +11,7 @@ learn_rel_path: "References/Collectors references/Misc"
|
|||
|
||||
# Anomaly detection with Netdata
|
||||
|
||||
**Note**: Check out the [Netdata Anomaly Advisor](https://learn.netdata.cloud/docs/cloud/insights/anomaly-advisor) for a more native anomaly detection experience within Netdata.
|
||||
**Note**: Check out the [Netdata Anomaly Advisor](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.mdx) for a more native anomaly detection experience within Netdata.
|
||||
|
||||
This collector uses the Python [PyOD](https://pyod.readthedocs.io/en/latest/index.html) library to perform unsupervised [anomaly detection](https://en.wikipedia.org/wiki/Anomaly_detection) on your Netdata charts and/or dimensions.
|
||||
|
||||
|
|
@ -74,7 +74,7 @@ The configuration for the anomalies collector defines how it will behave on your
|
|||
_**Note**: If you are unsure about any of the below configuration options then it's best to just ignore all this and leave the `anomalies.conf` file alone to begin with. Then you can return to it later if you would like to tune things a bit more once the collector is running for a while and you have a feeling for its performance on your node._
|
||||
|
||||
Edit the `python.d/anomalies.conf` configuration file using `edit-config` from the your agent's [config
|
||||
directory](/docs/configure/nodes.md), which is usually at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is usually at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
@ -220,7 +220,7 @@ If you would like to go deeper on what exactly the anomalies collector is doing
|
|||
|
||||
## Notes
|
||||
|
||||
- Python 3 is required as the [`netdata-pandas`](https://github.com/netdata/netdata-pandas) package uses Python async libraries ([asks](https://pypi.org/project/asks/) and [trio](https://pypi.org/project/trio/)) to make asynchronous calls to the [Netdata REST API](https://learn.netdata.cloud/docs/agent/web/api) to get the required data for each chart.
|
||||
- Python 3 is required as the [`netdata-pandas`](https://github.com/netdata/netdata-pandas) package uses Python async libraries ([asks](https://pypi.org/project/asks/) and [trio](https://pypi.org/project/trio/)) to make asynchronous calls to the [Netdata REST API](https://github.com/netdata/netdata/blob/master/web/api/README.md) to get the required data for each chart.
|
||||
- Python 3 is also required for the underlying ML libraries of [numba](https://pypi.org/project/numba/), [scikit-learn](https://pypi.org/project/scikit-learn/), and [PyOD](https://pypi.org/project/pyod/).
|
||||
- It may take a few hours or so (depending on your choice of `train_secs_n`) for the collector to 'settle' into it's typical behaviour in terms of the trained models and probabilities you will see in the normal running of your node.
|
||||
- As this collector does most of the work in Python itself, with [PyOD](https://pyod.readthedocs.io/en/latest/) leveraging [numba](https://numba.pydata.org/) under the hood, you may want to try it out first on a test or development system to get a sense of its performance characteristics on a node similar to where you would like to use it.
|
||||
|
|
@ -235,7 +235,7 @@ If you would like to go deeper on what exactly the anomalies collector is doing
|
|||
- If you activate this collector on a fresh node, it might take a little while to build up enough data to calculate a realistic and useful model.
|
||||
- Some models like `iforest` can be comparatively expensive (on same n1-standard-2 system above ~2s runtime during predict, ~40s training time, ~50% cpu on both train and predict) so if you would like to use it you might be advised to set a relatively high `update_every` maybe 10, 15 or 30 in `anomalies.conf`.
|
||||
- Setting a higher `train_every_n` and `update_every` is an easy way to devote less resources on the node to anomaly detection. Specifying less charts and a lower `train_n_secs` will also help reduce resources at the expense of covering less charts and maybe a more noisy model if you set `train_n_secs` to be too small for how your node tends to behave.
|
||||
- If you would like to enable this on a Raspberry Pi, then check out [this guide](https://learn.netdata.cloud/guides/monitor/raspberry-pi-anomaly-detection) which will guide you through first installing LLVM.
|
||||
- If you would like to enable this on a Raspberry Pi, then check out [this guide](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/raspberry-pi-anomaly-detection.md) which will guide you through first installing LLVM.
|
||||
|
||||
## Useful links and further reading
|
||||
|
||||
|
|
|
|||
|
|
@ -115,7 +115,7 @@ Provides server and tube-level statistics.
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/beanstalk.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -61,7 +61,7 @@ It produces:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/bind_rndc.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -16,7 +16,7 @@ It provides charts tracking the total number of tasks and active tasks, as well
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/boinc.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -31,7 +31,7 @@ Monitors the ceph cluster usage and consumption data of a server, and produces:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/ceph.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -97,7 +97,7 @@ leave the `changefinder.conf` file alone to begin with. Then you can return to i
|
|||
a bit more once the collector is running for a while and you have a feeling for its performance on your node._
|
||||
|
||||
Edit the `python.d/changefinder.conf` configuration file using `edit-config` from the your
|
||||
agent's [config directory](/docs/configure/nodes.md), which is usually at `/etc/netdata`.
|
||||
agent's [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is usually at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -81,7 +81,7 @@ Module gives information with following charts:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/dovecot.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -13,6 +13,6 @@ You can add custom data collectors using Python.
|
|||
|
||||
Netdata provides an [example python data collection module](https://github.com/netdata/netdata/tree/master/collectors/python.d.plugin/example).
|
||||
|
||||
If you want to write your own collector, read our [writing a new Python module](/collectors/python.d.plugin/README.md#how-to-write-a-new-module) tutorial.
|
||||
If you want to write your own collector, read our [writing a new Python module](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/README.md#how-to-write-a-new-module) tutorial.
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -61,7 +61,7 @@ To persist the changes after rotating the log file, add `create 640 root netdata
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/fail2ban.conf` configuration file using `edit-config` from the
|
||||
Netdata [config directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
Netdata [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -30,7 +30,7 @@ It produces:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/gearman.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -212,8 +212,8 @@ See [this issue](https://github.com/netdata/netdata/pull/1902#issuecomment-28449
|
|||
|
||||
Please see these two links to the official Netdata documentation for more information about the values:
|
||||
|
||||
- [External plugins - charts](/collectors/plugins.d/README.md#chart)
|
||||
- [Chart variables](/collectors/python.d.plugin/README.md#global-variables-order-and-chart)
|
||||
- [External plugins - charts](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md#chart)
|
||||
- [Chart variables](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/README.md#global-variables-order-and-chart)
|
||||
|
||||
**Line definitions**
|
||||
|
||||
|
|
@ -236,7 +236,7 @@ hidden: False
|
|||
```
|
||||
|
||||
Please see the following link for more information about the options and their default values:
|
||||
[External plugins - dimensions](/collectors/plugins.d/README.md#dimension)
|
||||
[External plugins - dimensions](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md#dimension)
|
||||
|
||||
Apart from top-level expvars, this plugin can also parse expvars stored in a multi-level map;
|
||||
All dicts in the resulting JSON document are then flattened to one level.
|
||||
|
|
@ -258,7 +258,7 @@ the first defined key wins and all subsequent keys with the same name are ignore
|
|||
## Enable the collector
|
||||
|
||||
The `go_expvar` collector is disabled by default. To enable it, use `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`, to edit the `python.d.conf` file.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`, to edit the `python.d.conf` file.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
@ -271,7 +271,7 @@ restart netdata`, or the appropriate method for your system, to finish enabling
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/go_expvar.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -42,7 +42,7 @@ It produces:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/haproxy.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -19,7 +19,7 @@ It produces one chart **Temperature** with dynamic number of dimensions (one per
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/hddtemp.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -54,7 +54,7 @@ systemctl restart netdata.service
|
|||
## Enable the collector
|
||||
|
||||
The `hpssa` collector is disabled by default. To enable it, use `edit-config` from the
|
||||
Netdata [config directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`, to edit the `python.d.conf`
|
||||
Netdata [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`, to edit the `python.d.conf`
|
||||
file.
|
||||
|
||||
```bash
|
||||
|
|
@ -63,12 +63,12 @@ sudo ./edit-config python.d.conf
|
|||
```
|
||||
|
||||
Change the value of the `hpssa` setting to `yes`. Save the file and restart the Netdata Agent with `sudo systemctl
|
||||
restart netdata`, or the [appropriate method](/docs/configure/start-stop-restart.md) for your system.
|
||||
restart netdata`, or the [appropriate method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system.
|
||||
|
||||
## Configuration
|
||||
|
||||
Edit the `python.d/hpssa.conf` configuration file using `edit-config` from the
|
||||
Netdata [config directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
Netdata [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
@ -82,5 +82,5 @@ ssacli_path: /usr/sbin/ssacli
|
|||
```
|
||||
|
||||
Save the file and restart the Netdata Agent with `sudo systemctl restart netdata`, or the [appropriate
|
||||
method](/docs/configure/start-stop-restart.md) for your system.
|
||||
method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system.
|
||||
|
||||
|
|
|
|||
|
|
@ -24,7 +24,7 @@ It produces the following charts:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/icecast.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -23,7 +23,7 @@ It produces the following charts:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/ipfs.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -56,7 +56,7 @@ It produces:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/litespeed.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -56,7 +56,7 @@ systemctl restart netdata.service
|
|||
## Enable the collector
|
||||
|
||||
The `megacli` collector is disabled by default. To enable it, use `edit-config` from the
|
||||
Netdata [config directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`, to edit the `python.d.conf`
|
||||
Netdata [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`, to edit the `python.d.conf`
|
||||
file.
|
||||
|
||||
```bash
|
||||
|
|
@ -70,7 +70,7 @@ with `sudo systemctl restart netdata`, or the appropriate method for your system
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/megacli.conf` configuration file using `edit-config` from the
|
||||
Netdata [config directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
Netdata [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
@ -84,6 +84,6 @@ do_battery: yes
|
|||
```
|
||||
|
||||
Save the file and restart the Netdata Agent with `sudo systemctl restart netdata`, or the [appropriate
|
||||
method](/docs/configure/start-stop-restart.md) for your system.
|
||||
method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system.
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -79,7 +79,7 @@ Collects memory-caching system performance metrics. It reads server response to
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/memcached.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -9,29 +9,32 @@ learn_rel_path: "References/Collectors references/Storage"
|
|||
|
||||
# Monit monitoring with Netdata
|
||||
|
||||
Monit monitoring module. Data is grabbed from stats XML interface (exists for a long time, but not mentioned in official documentation). Mostly this plugin shows statuses of monit targets, i.e. [statuses of specified checks](https://mmonit.com/monit/documentation/monit.html#Service-checks).
|
||||
Monit monitoring module. Data is grabbed from stats XML interface (exists for a long time, but not mentioned in official
|
||||
documentation). Mostly this plugin shows statuses of monit targets, i.e.
|
||||
[statuses of specified checks](https://mmonit.com/monit/documentation/monit.html#Service-checks).
|
||||
|
||||
1. **Filesystems**
|
||||
1. **Filesystems**
|
||||
|
||||
- Filesystems
|
||||
- Directories
|
||||
- Files
|
||||
- Pipes
|
||||
- Filesystems
|
||||
- Directories
|
||||
- Files
|
||||
- Pipes
|
||||
|
||||
2. **Applications**
|
||||
2. **Applications**
|
||||
|
||||
- Processes (+threads/childs)
|
||||
- Programs
|
||||
- Processes (+threads/childs)
|
||||
- Programs
|
||||
|
||||
3. **Network**
|
||||
3. **Network**
|
||||
|
||||
- Hosts (+latency)
|
||||
- Network interfaces
|
||||
- Hosts (+latency)
|
||||
- Network interfaces
|
||||
|
||||
## Configuration
|
||||
|
||||
Edit the `python.d/monit.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
Edit the `python.d/monit.conf` configuration file using `edit-config` from the
|
||||
Netdata [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically
|
||||
at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
@ -42,10 +45,10 @@ Sample:
|
|||
|
||||
```yaml
|
||||
local:
|
||||
name : 'local'
|
||||
url : 'http://localhost:2812'
|
||||
user: : admin
|
||||
pass: : monit
|
||||
name: 'local'
|
||||
url: 'http://localhost:2812'
|
||||
user: : admin
|
||||
pass: : monit
|
||||
```
|
||||
|
||||
If no configuration is given, module will attempt to connect to monit as `http://localhost:2812`.
|
||||
|
|
|
|||
|
|
@ -11,7 +11,7 @@ learn_rel_path: "References/Collectors references/Devices"
|
|||
|
||||
Monitors performance metrics (memory usage, fan speed, pcie bandwidth utilization, temperature, etc.) using `nvidia-smi` cli tool.
|
||||
|
||||
> **Warning**: this collector does not work when the Netdata Agent is [running in a container](https://learn.netdata.cloud/docs/agent/packaging/docker).
|
||||
> **Warning**: this collector does not work when the Netdata Agent is [running in a container](https://github.com/netdata/netdata/blob/master/packaging/docker/README.md).
|
||||
|
||||
|
||||
## Requirements and Notes
|
||||
|
|
@ -51,7 +51,7 @@ It produces the following charts:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/nvidia_smi.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -59,7 +59,7 @@ Statistics are taken from LDAP monitoring interface. Manual page, slapd-monitor(
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/openldap.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -74,7 +74,7 @@ GRANT SELECT_CATALOG_ROLE TO netdata;
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/oracledb.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -36,7 +36,7 @@ Following charts are drawn:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/puppet.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -96,7 +96,7 @@ Per Vhost charts:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/rabbitmq.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -13,27 +13,28 @@ Collects database server and cluster statistics.
|
|||
|
||||
Following charts are drawn:
|
||||
|
||||
1. **Connected Servers**
|
||||
1. **Connected Servers**
|
||||
|
||||
- connected
|
||||
- missing
|
||||
- connected
|
||||
- missing
|
||||
|
||||
2. **Active Clients**
|
||||
2. **Active Clients**
|
||||
|
||||
- active
|
||||
- active
|
||||
|
||||
3. **Queries** per second
|
||||
3. **Queries** per second
|
||||
|
||||
- queries
|
||||
- queries
|
||||
|
||||
4. **Documents** per second
|
||||
4. **Documents** per second
|
||||
|
||||
- documents
|
||||
- documents
|
||||
|
||||
## Configuration
|
||||
|
||||
Edit the `python.d/rethinkdbs.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
Edit the `python.d/rethinkdbs.conf` configuration file using `edit-config` from the
|
||||
Netdata [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically
|
||||
at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
@ -42,11 +43,11 @@ sudo ./edit-config python.d/rethinkdbs.conf
|
|||
|
||||
```yaml
|
||||
localhost:
|
||||
name : 'local'
|
||||
host : '127.0.0.1'
|
||||
port : 28015
|
||||
user : "user"
|
||||
password : "pass"
|
||||
name: 'local'
|
||||
host: '127.0.0.1'
|
||||
port: 28015
|
||||
user: "user"
|
||||
password: "pass"
|
||||
```
|
||||
|
||||
When no configuration file is found, module tries to connect to `127.0.0.1:28015`.
|
||||
|
|
|
|||
|
|
@ -25,7 +25,7 @@ This module produces the following charts:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/retroshare.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -106,7 +106,7 @@ listed
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/riakkv.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -98,7 +98,7 @@ systemctl restart netdata.service
|
|||
## Enable the collector
|
||||
|
||||
The `samba` collector is disabled by default. To enable it, use `edit-config` from the
|
||||
Netdata [config directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`, to edit the `python.d.conf`
|
||||
Netdata [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`, to edit the `python.d.conf`
|
||||
file.
|
||||
|
||||
```bash
|
||||
|
|
@ -107,12 +107,12 @@ sudo ./edit-config python.d.conf
|
|||
```
|
||||
|
||||
Change the value of the `samba` setting to `yes`. Save the file and restart the Netdata Agent with `sudo systemctl
|
||||
restart netdata`, or the [appropriate method](/docs/configure/start-stop-restart.md) for your system.
|
||||
restart netdata`, or the [appropriate method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system.
|
||||
|
||||
## Configuration
|
||||
|
||||
Edit the `python.d/samba.conf` configuration file using `edit-config` from the
|
||||
Netdata [config directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
Netdata [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -16,7 +16,7 @@ Charts are created dynamically.
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/sensors.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
@ -29,7 +29,7 @@ There have been reports from users that on certain servers, ACPI ring buffer err
|
|||
We are tracking such cases in issue [#827](https://github.com/netdata/netdata/issues/827).
|
||||
Please join this discussion for help.
|
||||
|
||||
When `lm-sensors` doesn't work on your device (e.g. for RPi temperatures), use [the legacy bash collector](https://learn.netdata.cloud/docs/agent/collectors/charts.d.plugin/sensors)
|
||||
When `lm-sensors` doesn't work on your device (e.g. for RPi temperatures), use [the legacy bash collector](https://github.com/netdata/netdata/blob/master/collectors/charts.d.plugin/sensors/README.md)
|
||||
|
||||
---
|
||||
|
||||
|
|
|
|||
|
|
@ -109,7 +109,7 @@ Otherwise, all the smartd `.csv` files may get written to `/var/lib/smartmontool
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/smartd_log.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -21,7 +21,7 @@ the data returned by the `tps` or `list` console commands.
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/spigotmc.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -38,7 +38,7 @@ It produces following charts:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/squid.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -33,7 +33,7 @@ Charts:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/tomcat.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -26,7 +26,7 @@ It produces only one chart:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/tor.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -13,45 +13,46 @@ Uses the `health` API to provide statistics.
|
|||
|
||||
It produces:
|
||||
|
||||
1. **Responses** by statuses
|
||||
1. **Responses** by statuses
|
||||
|
||||
- success (1xx, 2xx, 304)
|
||||
- error (5xx)
|
||||
- redirect (3xx except 304)
|
||||
- bad (4xx)
|
||||
- other (all other responses)
|
||||
- success (1xx, 2xx, 304)
|
||||
- error (5xx)
|
||||
- redirect (3xx except 304)
|
||||
- bad (4xx)
|
||||
- other (all other responses)
|
||||
|
||||
2. **Responses** by codes
|
||||
2. **Responses** by codes
|
||||
|
||||
- 2xx (successful)
|
||||
- 5xx (internal server errors)
|
||||
- 3xx (redirect)
|
||||
- 4xx (bad)
|
||||
- 1xx (informational)
|
||||
- other (non-standart responses)
|
||||
- 2xx (successful)
|
||||
- 5xx (internal server errors)
|
||||
- 3xx (redirect)
|
||||
- 4xx (bad)
|
||||
- 1xx (informational)
|
||||
- other (non-standart responses)
|
||||
|
||||
3. **Detailed Response Codes** requests/s (number of responses for each response code family individually)
|
||||
3. **Detailed Response Codes** requests/s (number of responses for each response code family individually)
|
||||
|
||||
4. **Requests**/s
|
||||
4. **Requests**/s
|
||||
|
||||
- request statistics
|
||||
- request statistics
|
||||
|
||||
5. **Total response time**
|
||||
5. **Total response time**
|
||||
|
||||
- sum of all response time
|
||||
- sum of all response time
|
||||
|
||||
6. **Average response time**
|
||||
6. **Average response time**
|
||||
|
||||
7. **Average response time per iteration**
|
||||
7. **Average response time per iteration**
|
||||
|
||||
8. **Uptime**
|
||||
8. **Uptime**
|
||||
|
||||
- Traefik server uptime
|
||||
- Traefik server uptime
|
||||
|
||||
## Configuration
|
||||
|
||||
Edit the `python.d/traefik.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
Edit the `python.d/traefik.conf` configuration file using `edit-config` from the
|
||||
Netdata [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically
|
||||
at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
@ -63,11 +64,11 @@ Needs only `url` to server's `health`
|
|||
Here is an example for local server:
|
||||
|
||||
```yaml
|
||||
update_every : 1
|
||||
priority : 60000
|
||||
update_every: 1
|
||||
priority: 60000
|
||||
|
||||
local:
|
||||
url : 'http://localhost:8080/health'
|
||||
url: 'http://localhost:8080/health'
|
||||
```
|
||||
|
||||
Without configuration, module attempts to connect to `http://localhost:8080/health`.
|
||||
|
|
|
|||
|
|
@ -32,7 +32,7 @@ Following charts are drawn:
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/uwsgi.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -48,7 +48,7 @@ For every storage (SMF, SMA, or MSE):
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/varnish.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -19,7 +19,7 @@ Charts are created dynamically based on the number of detected sensors.
|
|||
## Configuration
|
||||
|
||||
Edit the `python.d/w1sensor.conf` configuration file using `edit-config` from the Netdata [config
|
||||
directory](/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md), which is typically at `/etc/netdata`.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory, if different
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ learn_rel_path: "References/Collectors references/Uncategorized"
|
|||
|
||||
Smoothed, rolling [Z-Scores](https://en.wikipedia.org/wiki/Standard_score) for selected metrics or charts.
|
||||
|
||||
This collector uses the [Netdata rest api](https://learn.netdata.cloud/docs/agent/web/api) to get the `mean` and `stddev`
|
||||
This collector uses the [Netdata rest api](https://github.com/netdata/netdata/blob/master/web/api/README.md) to get the `mean` and `stddev`
|
||||
for each dimension on specified charts over a time range (defined by `train_secs` and `offset_secs`). For each dimension
|
||||
it will calculate a Z-Score as `z = (x - mean) / stddev` (clipped at `z_clip`). Scores are then smoothed over
|
||||
time (`z_smooth_n`) and, if `mode: 'per_chart'`, aggregated across dimensions to a smoothed, rolling chart level Z-Score
|
||||
|
|
|
|||
|
|
@ -29,11 +29,11 @@ On synthetic charts, we can have alarms as with any metric and chart.
|
|||
|
||||
- [K6 load testing tool](https://k6.io)
|
||||
- **Description:** k6 is a developer-centric, free and open-source load testing tool built for making performance testing a productive and enjoyable experience.
|
||||
- [Documentation](/collectors/statsd.plugin/k6.md)
|
||||
- [Documentation](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/k6.md)
|
||||
- [Configuration](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/k6.conf)
|
||||
- [Asterisk](https://www.asterisk.org/)
|
||||
- **Description:** Asterisk is an Open Source PBX and telephony toolkit.
|
||||
- [Documentation](/collectors/statsd.plugin/asterisk.md)
|
||||
- [Documentation](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/asterisk.md)
|
||||
- [Configuration](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/asterisk.conf)
|
||||
|
||||
## Metrics supported by Netdata
|
||||
|
|
@ -206,7 +206,7 @@ Netdata can visualize StatsD collected metrics in 2 ways:
|
|||
|
||||
### Private metric charts
|
||||
|
||||
Private charts are controlled with `create private charts for metrics matching = *`. This setting accepts a space-separated list of [simple patterns](/libnetdata/simple_pattern/README.md). Netdata will create private charts for all metrics **by default**.
|
||||
Private charts are controlled with `create private charts for metrics matching = *`. This setting accepts a space-separated list of [simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md). Netdata will create private charts for all metrics **by default**.
|
||||
|
||||
For example, to render charts for all `myapp.*` metrics, except `myapp.*.badmetric`, use:
|
||||
|
||||
|
|
@ -214,7 +214,7 @@ For example, to render charts for all `myapp.*` metrics, except `myapp.*.badmetr
|
|||
create private charts for metrics matching = !myapp.*.badmetric myapp.*
|
||||
```
|
||||
|
||||
You can specify Netdata StatsD to have a different `memory mode` than the rest of the Netdata Agent. You can read more about `memory mode` in the [documentation](/database/README.md).
|
||||
You can specify Netdata StatsD to have a different `memory mode` than the rest of the Netdata Agent. You can read more about `memory mode` in the [documentation](https://github.com/netdata/netdata/blob/master/database/README.md).
|
||||
|
||||
The default behavior is to use the same settings as the rest of the Netdata Agent. If you wish to change them, edit the following settings:
|
||||
- `private charts memory mode`
|
||||
|
|
@ -293,7 +293,7 @@ Synthetic charts are organized in
|
|||
- **charts for each application** aka family in Netdata Dashboard.
|
||||
- **StatsD metrics for each chart** /aka charts and context Netdata Dashboard.
|
||||
|
||||
> You can read more about how the Netdata Agent organizes information in the relevant [documentation](/web/README.md)
|
||||
> You can read more about how the Netdata Agent organizes information in the relevant [documentation](https://github.com/netdata/netdata/blob/master/web/README.md)
|
||||
|
||||
For each application you need to create a `.conf` file in `/etc/netdata/statsd.d`.
|
||||
|
||||
|
|
@ -330,7 +330,7 @@ Using the above configuration `myapp` should get its own section on the dashboar
|
|||
`[app]` starts a new application definition. The supported settings in this section are:
|
||||
|
||||
- `name` defines the name of the app.
|
||||
- `metrics` is a Netdata [simple pattern](/libnetdata/simple_pattern/README.md). This pattern should match all the possible StatsD metrics that will be participating in the application `myapp`.
|
||||
- `metrics` is a Netdata [simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md). This pattern should match all the possible StatsD metrics that will be participating in the application `myapp`.
|
||||
- `private charts = yes|no`, enables or disables private charts for the metrics matched.
|
||||
- `gaps when not collected = yes|no`, enables or disables gaps on the charts of the application in case that no metrics are collected.
|
||||
- `memory mode` sets the memory mode for all charts of the application. The default is the global default for Netdata (not the global default for StatsD private charts). We suggest not to use this (we have commented it out in the example) and let your app use the global default for Netdata, which is our dbengine.
|
||||
|
|
@ -356,7 +356,7 @@ So, the format is this:
|
|||
dimension = [pattern] METRIC NAME TYPE MULTIPLIER DIVIDER OPTIONS
|
||||
```
|
||||
|
||||
`pattern` is a keyword. When set, `METRIC` is expected to be a Netdata [simple pattern](/libnetdata/simple_pattern/README.md) that will be used to match all the StatsD metrics to be added to the chart. So, `pattern` automatically matches any number of StatsD metrics, all of which will be added as separate chart dimensions.
|
||||
`pattern` is a keyword. When set, `METRIC` is expected to be a Netdata [simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) that will be used to match all the StatsD metrics to be added to the chart. So, `pattern` automatically matches any number of StatsD metrics, all of which will be added as separate chart dimensions.
|
||||
|
||||
`TYPE`, `MULTIPLIER`, `DIVIDER` and `OPTIONS` are optional.
|
||||
|
||||
|
|
|
|||
|
|
@ -71,7 +71,7 @@ QoS is about 2 features:
|
|||
|
||||
When your system is under a DDoS attack, it will get a lot more bandwidth compared to the one it can handle and probably your applications will crash. Setting a limit on the inbound traffic using QoS, will protect your servers (throttle the requests) and depending on the size of the attack may allow your legitimate users to access the server, while the attack is taking place.
|
||||
|
||||
Using QoS together with a [SYNPROXY](/collectors/proc.plugin/README.md) will provide a great degree of protection against most DDoS attacks. Actually when I wrote that article, a few folks tried to DDoS the Netdata demo site to see in real-time the SYNPROXY operation. They did not do it right, but anyway a great deal of requests reached the Netdata server. What saved Netdata was QoS. The Netdata demo server has QoS installed, so the requests were throttled and the server did not even reach the point of resource starvation. Read about it [here](/collectors/proc.plugin/README.md).
|
||||
Using QoS together with a [SYNPROXY](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md) will provide a great degree of protection against most DDoS attacks. Actually when I wrote that article, a few folks tried to DDoS the Netdata demo site to see in real-time the SYNPROXY operation. They did not do it right, but anyway a great deal of requests reached the Netdata server. What saved Netdata was QoS. The Netdata demo server has QoS installed, so the requests were throttled and the server did not even reach the point of resource starvation. Read about it [here](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md).
|
||||
|
||||
On top of all these, QoS is extremely light. You will configure it once, and this is it. It will not bother you again and it will not use any noticeable CPU resources, especially on application and database servers.
|
||||
|
||||
|
|
|
|||
|
|
@ -23,7 +23,7 @@ An unsynchronized clock may indicate a hardware clock error, or an issue with UT
|
|||
|
||||
## Configuration
|
||||
|
||||
Edit the `netdata.conf` configuration file using [`edit-config`](/docs/configure/nodes.md#use-edit-config-to-edit-configuration-files) from the [Netdata config directory](/docs/configure/nodes.md#the-netdata-config-directory), which is typically at `/etc/netdata`.
|
||||
Edit the `netdata.conf` configuration file using [`edit-config`](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#use-edit-config-to-edit-configuration-files) from the [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory), which is typically at `/etc/netdata`.
|
||||
|
||||
Scroll down to the `[plugin:timex]` section to find the available options:
|
||||
|
||||
|
|
|
|||
|
|
@ -2,40 +2,52 @@
|
|||
|
||||
Welcome to our docs developer guidelines!
|
||||
|
||||
We store documentation related to Netdata inside of the [`netdata/netdata` repository](https://github.com/netdata/netdata) on GitHub.
|
||||
We store documentation related to Netdata inside of
|
||||
the [`netdata/netdata` repository](https://github.com/netdata/netdata) on GitHub.
|
||||
|
||||
The Netdata team aggregates and publishes all documentation at [learn.netdata.cloud](/) using
|
||||
[Docusaurus](https://v2.docusaurus.io/) over at the [`netdata/learn` repository](https://github.com/netdata/learn).
|
||||
|
||||
## Before you get started
|
||||
|
||||
Anyone interested in contributing to documentation should first read the [Netdata style guide](#styling-guide) further down below and the [Netdata Community Code of Conduct](/contribute/code-of-conduct).
|
||||
Anyone interested in contributing to documentation should first read the [Netdata style guide](#styling-guide) further
|
||||
down below and the [Netdata Community Code of Conduct](https://github.com/netdata/.github/blob/main/CODE_OF_CONDUCT.md).
|
||||
|
||||
Netdata's documentation uses Markdown syntax. If you're not familiar with Markdown, read the [Mastering Markdown](https://guides.github.com/features/mastering-markdown/) guide from GitHub for the basics on creating paragraphs, styled text, lists, tables, and more, and read further down about some special occasions [while writing in MDX](#mdx-and-markdown).
|
||||
Netdata's documentation uses Markdown syntax. If you're not familiar with Markdown, read
|
||||
the [Mastering Markdown](https://guides.github.com/features/mastering-markdown/) guide from GitHub for the basics on
|
||||
creating paragraphs, styled text, lists, tables, and more, and read further down about some special
|
||||
occasions [while writing in MDX](#mdx-and-markdown).
|
||||
|
||||
### Netdata's Documentation structure
|
||||
|
||||
Netdata's documentation is separated into 5 categories.
|
||||
|
||||
- **Getting Started**: This section’s purpose is to present “What is Netdata” and for whom is it for while also presenting all the ways Netdata can be deployed. That includes Netdata’s platform support, Standalone deployment, Parent-child deployments, deploying on Kubernetes and also deploying on IoT nodes.
|
||||
- Stored in **WIP**
|
||||
- Published in **WIP**
|
||||
- **Concepts**: This section’s purpose is to take a pitch on all the aspects of Netdata. We present the functionality of each component/idea and support it with examples but we don’t go deep into technical details.
|
||||
- Stored in the `/docs/concepts` directory in the `netdata/netdata` repository.
|
||||
- Published in **WIP**
|
||||
- **Tasks**: This section's purpose is to break down any operation into a series of fundamental tasks for the Netdata solution.
|
||||
- Stored in the `/docs/tasks` directory in the `netdata/netdata` repository.
|
||||
- Published in **WIP**
|
||||
- **References**: This section’s purpose is to explain thoroughly every part of Netdata. That covers settings, configurations and so on.
|
||||
- Stored near the component they refer to.
|
||||
- Published in **WIP**
|
||||
- **Collectors References**: This section’s purpose is to explain thoroughly every collector that Netdata supports and it's configuration options.
|
||||
- Stored in stored near the collector they refer to.
|
||||
- Published in **WIP**
|
||||
- **Getting Started**: This section’s purpose is to present “What is Netdata” and for whom is it for while also
|
||||
presenting all the ways Netdata can be deployed. That includes Netdata’s platform support, Standalone deployment,
|
||||
Parent-child deployments, deploying on Kubernetes and also deploying on IoT nodes.
|
||||
- Stored in **WIP**
|
||||
- Published in **WIP**
|
||||
- **Concepts**: This section’s purpose is to take a pitch on all the aspects of Netdata. We present the functionality of
|
||||
each component/idea and support it with examples but we don’t go deep into technical details.
|
||||
- Stored in the `/docs/concepts` directory in the `netdata/netdata` repository.
|
||||
- Published in **WIP**
|
||||
- **Tasks**: This section's purpose is to break down any operation into a series of fundamental tasks for the Netdata
|
||||
solution.
|
||||
- Stored in the `/docs/tasks` directory in the `netdata/netdata` repository.
|
||||
- Published in **WIP**
|
||||
- **References**: This section’s purpose is to explain thoroughly every part of Netdata. That covers settings,
|
||||
configurations and so on.
|
||||
- Stored near the component they refer to.
|
||||
- Published in **WIP**
|
||||
- **Collectors References**: This section’s purpose is to explain thoroughly every collector that Netdata supports and
|
||||
it's configuration options.
|
||||
- Stored in stored near the collector they refer to.
|
||||
- Published in **WIP**
|
||||
|
||||
## How to contribute
|
||||
|
||||
The easiest way to contribute to Netdata's documentation is to edit a file directly on GitHub. This is perfect for small fixes to a single document, such as fixing a typo or clarifying a confusing sentence.
|
||||
The easiest way to contribute to Netdata's documentation is to edit a file directly on GitHub. This is perfect for small
|
||||
fixes to a single document, such as fixing a typo or clarifying a confusing sentence.
|
||||
|
||||
Click on the **Edit this page** button on any published document on [Netdata Learn](https://learn.netdata.cloud). Each
|
||||
page has two of these buttons: One beneath the table of contents, and another at the end of the document, which take you
|
||||
|
|
@ -49,28 +61,39 @@ Jump down to our instructions on [PRs](#making-a-pull-request) for your next ste
|
|||
|
||||
### Edit locally
|
||||
|
||||
Editing documentation locally is the preferred method for complex changes that span multiple documents or change the documentation's style or structure.
|
||||
Editing documentation locally is the preferred method for complex changes that span multiple documents or change the
|
||||
documentation's style or structure.
|
||||
|
||||
Create a fork of the Netdata Agent repository by visit the [Netdata repository](https://github.com/netdata/netdata) and clicking on the **Fork** button.
|
||||
Create a fork of the Netdata Agent repository by visit the [Netdata repository](https://github.com/netdata/netdata) and
|
||||
clicking on the **Fork** button.
|
||||
|
||||
GitHub will ask you where you want to clone the repository. When finished, you end up at the index of your forked Netdata Agent repository. Clone your fork to your local machine:
|
||||
GitHub will ask you where you want to clone the repository. When finished, you end up at the index of your forked
|
||||
Netdata Agent repository. Clone your fork to your local machine:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/YOUR-GITHUB-USERNAME/netdata.git
|
||||
```
|
||||
|
||||
Create a new branch using `git checkout -b BRANCH-NAME`. Use your favorite text editor to make your changes, keeping the [Netdata style guide](/contribute/style-guide) in mind. Add, commit, and push changes to your fork. When you're finished, visit the [Netdata Agent Pull requests](https://github.com/netdata/netdata/pulls) to create a new pull request based on the changes you made in the new branch of your fork.
|
||||
Create a new branch using `git checkout -b BRANCH-NAME`. Use your favorite text editor to make your changes, keeping
|
||||
the [Netdata style guide](https://github.com/netdata/netdata/blob/master/docs/contributing/style-guide.md) in mind. Add, commit, and push changes to your fork. When you're
|
||||
finished, visit the [Netdata Agent Pull requests](https://github.com/netdata/netdata/pulls) to create a new pull request
|
||||
based on the changes you made in the new branch of your fork.
|
||||
|
||||
### Making a pull request
|
||||
|
||||
Pull requests (PRs) should be concise and informative. See our [PR guidelines](/contribute/handbook#pr-guidelines) for specifics.
|
||||
Pull requests (PRs) should be concise and informative. See our [PR guidelines](/contribute/handbook#pr-guidelines) for
|
||||
specifics.
|
||||
|
||||
- The title must follow the [imperative mood](https://en.wikipedia.org/wiki/Imperative_mood) and be no more than ~50 characters.
|
||||
- The description should explain what was changed and why. Verify that you tested any code or processes that you are trying to change.
|
||||
- The title must follow the [imperative mood](https://en.wikipedia.org/wiki/Imperative_mood) and be no more than ~50
|
||||
characters.
|
||||
- The description should explain what was changed and why. Verify that you tested any code or processes that you are
|
||||
trying to change.
|
||||
|
||||
The Netdata team will review your PR and assesses it for correctness, conciseness, and overall quality. We may point to specific sections and ask for additional information or other fixes.
|
||||
The Netdata team will review your PR and assesses it for correctness, conciseness, and overall quality. We may point to
|
||||
specific sections and ask for additional information or other fixes.
|
||||
|
||||
After merging your PR, the Netdata team rebuilds the [documentation site](https://learn.netdata.cloud) to publish the changed documentation.
|
||||
After merging your PR, the Netdata team rebuilds the [documentation site](https://learn.netdata.cloud) to publish the
|
||||
changed documentation.
|
||||
|
||||
## Writing Docs
|
||||
|
||||
|
|
@ -78,34 +101,43 @@ We have three main types of Docs: **References**, **Concepts** and **Tasks**.
|
|||
|
||||
### Metadata Tags
|
||||
|
||||
|
||||
All of the Docs however have what we call "metadata" tags. these help to organize the document upon publishing.
|
||||
|
||||
So let's go through the different necessary metadata tags to get a document properly published on Learn:
|
||||
|
||||
- Docusaurus Specific:\
|
||||
These metadata tags are parsed automatically by Docusaurus and are rendered in the published document. **Note**: Netdata only uses the Docusaurus metadata tags releveant for our documentation infrastructure.
|
||||
- `title: "The title of the document"` : Here we specify the title of our document, which is going to be converted to the heading of the published page.
|
||||
- `description: "The description of the file"`: Here we give a description of what this file is about.
|
||||
- `custom_edit_url: https://github.com/netdata/netdata/edit/master/collectors/COLLECTORS.md`: Here is an example of the link that the user will be redirected to if he clicks the "Edit this page button", as you see it leads directly to the edit page of the source file.
|
||||
These metadata tags are parsed automatically by Docusaurus and are rendered in the published document. **Note**:
|
||||
Netdata only uses the Docusaurus metadata tags releveant for our documentation infrastructure.
|
||||
- `title: "The title of the document"` : Here we specify the title of our document, which is going to be converted
|
||||
to the heading of the published page.
|
||||
- `description: "The description of the file"`: Here we give a description of what this file is about.
|
||||
- `custom_edit_url: https://github.com/netdata/netdata/edit/master/collectors/COLLECTORS.md`: Here is an example of
|
||||
the link that the user will be redirected to if he clicks the "Edit this page button", as you see it leads
|
||||
directly to the edit page of the source file.
|
||||
- Netdata Learn specific:
|
||||
- `learn_status: "..."`
|
||||
- The options for this tag are:
|
||||
- `"published"`
|
||||
- `"unpublished"`
|
||||
- `learn_topic_type: "..."`
|
||||
- The options for this tag are:
|
||||
- `"Getting Started"`
|
||||
- `"Concepts"`
|
||||
- `"Tasks"`
|
||||
- `"References"`
|
||||
- `"Collectors References"`
|
||||
- This is the Topic that the file belongs to, and this is going to resemble the start directory of the file's path on Learn for example if we write `"Concepts"` in the field, then the file is going to be placed under `/Concepts/....` inside Learn.
|
||||
- `learn_rel_path: "/example/"`
|
||||
- This tag represents the rest of the path, without the filename in the end, so in this case if the file is a Concept, it would go under `Concepts/example/filename.md`. If you want to place the file under the "root" topic folder, input `"/"`.
|
||||
- ⚠️ In case any of these "Learn" tags are missing or falsely inputted the file will remain unpublished. This is by design to prevent non-properly tagged files from getting published.
|
||||
- `learn_status: "..."`
|
||||
- The options for this tag are:
|
||||
- `"published"`
|
||||
- `"unpublished"`
|
||||
- `learn_topic_type: "..."`
|
||||
- The options for this tag are:
|
||||
- `"Getting Started"`
|
||||
- `"Concepts"`
|
||||
- `"Tasks"`
|
||||
- `"References"`
|
||||
- `"Collectors References"`
|
||||
- This is the Topic that the file belongs to, and this is going to resemble the start directory of the file's
|
||||
path on Learn for example if we write `"Concepts"` in the field, then the file is going to be placed
|
||||
under `/Concepts/....` inside Learn.
|
||||
- `learn_rel_path: "/example/"`
|
||||
- This tag represents the rest of the path, without the filename in the end, so in this case if the file is a
|
||||
Concept, it would go under `Concepts/example/filename.md`. If you want to place the file under the "root"
|
||||
topic folder, input `"/"`.
|
||||
- ⚠️ In case any of these "Learn" tags are missing or falsely inputted the file will remain unpublished. This is by
|
||||
design to prevent non-properly tagged files from getting published.
|
||||
|
||||
While Docusaurus can make use of more metadata tags than the above, these are the minimum we require to publish the file on Learn.
|
||||
While Docusaurus can make use of more metadata tags than the above, these are the minimum we require to publish the file
|
||||
on Learn.
|
||||
|
||||
### Doc Templates
|
||||
|
||||
|
|
@ -193,10 +225,10 @@ Needs only `url` to server's `server-status?auto`. Here is an example for 2 serv
|
|||
|
||||
```yaml
|
||||
jobs:
|
||||
- name: local
|
||||
url: http://127.0.0.1/server-status?auto
|
||||
- name: remote
|
||||
url: http://203.0.113.10/server-status?auto
|
||||
- name: local
|
||||
url: http://127.0.0.1/server-status?auto
|
||||
- name: remote
|
||||
url: http://203.0.113.10/server-status?auto
|
||||
```
|
||||
|
||||
For all available options please see
|
||||
|
|
@ -234,7 +266,8 @@ Describe all the information that the user needs to know before proceeding with
|
|||
|
||||
## Context
|
||||
|
||||
Describe the background information of the Task, the purpose of the Task, and what will the user achieve by completing it.
|
||||
Describe the background information of the Task, the purpose of the Task, and what will the user achieve by completing
|
||||
it.
|
||||
|
||||
## Steps
|
||||
|
||||
|
|
@ -268,7 +301,8 @@ The template of the Concept files is:
|
|||
|
||||
## Description
|
||||
|
||||
In our concepts we have a more loose structure, the goal is to communicate the "concept" to the user, starting with simple language that even a new user can understand, and building from there.
|
||||
In our concepts we have a more loose structure, the goal is to communicate the "concept" to the user, starting with
|
||||
simple language that even a new user can understand, and building from there.
|
||||
|
||||
</details>
|
||||
|
||||
|
|
@ -335,7 +369,8 @@ Netdata is a global company in every sense, with employees, contributors, and us
|
|||
communicate in a way that is clear and easily understood by everyone.
|
||||
|
||||
Here are some guidelines, pointers, and questions to be aware of as you write to ensure your writing is universal. Some
|
||||
of these are expanded into individual sections in the [language, grammar, and mechanics](#language-grammar-and-mechanics) section below.
|
||||
of these are expanded into individual sections in
|
||||
the [language, grammar, and mechanics](#language-grammar-and-mechanics) section below.
|
||||
|
||||
- Would this language make sense to someone who doesn't work here?
|
||||
- Could someone quickly scan this document and understand the material?
|
||||
|
|
@ -364,8 +399,8 @@ of these are expanded into individual sections in the [language, grammar, and me
|
|||
|
||||
To ensure Netdata's writing is clear, concise, and universal, we have established standards for language, grammar, and
|
||||
certain writing mechanics. However, if you're writing about Netdata for an external publication, such as a guest blog
|
||||
post, follow that publication's style guide or standards, while keeping the [preferred spelling of Netdata
|
||||
terms](#netdata-specific-terms) in mind.
|
||||
post, follow that publication's style guide or standards, while keeping
|
||||
the [preferred spelling of Netdata terms](#netdata-specific-terms) in mind.
|
||||
|
||||
### Active voice
|
||||
|
||||
|
|
@ -374,7 +409,7 @@ the sentence is action. In passive voice, the subject is acted upon. A famous ex
|
|||
"mistakes were made."
|
||||
|
||||
| | |
|
||||
| --------------- | ----------------------------------------------------------------------------------------- |
|
||||
|-----------------|-------------------------------------------------------------------------------------------|
|
||||
| Not recommended | When an alarm is triggered by a metric, a notification is sent by Netdata. |
|
||||
| **Recommended** | When a metric triggers an alarm, Netdata sends a notification to your preferred endpoint. |
|
||||
|
||||
|
|
@ -388,16 +423,16 @@ implied, depending on your sentence structure.
|
|||
One valid exception is when a member of the Netdata team or community wants to write about said team or community.
|
||||
|
||||
| | |
|
||||
| ------------------------------ | ------------------------------------------------------------ |
|
||||
|--------------------------------|--------------------------------------------------------------|
|
||||
| Not recommended | To install Netdata, we should try the one-line installer... |
|
||||
| **Recommended** | To install Netdata, you should try the one-line installer... |
|
||||
| **Recommended**, implied "you" | To install Netdata, try the one-line installer... |
|
||||
|
||||
### "Easy" or "simple"
|
||||
|
||||
Using words that imply the complexity of a task or feature goes against our policy of [universal
|
||||
communication](#universal-communication). If you claim that a task is easy and the reader struggles to complete it, you
|
||||
may inadvertently discourage them.
|
||||
Using words that imply the complexity of a task or feature goes against our policy
|
||||
of [universal communication](#universal-communication). If you claim that a task is easy and the reader struggles to
|
||||
complete it, you may inadvertently discourage them.
|
||||
|
||||
However, if you give users two options and want to relay that one option is genuinely less complex than another, be
|
||||
specific about how and why.
|
||||
|
|
@ -433,7 +468,7 @@ capitalization. In summary:
|
|||
- Capitalize the first word of every new sentence.
|
||||
- Don't use uppercase for emphasis. (Netdata is the BEST!)
|
||||
- Capitalize the names of brands, software, products, and companies according to their official guidelines. (Netdata,
|
||||
Docker, Apache, NGINX)
|
||||
Docker, Apache, NGINX)
|
||||
- Avoid camel case (NetData) or all caps (NETDATA).
|
||||
|
||||
Whenever you refer to the company Netdata, Inc., or the open-source monitoring agent the company develops, capitalize
|
||||
|
|
@ -443,7 +478,7 @@ However, if you are referring to a process, user, or group on a Linux system, us
|
|||
inline code block: `` `netdata` ``.
|
||||
|
||||
| | |
|
||||
| --------------- | ---------------------------------------------------------------------------------------------- |
|
||||
|-----------------|------------------------------------------------------------------------------------------------|
|
||||
| Not recommended | The netdata agent, which spawns the netdata process, is actively maintained by netdata, inc. |
|
||||
| **Recommended** | The Netdata Agent, which spawns the `netdata` process, is actively maintained by Netdata, Inc. |
|
||||
|
||||
|
|
@ -457,7 +492,7 @@ guidelines.
|
|||
Also, don't put a period (`.`) or colon (`:`) at the end of a title or header.
|
||||
|
||||
| | |
|
||||
| --------------- | --------------------------------------------------------------------------------------------------- |
|
||||
|-----------------|-----------------------------------------------------------------------------------------------------|
|
||||
| Not recommended | Getting Started Guide <br />Service Discovery and Auto-Detection: <br />Install netdata with docker |
|
||||
| **Recommended** | Getting started guide <br />Service discovery and auto-detection <br />Install Netdata with Docker |
|
||||
|
||||
|
|
@ -471,7 +506,7 @@ When introducing an abbreviation to a document for the first time, give the read
|
|||
shortened version at the same time. For example:
|
||||
|
||||
> Use Netdata to monitor Extended Berkeley Packet Filter (eBPF) metrics in real-time.
|
||||
After you define an abbreviation, don't switch back and forth. Use only the abbreviation for the rest of the document.
|
||||
> After you define an abbreviation, don't switch back and forth. Use only the abbreviation for the rest of the document.
|
||||
|
||||
You can also use abbreviations in a document's title to keep the title short and relevant. If you do this, you should
|
||||
still introduce the spelled-out name alongside the abbreviation as soon as possible.
|
||||
|
|
@ -482,7 +517,7 @@ When instructing users to take action, give them the context first. By placing t
|
|||
beginning of the sentence, users can immediately know if they want to read more, follow a link, or skip ahead.
|
||||
|
||||
| | |
|
||||
| --------------- | ------------------------------------------------------------------------------ |
|
||||
|-----------------|--------------------------------------------------------------------------------|
|
||||
| Not recommended | Read the reference guide if you'd like to learn more about custom dashboards. |
|
||||
| **Recommended** | If you'd like to learn more about custom dashboards, read the reference guide. |
|
||||
|
||||
|
|
@ -492,7 +527,7 @@ The Oxford comma is the comma used after the second-to-last item in a list of th
|
|||
before "and" or "or."
|
||||
|
||||
| | |
|
||||
| --------------- | ---------------------------------------------------------------------------- |
|
||||
|-----------------|------------------------------------------------------------------------------|
|
||||
| Not recommended | Netdata can monitor RAM, disk I/O, MySQL queries per second and lm-sensors. |
|
||||
| **Recommended** | Netdata can monitor RAM, disk I/O, MySQL queries per second, and lm-sensors. |
|
||||
|
||||
|
|
@ -501,19 +536,19 @@ before "and" or "or."
|
|||
Do not mention future releases or upcoming features in writing unless they have been previously communicated via a
|
||||
public roadmap.
|
||||
|
||||
In particular, documentation must describe, as accurately as possible, the Netdata Agent _as of the [latest
|
||||
commit](https://github.com/netdata/netdata/commits/master) in the GitHub repository_. For Netdata Cloud, documentation
|
||||
must reflect the *current state* of [production](https://app.netdata.cloud).
|
||||
In particular, documentation must describe, as accurately as possible, the Netdata Agent _as of
|
||||
the [latest commit](https://github.com/netdata/netdata/commits/master) in the GitHub repository_. For Netdata Cloud,
|
||||
documentation must reflect the *current state* of [production](https://app.netdata.cloud).
|
||||
|
||||
### Informational links
|
||||
|
||||
Every link should clearly state its destination. Don't use words like "here" to describe where a link will take your
|
||||
reader.
|
||||
|
||||
| | |
|
||||
| --------------- | ------------------------------------------------------------------------------------------ |
|
||||
| Not recommended | To install Netdata, click [here](/docs/agent/packaging/installer). |
|
||||
| **Recommended** | To install Netdata, read the [installation instructions](/docs/agent/packaging/installer). |
|
||||
| | |
|
||||
|-----------------|-----------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Not recommended | To install Netdata, click [here](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md). |
|
||||
| **Recommended** | To install Netdata, read the [installation instructions](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md). |
|
||||
|
||||
Use links as often as required to provide necessary context. Blog posts and guides require less hyperlinks than
|
||||
documentation. See the section on [linking between documentation](#linking-between-documentation) for guidance on the
|
||||
|
|
@ -546,7 +581,7 @@ Use `NODE` instead of an actual or example IP address/hostname when referencing
|
|||
or API endpoint in a browser.
|
||||
|
||||
| | |
|
||||
| --------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
|-----------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Not recommended | Navigate to `http://example.com:19999` in your browser to see Netdata's dashboard. <br />Navigate to `http://203.0.113.0:19999` in your browser to see Netdata's dashboard. |
|
||||
| **Recommended** | Navigate to `http://NODE:19999` in your browser to see Netdata's dashboard. |
|
||||
|
||||
|
|
@ -563,16 +598,17 @@ Netdata Agent installation will have commands under the same paths. When applica
|
|||
path, providing a recommendation or instructions on how to view the running configuration, which includes the correct
|
||||
paths.
|
||||
|
||||
For example, the [configuration](/docs/configure/nodes) doc first teaches users how to find the Netdata config
|
||||
For example, the [configuration](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md) doc first
|
||||
teaches users how to find the Netdata config
|
||||
directory and navigate to it, then runs commands from the `/etc/netdata` path so that the instructions are more
|
||||
universal.
|
||||
|
||||
Don't include full paths, beginning from the system's root (`/`), as these might not work on certain systems.
|
||||
|
||||
| | |
|
||||
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Not recommended | Use `edit-config` to edit Netdata's configuration: `sudo /etc/netdata/edit-config netdata.conf`. |
|
||||
| **Recommended** | Use `edit-config` to edit Netdata's configuration by first navigating to your [Netdata config directory](/docs/configure/nodes#the-netdata-config-directory), which is typically at `/etc/netdata`, then running `sudo edit-config netdata.conf`. |
|
||||
| | |
|
||||
|-----------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Not recommended | Use `edit-config` to edit Netdata's configuration: `sudo /etc/netdata/edit-config netdata.conf`. |
|
||||
| **Recommended** | Use `edit-config` to edit Netdata's configuration by first navigating to your [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory), which is typically at `/etc/netdata`, then running `sudo edit-config netdata.conf`. |
|
||||
|
||||
### `sudo`
|
||||
|
||||
|
|
@ -584,7 +620,7 @@ For example, most users need to use `sudo` with the `edit-config` script, becaus
|
|||
by the `netdata` user. Same goes for restarting the Netdata Agent with `systemctl`.
|
||||
|
||||
| | |
|
||||
| --------------- | -------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
|-----------------|----------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Not recommended | Run `edit-config netdata.conf` to configure the Netdata Agent. <br />Run `systemctl restart netdata` to restart the Netdata Agent. |
|
||||
| **Recommended** | Run `sudo edit-config netdata.conf` to configure the Netdata Agent. <br />Run `sudo systemctl restart netdata` to restart the Netdata Agent. |
|
||||
|
||||
|
|
@ -615,14 +651,19 @@ If you want to see all the settings, open the
|
|||
### MDX and markdown
|
||||
|
||||
While writing in Docusaurus, you might want to take leverage of it's features that are supported in MDX formatted files.
|
||||
One of those that we use is [Tabs](https://docusaurus.io/docs/next/markdown-features/tabs). They use an HTML syntax, which requires some changes in the way we write markdown inside them.
|
||||
One of those that we use is [Tabs](https://docusaurus.io/docs/next/markdown-features/tabs). They use an HTML syntax,
|
||||
which requires some changes in the way we write markdown inside them.
|
||||
|
||||
In detail:
|
||||
|
||||
Due to a bug with docusaurus, we prefer to use `<h1>heading</h1> instead of # H1` so that docusaurus doesn't render the contents of all Tabs on the right hand side, while not being able to navigate them [relative link](https://github.com/facebook/docusaurus/issues/7008).
|
||||
Due to a bug with docusaurus, we prefer to use `<h1>heading</h1> instead of # H1` so that docusaurus doesn't render the
|
||||
contents of all Tabs on the right hand side, while not being able to navigate
|
||||
them [relative link](https://github.com/facebook/docusaurus/issues/7008).
|
||||
|
||||
You can use markdown syntax for every other styling you want to do except Admonitions:
|
||||
For admonitions, follow [this](https://docusaurus.io/docs/markdown-features/admonitions#usage-in-jsx) guide to use admonitions inside JSX. While writing in JSX, all the markdown stylings have to be in HTML format to be rendered properly.
|
||||
For admonitions, follow [this](https://docusaurus.io/docs/markdown-features/admonitions#usage-in-jsx) guide to use
|
||||
admonitions inside JSX. While writing in JSX, all the markdown stylings have to be in HTML format to be rendered
|
||||
properly.
|
||||
|
||||
### Frontmatter
|
||||
|
||||
|
|
@ -645,7 +686,7 @@ this case, replace `/docs` with `/img/seo`, and then rebuild the remainder of th
|
|||
the path with `.png`. A member of the Netdata team will assist in creating the image when publishing the content.
|
||||
|
||||
For example, here is the frontmatter for the guide about [deploying the Netdata Agent with
|
||||
Ansible](/guides/deploy/ansible).
|
||||
Ansible](https://github.com/netdata/netdata/blob/master/docs/guides/deploy/ansible.md).
|
||||
|
||||
```markdown
|
||||
<!--
|
||||
|
|
@ -665,23 +706,25 @@ forum](https://community.netdata.cloud/c/blog-posts-and-articles/6).
|
|||
|
||||
### Admonitions
|
||||
|
||||
In addition to basic markdown syntax, we also encourage the use of admonition syntax, which allows for a more aesthetically seamless presentation of supplemental information. For general instructions on using admonitions, feel free to read this [feature guide](https://docusaurus.io/docs/markdown-features/admonitions).
|
||||
In addition to basic markdown syntax, we also encourage the use of admonition syntax, which allows for a more
|
||||
aesthetically seamless presentation of supplemental information. For general instructions on using admonitions, feel
|
||||
free to read this [feature guide](https://docusaurus.io/docs/markdown-features/admonitions).
|
||||
|
||||
We encourage the use of **Note** admonitions to provide important supplemental information to a user within a task step, reference item, or concept passage.
|
||||
We encourage the use of **Note** admonitions to provide important supplemental information to a user within a task step,
|
||||
reference item, or concept passage.
|
||||
|
||||
Additionally, you should use a **Caution** admonition to provide necessary information to present any risk to a user's setup or data.
|
||||
Additionally, you should use a **Caution** admonition to provide necessary information to present any risk to a user's
|
||||
setup or data.
|
||||
|
||||
**Danger** admonitions should be avoided, as these admonitions are typically applied to reduce physical or bodily harm to an individual.
|
||||
**Danger** admonitions should be avoided, as these admonitions are typically applied to reduce physical or bodily harm
|
||||
to an individual.
|
||||
|
||||
### Linking between documentation
|
||||
|
||||
Documentation should link to relevant pages whenever it's relevant and provides valuable context to the reader.
|
||||
|
||||
Links should always reference the full path to the document, beginning at the root of the Netdata Agent repository
|
||||
(`/`), and ending with the `.md` file extension. Avoid relative links or traversing up directories using `../`.
|
||||
|
||||
For example, if you want to link to our node configuration document, link to `/docs/configure/nodes.md`. To reference
|
||||
the guide for deploying the Netdata Agent with Ansible, link to `/docs/guides/deploy/ansible.md`.
|
||||
We link between markdown documents by using its GitHub absolute link for
|
||||
instance `[short description of what we reference](https://github.com/netdata/netdata/blob/master/contribution-guidelines.md)`
|
||||
|
||||
### References to UI elements
|
||||
|
||||
|
|
@ -700,7 +743,8 @@ try to supplement the text with an [image](#images).
|
|||
|
||||
Don't rely on images to convey features, ideas, or instructions. Accompany every image with descriptive alt text.
|
||||
|
||||
In Markdown, use the standard image syntax, ``, and place the alt text between the brackets `[]`. Here's an example
|
||||
In Markdown, use the standard image syntax, ``, and place the alt text between the
|
||||
brackets `[]`. Here's an example
|
||||
using our logo:
|
||||
|
||||
```markdown
|
||||
|
|
@ -741,8 +785,8 @@ inline char *health_stock_config_dir(void) {
|
|||
}
|
||||
```
|
||||
|
||||
Prism also supports titles and line highlighting. See the [Docusaurus
|
||||
documentation](https://v2.docusaurus.io/docs/markdown-features#code-blocks) for more information.
|
||||
Prism also supports titles and line highlighting. See
|
||||
the [Docusaurus documentation](https://v2.docusaurus.io/docs/markdown-features#code-blocks) for more information.
|
||||
|
||||
## Word list
|
||||
|
||||
|
|
@ -750,24 +794,24 @@ The following tables describe the standard spelling, capitalization, and usage o
|
|||
|
||||
### Netdata-specific terms
|
||||
|
||||
| Term | Definition |
|
||||
| --------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| **claimed node** | A node that you've proved ownership of by completing the [connecting to Cloud process](/docs/agent/claim). The claimed node will then appear in your Space and any War Rooms you added it to. |
|
||||
| **Netdata** | The company behind the open-source Netdata Agent and the Netdata Cloud web application. Never use *netdata* or *NetData*. <br /><br />**Note:** You should use "Netdata" when referencing any general element, function, or part of the user experience. In general, focus on the user's goals, actions, and solutions rather than what the company provides. For example, write *Learn more about enabling alarm notifications on your preferred platforms* instead of *Netdata sends alarm notifications to your preferred platforms*. |
|
||||
| **Netdata Agent** or **Open-source Netdata Agent** | The free and open source [monitoring agent](https://github.com/netdata/netdata) that you can install on all of your distributed systems, whether they're physical, virtual, containerized, ephemeral, and more. The Agent monitors systems running Linux, Docker, Kubernetes, macOS, FreeBSD, and more, and collects metrics from hundreds of popular services and applications. <br /><br /> **Note:** You should avoid referencing the Netdata Agent or Open-source Netdata agent in any scenario that does not specifically require the distinction for clear instructions. |
|
||||
| **Netdata Cloud** | The web application hosted at [https://app.netdata.cloud](https://app.netdata.cloud) that helps you monitor an entire infrastructure of distributed systems in real time. <br /><br />**Notes:** Never use *Cloud* without the preceding *Netdata* to avoid ambiguity. You should avoid referencing Netdata Cloud in any scenario that does not specifically require the distinction for clear instructions. | |
|
||||
| **Netdata community** | Contributors to any of Netdata's [open-source projects](/contribute/projects), members of the [community forum](https://community.netdata.cloud/). |
|
||||
| **Netdata community forum** | The Discourse-powered forum for feature requests, Netdata Cloud technical support, and conversations about Netdata's monitoring and troubleshooting products. |
|
||||
| **node** | A system on which the Netdata Agent is installed. The system can be physical, virtual, in a Docker container, and more. Depending on your infrastructure, you may have one, dozens, or hundreds of nodes. Some nodes are *ephemeral*, in that they're created/destroyed automatically by an orchestrator service. |
|
||||
| **Space** | The highest level container within Netdata Cloud for a user to organize their team members and nodes within their infrastructure. A Space likely represents an entire organization or a large team. <br /><br />*Space* is always capitalized. |
|
||||
| **unreachable node** | A connected node with a disrupted [Agent-Cloud link](/docs/agent/aclk). Unreachable could mean the node no longer exists or is experiencing network connectivity issues with Cloud. |
|
||||
| **visited node** | A node which has had its Agent dashboard directly visited by a user. A list of these is maintained on a per-user basis. |
|
||||
| **War Room** | A smaller grouping of nodes where users can view key metrics in real-time and monitor the health of many nodes with their alarm status. War Rooms can be used to organize nodes in any way that makes sense for your infrastructure, such as by a service, purpose, physical location, and more. <br /><br />*War Room* is always capitalized. |
|
||||
| Term | Definition |
|
||||
|----------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| **claimed node** | A node that you've proved ownership of by completing the [connecting to Cloud process](https://github.com/netdata/netdata/blob/master/claim/README.md). The claimed node will then appear in your Space and any War Rooms you added it to. |
|
||||
| **Netdata** | The company behind the open-source Netdata Agent and the Netdata Cloud web application. Never use *netdata* or *NetData*. <br /><br />**Note:** You should use "Netdata" when referencing any general element, function, or part of the user experience. In general, focus on the user's goals, actions, and solutions rather than what the company provides. For example, write *Learn more about enabling alarm notifications on your preferred platforms* instead of *Netdata sends alarm notifications to your preferred platforms*. |
|
||||
| **Netdata Agent** or **Open-source Netdata Agent** | The free and open source [monitoring agent](https://github.com/netdata/netdata) that you can install on all of your distributed systems, whether they're physical, virtual, containerized, ephemeral, and more. The Agent monitors systems running Linux, Docker, Kubernetes, macOS, FreeBSD, and more, and collects metrics from hundreds of popular services and applications. <br /><br /> **Note:** You should avoid referencing the Netdata Agent or Open-source Netdata agent in any scenario that does not specifically require the distinction for clear instructions. |
|
||||
| **Netdata Cloud** | The web application hosted at [https://app.netdata.cloud](https://app.netdata.cloud) that helps you monitor an entire infrastructure of distributed systems in real time. <br /><br />**Notes:** Never use *Cloud* without the preceding *Netdata* to avoid ambiguity. You should avoid referencing Netdata Cloud in any scenario that does not specifically require the distinction for clear instructions. | |
|
||||
| **Netdata community** | Contributors to any of Netdata's [open-source projects](https://github.com/netdata/learn/blob/master/contribute/projects.mdx), members of the [community forum](https://community.netdata.cloud/). |
|
||||
| **Netdata community forum** | The Discourse-powered forum for feature requests, Netdata Cloud technical support, and conversations about Netdata's monitoring and troubleshooting products. |
|
||||
| **node** | A system on which the Netdata Agent is installed. The system can be physical, virtual, in a Docker container, and more. Depending on your infrastructure, you may have one, dozens, or hundreds of nodes. Some nodes are *ephemeral*, in that they're created/destroyed automatically by an orchestrator service. |
|
||||
| **Space** | The highest level container within Netdata Cloud for a user to organize their team members and nodes within their infrastructure. A Space likely represents an entire organization or a large team. <br /><br />*Space* is always capitalized. |
|
||||
| **unreachable node** | A connected node with a disrupted [Agent-Cloud link](https://github.com/netdata/netdata/blob/master/aclk/README.md). Unreachable could mean the node no longer exists or is experiencing network connectivity issues with Cloud. |
|
||||
| **visited node** | A node which has had its Agent dashboard directly visited by a user. A list of these is maintained on a per-user basis. |
|
||||
| **War Room** | A smaller grouping of nodes where users can view key metrics in real-time and monitor the health of many nodes with their alarm status. War Rooms can be used to organize nodes in any way that makes sense for your infrastructure, such as by a service, purpose, physical location, and more. <br /><br />*War Room* is always capitalized. |
|
||||
|
||||
### Other technical terms
|
||||
|
||||
| Term | Definition |
|
||||
| --------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
|-----------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| **filesystem** | Use instead of *file system*. |
|
||||
| **preconfigured** | The concept that many of Netdata's features come with sane defaults that users don't need to configure to find [immediate value](/docs/overview/why-netdata#simple-to-deploy). |
|
||||
| **real time**/**real-time** | Use *real time* as a noun phrase, most often with *in*: *Netdata collects metrics in real time*. Use *real-time* as an adjective: _Netdata collects real-time metrics from hundreds of supported applications and services. |
|
||||
|
|
|
|||
|
|
@ -15,7 +15,7 @@ learn_rel_path: "References/Configuration"
|
|||
- You can start Netdata by executing it with `/usr/sbin/netdata` (the installer will also start it).
|
||||
|
||||
- You can stop Netdata by killing it with `killall netdata`. You can stop and start Netdata at any point. When
|
||||
exiting, the [database engine](/database/engine/README.md) saves metrics to `/var/cache/netdata/dbengine/` so that
|
||||
exiting, the [database engine](https://github.com/netdata/netdata/blob/master/database/engine/README.md) saves metrics to `/var/cache/netdata/dbengine/` so that
|
||||
it can continue when started again.
|
||||
|
||||
Access to the web site, for all graphs, is by default on port `19999`, so go to:
|
||||
|
|
@ -206,7 +206,7 @@ The command line options of the Netdata 1.10.0 version are the following:
|
|||
- USR2 Reload health configuration.
|
||||
```
|
||||
|
||||
You can send commands during runtime via [netdatacli](/cli/README.md).
|
||||
You can send commands during runtime via [netdatacli](https://github.com/netdata/netdata/blob/master/cli/README.md).
|
||||
|
||||
## Log files
|
||||
|
||||
|
|
@ -372,7 +372,7 @@ all programs), edit `netdata.conf` and set:
|
|||
process nice level = -1
|
||||
```
|
||||
|
||||
then execute this to [restart Netdata](/docs/configure/start-stop-restart.md):
|
||||
then execute this to [restart Netdata](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md):
|
||||
|
||||
```sh
|
||||
sudo systemctl restart netdata
|
||||
|
|
|
|||
|
|
@ -26,24 +26,24 @@ adapt the general behavior of Netdata, in great detail. You can find all these s
|
|||
accessing the URL `https://netdata.server.hostname:19999/netdata.conf`. For example check the configuration file
|
||||
of [netdata.firehol.org](http://netdata.firehol.org/netdata.conf). HTTP access to this file is limited by default to
|
||||
[private IPs](https://en.wikipedia.org/wiki/Private_network), via
|
||||
the [web server access lists](/web/server/README.md#access-lists).
|
||||
the [web server access lists](https://github.com/netdata/netdata/blob/master/web/server/README.md#access-lists).
|
||||
|
||||
`netdata.conf` has sections stated with `[section]`. You will see the following sections:
|
||||
|
||||
1. `[global]` to [configure](#global-section-options) the [Netdata daemon](/daemon/README.md).
|
||||
1. `[global]` to [configure](#global-section-options) the [Netdata daemon](https://github.com/netdata/netdata/blob/master/daemon/README.md).
|
||||
2. `[db]` to [configure](#db-section-options) the database of Netdata.
|
||||
3. `[directories]` to [configure](#directories-section-options) the directories used by Netdata.
|
||||
4. `[logs]` to [configure](#logs-section-options) the Netdata logging.
|
||||
5. `[environment variables]` to [configure](#environment-variables-section-options) the environment variables used
|
||||
Netdata.
|
||||
6. `[sqlite]` to [configure](#sqlite-section-options) the [Netdata daemon](/daemon/README.md) SQLite settings.
|
||||
7. `[ml]` to configure settings for [machine learning](/ml/README.md).
|
||||
8. `[health]` to [configure](#health-section-options) general settings for [health monitoring](/health/README.md).
|
||||
9. `[web]` to [configure the web server](/web/server/README.md).
|
||||
10. `[registry]` for the [Netdata registry](/registry/README.md).
|
||||
11. `[global statistics]` for the [Netdata registry](/registry/README.md).
|
||||
12. `[statsd]` for the general settings of the [stats.d.plugin](/collectors/statsd.plugin/README.md).
|
||||
13. `[plugins]` to [configure](#plugins-section-options) which [collectors](/collectors/README.md) to use and PATH
|
||||
6. `[sqlite]` to [configure](#sqlite-section-options) the [Netdata daemon](https://github.com/netdata/netdata/blob/master/daemon/README.md) SQLite settings.
|
||||
7. `[ml]` to configure settings for [machine learning](https://github.com/netdata/netdata/blob/master/ml/README.md).
|
||||
8. `[health]` to [configure](#health-section-options) general settings for [health monitoring](https://github.com/netdata/netdata/blob/master/health/README.md).
|
||||
9. `[web]` to [configure the web server](https://github.com/netdata/netdata/blob/master/web/server/README.md).
|
||||
10. `[registry]` for the [Netdata registry](https://github.com/netdata/netdata/blob/master/registry/README.md).
|
||||
11. `[global statistics]` for the [Netdata registry](https://github.com/netdata/netdata/blob/master/registry/README.md).
|
||||
12. `[statsd]` for the general settings of the [stats.d.plugin](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/README.md).
|
||||
13. `[plugins]` to [configure](#plugins-section-options) which [collectors](https://github.com/netdata/netdata/blob/master/collectors/README.md) to use and PATH
|
||||
settings.
|
||||
14. `[plugin:NAME]` sections for each collector plugin, under the
|
||||
comment [Per plugin configuration](#per-plugin-configuration).
|
||||
|
|
@ -54,7 +54,7 @@ comment on settings it does not currently use.
|
|||
|
||||
## Applying changes
|
||||
|
||||
After `netdata.conf` has been modified, Netdata needs to be [restarted](/docs/configure/start-stop-restart.md) for
|
||||
After `netdata.conf` has been modified, Netdata needs to be [restarted](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for
|
||||
changes to apply:
|
||||
|
||||
```bash
|
||||
|
|
@ -75,10 +75,10 @@ Please note that your data history will be lost if you have modified `history` p
|
|||
|
||||
| setting | default | info |
|
||||
|:-------------------------------------:|:-------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| process scheduling policy | `keep` | See [Netdata process scheduling policy](/daemon/README.md#netdata-process-scheduling-policy) |
|
||||
| process scheduling policy | `keep` | See [Netdata process scheduling policy](https://github.com/netdata/netdata/blob/master/daemon/README.md#netdata-process-scheduling-policy) |
|
||||
| OOM score | `0` | |
|
||||
| glibc malloc arena max for plugins | `1` | See [Virtual memory](/daemon/README.md#virtual-memory). |
|
||||
| glibc malloc arena max for Netdata | `1` | See [Virtual memory](/daemon/README.md#virtual-memory). |
|
||||
| glibc malloc arena max for plugins | `1` | See [Virtual memory](https://github.com/netdata/netdata/blob/master/daemon/README.md#virtual-memory). |
|
||||
| glibc malloc arena max for Netdata | `1` | See [Virtual memory](https://github.com/netdata/netdata/blob/master/daemon/README.md#virtual-memory). |
|
||||
| hostname | auto-detected | The hostname of the computer running Netdata. |
|
||||
| host access prefix | empty | This is used in docker environments where /proc, /sys, etc have to be accessed via another path. You may also have to set SYS_PTRACE capability on the docker for this work. Check [issue 43](https://github.com/netdata/netdata/issues/43). |
|
||||
| timezone | auto-detected | The timezone retrieved from the environment variable |
|
||||
|
|
@ -90,21 +90,21 @@ Please note that your data history will be lost if you have modified `history` p
|
|||
| setting | default | info |
|
||||
|:---------------------------------------------:|:----------:|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| mode | `dbengine` | `dbengine`: The default for long-term metrics storage with efficient RAM and disk usage. Can be extended with `dbengine page cache size MB` and `dbengine disk space MB`. <br />`save`: Netdata will save its round robin database on exit and load it on startup. <br />`map`: Cache files will be updated in real-time. Not ideal for systems with high load or slow disks (check `man mmap`). <br />`ram`: The round-robin database will be temporary and it will be lost when Netdata exits. <br />`alloc`: Similar to `ram`, but can significantly reduce memory usage, when combined with a low retention and does not support KSM. <br />`none`: Disables the database at this host, and disables health monitoring entirely, as that requires a database of metrics. Not to be used together with streaming. |
|
||||
| retention | `3600` | Used with `mode = save/map/ram/alloc`, not the default `mode = dbengine`. This number reflects the number of entries the `netdata` daemon will by default keep in memory for each chart dimension. Check [Memory Requirements](/database/README.md) for more information. |
|
||||
| storage tiers | `1` | The number of storage tiers you want to have in your dbengine. Check the tiering mechanism in the [dbengine's reference](/database/engine/README.md#tiering). You can have up to 5 tiers of data (including the _Tier 0_). This number ranges between 1 and 5. |
|
||||
| retention | `3600` | Used with `mode = save/map/ram/alloc`, not the default `mode = dbengine`. This number reflects the number of entries the `netdata` daemon will by default keep in memory for each chart dimension. Check [Memory Requirements](https://github.com/netdata/netdata/blob/master/database/README.md) for more information. |
|
||||
| storage tiers | `1` | The number of storage tiers you want to have in your dbengine. Check the tiering mechanism in the [dbengine's reference](https://github.com/netdata/netdata/blob/master/database/engine/README.md#tiering). You can have up to 5 tiers of data (including the _Tier 0_). This number ranges between 1 and 5. |
|
||||
| dbengine page cache size MB | `32` | Determines the amount of RAM in MiB that is dedicated to caching for _Tier 0_ Netdata metric values. |
|
||||
| dbengine tier **`N`** page cache size MB | `32` | Determines the amount of RAM in MiB that is dedicated for caching Netdata metric values of the **`N`** tier. <br /> `N belongs to [1..4]` ||
|
||||
| dbengine disk space MB | `256` | Determines the amount of disk space in MiB that is dedicated to storing _Tier 0_ Netdata metric values and all related metadata describing them. This option is available **only for legacy configuration** (`Agent v1.23.2 and prior`). |
|
||||
| dbengine multihost disk space MB | `256` | Same functionality as `dbengine disk space MB`, but includes support for storing metrics streamed to a parent node by its children. Can be used in single-node environments as well. This setting is only for _Tier 0_ metrics. |
|
||||
| dbengine tier **`N`** multihost disk space MB | `256` | Same functionality as `dbengine multihost disk space MB`, but stores metrics of the **`N`** tier (both parent node and its children). Can be used in single-node environments as well. <br /> `N belongs to [1..4]` |
|
||||
| update every | `1` | The frequency in seconds, for data collection. For more information see the [performance guide](/docs/guides/configure/performance.md). These metrics stored as _Tier 0_ data. Explore the tiering mechanism in the [dbengine's reference](/database/engine/README.md#tiering). |
|
||||
| update every | `1` | The frequency in seconds, for data collection. For more information see the [performance guide](https://github.com/netdata/netdata/blob/master/docs/guides/configure/performance.md). These metrics stored as _Tier 0_ data. Explore the tiering mechanism in the [dbengine's reference](https://github.com/netdata/netdata/blob/master/database/engine/README.md#tiering). |
|
||||
| dbengine tier **`N`** update every iterations | `60` | The down sampling value of each tier from the previous one. For each Tier, the greater by one Tier has N (equal to 60 by default) less data points of any metric it collects. This setting can take values from `2` up to `255`. <br /> `N belongs to [1..4]` |
|
||||
| dbengine tier **`N`** back fill | `New` | Specifies the strategy of recreating missing data on each Tier from the exact lower Tier. <br /> `New`: Sees the latest point on each Tier and save new points to it only if the exact lower Tier has available points for it's observation window (`dbengine tier N update every iterations` window). <br /> `none`: No back filling is applied. <br /> `N belongs to [1..4]` |
|
||||
| memory deduplication (ksm) | `yes` | When set to `yes`, Netdata will offer its in-memory round robin database and the dbengine page cache to kernel same page merging (KSM) for deduplication. For more information check [Memory Deduplication - Kernel Same Page Merging - KSM](/database/README.md#ksm) |
|
||||
| cleanup obsolete charts after secs | `3600` | See [monitoring ephemeral containers](/collectors/cgroups.plugin/README.md#monitoring-ephemeral-containers), also sets the timeout for cleaning up obsolete dimensions |
|
||||
| memory deduplication (ksm) | `yes` | When set to `yes`, Netdata will offer its in-memory round robin database and the dbengine page cache to kernel same page merging (KSM) for deduplication. For more information check [Memory Deduplication - Kernel Same Page Merging - KSM](https://github.com/netdata/netdata/blob/master/database/README.md#ksm) |
|
||||
| cleanup obsolete charts after secs | `3600` | See [monitoring ephemeral containers](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md#monitoring-ephemeral-containers), also sets the timeout for cleaning up obsolete dimensions |
|
||||
| gap when lost iterations above | `1` | |
|
||||
| cleanup orphan hosts after secs | `3600` | How long to wait until automatically removing from the DB a remote Netdata host (child) that is no longer sending data. |
|
||||
| delete obsolete charts files | `yes` | See [monitoring ephemeral containers](/collectors/cgroups.plugin/README.md#monitoring-ephemeral-containers), also affects the deletion of files for obsolete dimensions |
|
||||
| delete obsolete charts files | `yes` | See [monitoring ephemeral containers](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md#monitoring-ephemeral-containers), also affects the deletion of files for obsolete dimensions |
|
||||
| delete orphan hosts files | `yes` | Set to `no` to disable non-responsive host removal. |
|
||||
| enable zero metrics | `no` | Set to `yes` to show charts when all their metrics are zero. |
|
||||
|
||||
|
|
@ -121,7 +121,7 @@ The multiplication of all the **enabled** tiers `dbengine tier N update every i
|
|||
|:-------------------:|:------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| config | `/etc/netdata` | The directory configuration files are kept. |
|
||||
| stock config | `/usr/lib/netdata/conf.d` | |
|
||||
| log | `/var/log/netdata` | The directory in which the [log files](/daemon/README.md#log-files) are kept. |
|
||||
| log | `/var/log/netdata` | The directory in which the [log files](https://github.com/netdata/netdata/blob/master/daemon/README.md#log-files) are kept. |
|
||||
| web | `/usr/share/netdata/web` | The directory the web static files are kept. |
|
||||
| cache | `/var/cache/netdata` | The directory the memory database will be stored if and when Netdata exits. Netdata will re-read the database when it will start again, to continue from the same point. |
|
||||
| lib | `/var/lib/netdata` | Contains the alarm log and the Netdata instance GUID. |
|
||||
|
|
@ -130,14 +130,14 @@ The multiplication of all the **enabled** tiers `dbengine tier N update every i
|
|||
| plugins | `"/usr/libexec/netdata/plugins.d" "/etc/netdata/custom-plugins.d"` | The directory plugin programs are kept. This setting supports multiple directories, space separated. If any directory path contains spaces, enclose it in single or double quotes. |
|
||||
| health config | `/etc/netdata/health.d` | The directory containing the user alarm configuration files, to override the stock configurations |
|
||||
| stock health config | `/usr/lib/netdata/conf.d/health.d` | Contains the stock alarm configuration files for each collector |
|
||||
| registry | `/opt/netdata/var/lib/netdata/registry` | Contains the [registry](/registry/README.md) database and GUID that uniquely identifies each Netdata Agent |
|
||||
| registry | `/opt/netdata/var/lib/netdata/registry` | Contains the [registry](https://github.com/netdata/netdata/blob/master/registry/README.md) database and GUID that uniquely identifies each Netdata Agent |
|
||||
|
||||
### [logs] section options
|
||||
|
||||
| setting | default | info |
|
||||
|:----------------------------------:|:-----------------------------:|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| debug flags | `0x0000000000000000` | Bitmap of debug options to enable. For more information check [Tracing Options](/daemon/README.md#debugging). |
|
||||
| debug | `/var/log/netdata/debug.log` | The filename to save debug information. This file will not be created if debugging is not enabled. You can also set it to `syslog` to send the debug messages to syslog, or `none` to disable this log. For more information check [Tracing Options](/daemon/README.md#debugging). |
|
||||
| debug flags | `0x0000000000000000` | Bitmap of debug options to enable. For more information check [Tracing Options](https://github.com/netdata/netdata/blob/master/daemon/README.md#debugging). |
|
||||
| debug | `/var/log/netdata/debug.log` | The filename to save debug information. This file will not be created if debugging is not enabled. You can also set it to `syslog` to send the debug messages to syslog, or `none` to disable this log. For more information check [Tracing Options](https://github.com/netdata/netdata/blob/master/daemon/README.md#debugging). |
|
||||
| error | `/var/log/netdata/error.log` | The filename to save error messages for Netdata daemon and all plugins (`stderr` is sent here for all Netdata programs, including the plugins). You can also set it to `syslog` to send the errors to syslog, or `none` to disable this log. |
|
||||
| access | `/var/log/netdata/access.log` | The filename to save the log of web clients accessing Netdata charts. You can also set it to `syslog` to send the access log to syslog, or `none` to disable this log. |
|
||||
| facility | `daemon` | A facility keyword is used to specify the type of system that is logging the message. |
|
||||
|
|
@ -168,9 +168,9 @@ The multiplication of all the **enabled** tiers `dbengine tier N update every i
|
|||
This section controls the general behavior of the health monitoring capabilities of Netdata.
|
||||
|
||||
Specific alarms are configured in per-collector config files under the `health.d` directory. For more info, see [health
|
||||
monitoring](/health/README.md).
|
||||
monitoring](https://github.com/netdata/netdata/blob/master/health/README.md).
|
||||
|
||||
[Alarm notifications](/health/notifications/README.md) are configured in `health_alarm_notify.conf`.
|
||||
[Alarm notifications](https://github.com/netdata/netdata/blob/master/health/notifications/README.md) are configured in `health_alarm_notify.conf`.
|
||||
|
||||
| setting | default | info |
|
||||
|:----------------------------------------------:|:------------------------------------------------:|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
|
|
@ -180,11 +180,11 @@ monitoring](/health/README.md).
|
|||
| run at least every seconds | `10` | Controls how often all alarm conditions should be evaluated. |
|
||||
| postpone alarms during hibernation for seconds | `60` | Prevents false alarms. May need to be increased if you get alarms during hibernation. |
|
||||
| rotate log every lines | 2000 | Controls the number of alarm log entries stored in `<lib directory>/health-log.db`, where `<lib directory>` is the one configured in the [\[global\] section](#global-section-options) |
|
||||
| enabled alarms | * | Defines which alarms to load from both user and stock directories. This is a [simple pattern](/libnetdata/simple_pattern/README.md) list of alarm or template names. Can be used to disable specific alarms. For example, `enabled alarms = !oom_kill *` will load all alarms except `oom_kill`. |
|
||||
| enabled alarms | * | Defines which alarms to load from both user and stock directories. This is a [simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) list of alarm or template names. Can be used to disable specific alarms. For example, `enabled alarms = !oom_kill *` will load all alarms except `oom_kill`. |
|
||||
|
||||
### [web] section options
|
||||
|
||||
Refer to the [web server documentation](/web/server/README.md)
|
||||
Refer to the [web server documentation](https://github.com/netdata/netdata/blob/master/web/server/README.md)
|
||||
|
||||
### [plugins] section options
|
||||
|
||||
|
|
@ -204,7 +204,7 @@ Additionally, there will be the following options:
|
|||
### [registry] section options
|
||||
|
||||
To understand what this section is and how it should be configured, please refer to
|
||||
the [registry documentation](/registry/README.md).
|
||||
the [registry documentation](https://github.com/netdata/netdata/blob/master/registry/README.md).
|
||||
|
||||
## Per-plugin configuration
|
||||
|
||||
|
|
@ -212,7 +212,7 @@ The configuration options for plugins appear in sections following the pattern `
|
|||
|
||||
### Internal plugins
|
||||
|
||||
Most internal plugins will provide additional options. Check [Internal Plugins](/collectors/README.md) for more
|
||||
Most internal plugins will provide additional options. Check [Internal Plugins](https://github.com/netdata/netdata/blob/master/collectors/README.md) for more
|
||||
information.
|
||||
|
||||
Please note, that by default Netdata will enable monitoring metrics for disks, memory, and network only when they are
|
||||
|
|
@ -228,7 +228,7 @@ External plugins will have only 2 options at `netdata.conf`:
|
|||
|
||||
| setting | default | info |
|
||||
|:---------------:|:--------------------------------------------:|:------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| update every | the value of `[global].update every` setting | The frequency in seconds the plugin should collect values. For more information check the [performance guide](/docs/guides/configure/performance.md). |
|
||||
| update every | the value of `[global].update every` setting | The frequency in seconds the plugin should collect values. For more information check the [performance guide](https://github.com/netdata/netdata/blob/master/docs/guides/configure/performance.md). |
|
||||
| command options | - | Additional command line options to pass to the plugin. | |
|
||||
|
||||
External plugins that need additional configuration may support a dedicated file in `/etc/netdata`. Check their
|
||||
|
|
|
|||
|
|
@ -13,12 +13,12 @@ learn_rel_path: "Setup"
|
|||
Netdata is fully capable of long-term metrics storage, at per-second granularity, via its default database engine
|
||||
(`dbengine`). But to remain as flexible as possible, Netdata supports several storage options:
|
||||
|
||||
1. `dbengine`, (the default) data are in database files. The [Database Engine](/database/engine/README.md) works like a
|
||||
1. `dbengine`, (the default) data are in database files. The [Database Engine](https://github.com/netdata/netdata/blob/master/database/engine/README.md) works like a
|
||||
traditional database. There is some amount of RAM dedicated to data caching and indexing and the rest of the data
|
||||
reside compressed on disk. The number of history entries is not fixed in this case, but depends on the configured
|
||||
disk space and the effective compression ratio of the data stored. This is the **only mode** that supports changing
|
||||
the data collection update frequency (`update every`) **without losing** the previously stored metrics. For more
|
||||
details see [here](/database/engine/README.md).
|
||||
details see [here](https://github.com/netdata/netdata/blob/master/database/engine/README.md).
|
||||
|
||||
2. `ram`, data are purely in memory. Data are never saved on disk. This mode uses `mmap()` and supports [KSM](#ksm).
|
||||
|
||||
|
|
@ -42,13 +42,13 @@ The default mode `[db].mode = dbengine` has been designed to scale for longer re
|
|||
for parent Agents in the _Parent - Child_ setups
|
||||
|
||||
The other available database modes are designed to minimize resource utilization and should only be considered on
|
||||
[Parent - Child](/docs/metrics-storage-management/how-streaming-works.mdx) setups at the children side and only when the
|
||||
[Parent - Child](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/how-streaming-works.mdx) setups at the children side and only when the
|
||||
resource constraints are very strict.
|
||||
|
||||
So,
|
||||
|
||||
- On a single node setup, use `[db].mode = dbengine`.
|
||||
- On a [Parent - Child](/docs/metrics-storage-management/how-streaming-works.mdx) setup, use `[db].mode = dbengine` on the
|
||||
- On a [Parent - Child](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/how-streaming-works.mdx) setup, use `[db].mode = dbengine` on the
|
||||
parent to increase retention, a more resource efficient mode like, `dbengine` with light retention settings, and
|
||||
`save`, `ram` or `none` modes for the children to minimize resource utilization.
|
||||
|
||||
|
|
@ -68,7 +68,7 @@ Metrics retention is controlled only by the disk space allocated to storing metr
|
|||
CPU required by the agent to query longer timeframes.
|
||||
|
||||
Since Netdata Agents usually run on the edge, on production systems, Netdata Agent **parents** should be considered.
|
||||
When having a [**parent - child**](/docs/metrics-storage-management/how-streaming-works.mdx) setup, the child (the
|
||||
When having a [**parent - child**](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/how-streaming-works.mdx) setup, the child (the
|
||||
Netdata Agent running on a production system) delegates all of its functions, including longer metrics retention and
|
||||
querying, to the parent node that can dedicate more resources to this task. A single Netdata Agent parent can centralize
|
||||
multiple children Netdata Agents (dozens, hundreds, or even thousands depending on its available resources).
|
||||
|
|
@ -89,7 +89,7 @@ every 2 seconds. This will **cut in half** both CPU and RAM resources consumed b
|
|||
On very weak devices you might have to use `[db].update every = 5` and `[db].retention = 720` (still 1 hour of data, but
|
||||
1/5 of the CPU and RAM resources).
|
||||
|
||||
You can also disable [data collection plugins](/collectors/README.md) that you don't need. Disabling such plugins will also
|
||||
You can also disable [data collection plugins](https://github.com/netdata/netdata/blob/master/collectors/README.md) that you don't need. Disabling such plugins will also
|
||||
free both CPU and RAM resources.
|
||||
|
||||
## Memory optimizations
|
||||
|
|
|
|||
|
|
@ -305,7 +305,7 @@ Agent.
|
|||
##### Information
|
||||
|
||||
For more information about setting `[db].mode` on your nodes, in addition to other streaming configurations, see
|
||||
[streaming](/streaming/README.md).
|
||||
[streaming](https://github.com/netdata/netdata/blob/master/streaming/README.md).
|
||||
|
||||
## Requirements & limitations
|
||||
|
||||
|
|
@ -331,7 +331,7 @@ An important observation is that RAM usage depends on both the `page cache size`
|
|||
options.
|
||||
|
||||
You can use
|
||||
our [database engine calculator](/docs/store/change-metrics-storage.md#calculate-the-system-resources-ram-disk-space-needed-to-store-metrics)
|
||||
our [database engine calculator](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md#calculate-the-system-resources-ram-disk-space-needed-to-store-metrics)
|
||||
to validate the memory requirements for your particular system(s) and configuration (**out-of-date**).
|
||||
|
||||
### Disk space
|
||||
|
|
@ -403,7 +403,7 @@ location is `/var/cache/netdata/dbengine/*`). The higher numbered filenames cont
|
|||
can safely delete some pairs of files when Netdata is stopped to manually free up some space.
|
||||
|
||||
_Users should_ **back up** _their `./dbengine` folders if they consider this data to be important._ You can also set up
|
||||
one or more [exporting connectors](/exporting/README.md) to send your Netdata metrics to other databases for long-term
|
||||
one or more [exporting connectors](https://github.com/netdata/netdata/blob/master/exporting/README.md) to send your Netdata metrics to other databases for long-term
|
||||
storage at lower granularity.
|
||||
|
||||
## Operation
|
||||
|
|
|
|||
|
|
@ -5,9 +5,9 @@ custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/Add-more-ch
|
|||
|
||||
# Add more charts to Netdata
|
||||
|
||||
This file has been deprecated. Please see our [collectors docs](/collectors/README.md) for more information.
|
||||
This file has been deprecated. Please see our [collectors docs](https://github.com/netdata/netdata/blob/master/collectors/README.md) for more information.
|
||||
|
||||
## Available data collection modules
|
||||
|
||||
See the [list of supported collectors](/collectors/COLLECTORS.md) to see all the sources Netdata can collect metrics
|
||||
See the [list of supported collectors](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md) to see all the sources Netdata can collect metrics
|
||||
from.
|
||||
|
|
|
|||
|
|
@ -353,7 +353,7 @@ If your apache server is not on localhost, you can set:
|
|||
|
||||
*note: Netdata v1.9+ support `allow connections from`*
|
||||
|
||||
`allow connections from` accepts [Netdata simple patterns](/libnetdata/simple_pattern/README.md) to match against the connection IP address.
|
||||
`allow connections from` accepts [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to match against the connection IP address.
|
||||
|
||||
## prevent the double access.log
|
||||
|
||||
|
|
|
|||
|
|
@ -105,7 +105,7 @@ Using the above, you access Netdata on the backend servers, like this:
|
|||
|
||||
### Encrypt the communication between H2O and Netdata
|
||||
|
||||
In case Netdata's web server has been [configured to use TLS](/web/server/README.md#enabling-tls-support), it is
|
||||
In case Netdata's web server has been [configured to use TLS](https://github.com/netdata/netdata/blob/master/web/server/README.md#enabling-tls-support), it is
|
||||
necessary to specify inside the H2O configuration that the final destination is using TLS. To do this, change the
|
||||
`http://` on the `proxy.reverse.url` line in your H2O configuration with `https://`
|
||||
|
||||
|
|
@ -173,7 +173,7 @@ If your H2O server is not on localhost, you can set:
|
|||
|
||||
*note: Netdata v1.9+ support `allow connections from`*
|
||||
|
||||
`allow connections from` accepts [Netdata simple patterns](/libnetdata/simple_pattern/README.md) to match against
|
||||
`allow connections from` accepts [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to match against
|
||||
the connection IP address.
|
||||
|
||||
## Prevent the double access.log
|
||||
|
|
|
|||
|
|
@ -173,7 +173,7 @@ Using the above, you access Netdata on the backend servers, like this:
|
|||
|
||||
### Encrypt the communication between Nginx and Netdata
|
||||
|
||||
In case Netdata's web server has been [configured to use TLS](/web/server/README.md#enabling-tls-support), it is
|
||||
In case Netdata's web server has been [configured to use TLS](https://github.com/netdata/netdata/blob/master/web/server/README.md#enabling-tls-support), it is
|
||||
necessary to specify inside the Nginx configuration that the final destination is using TLS. To do this, please, append
|
||||
the following parameters in your `nginx.conf`
|
||||
|
||||
|
|
@ -247,7 +247,7 @@ If your Nginx server is not on localhost, you can set:
|
|||
|
||||
*note: Netdata v1.9+ support `allow connections from`*
|
||||
|
||||
`allow connections from` accepts [Netdata simple patterns](/libnetdata/simple_pattern/README.md) to match against the
|
||||
`allow connections from` accepts [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to match against the
|
||||
connection IP address.
|
||||
|
||||
## Prevent the double access.log
|
||||
|
|
|
|||
|
|
@ -13,24 +13,24 @@ hosted web interface that gives you real-time visibility into your entire infras
|
|||
There are two main ways to use your Agent(s) with Netdata Cloud. You can use both these methods simultaneously, or just
|
||||
one, based on your needs:
|
||||
|
||||
- Use Netdata Cloud's web interface for monitoring an entire infrastructure, with any number of Agents, in one
|
||||
centralized dashboard.
|
||||
- Use **Visited nodes** to quickly navigate between the dashboards of nodes you've recently visited.
|
||||
- Use Netdata Cloud's web interface for monitoring an entire infrastructure, with any number of Agents, in one
|
||||
centralized dashboard.
|
||||
- Use **Visited nodes** to quickly navigate between the dashboards of nodes you've recently visited.
|
||||
|
||||
## Monitor an infrastructure with Netdata Cloud
|
||||
|
||||
We designed Netdata Cloud to help you see health and performance metrics, plus active alarms, in a single interface.
|
||||
Here's what a small infrastructure might look like:
|
||||
|
||||
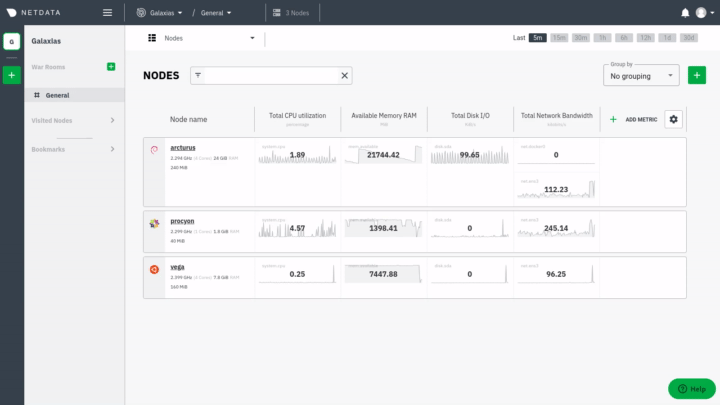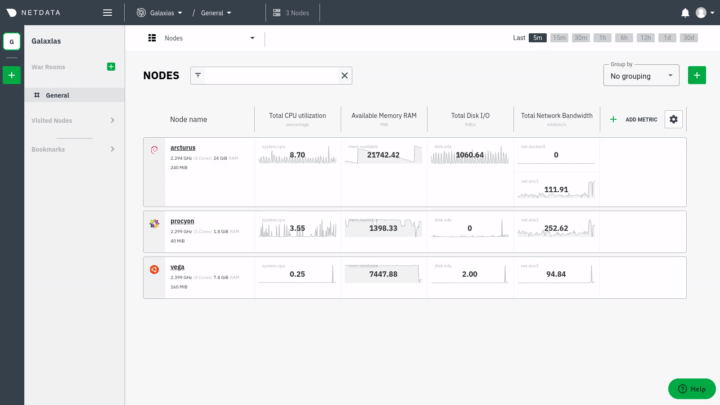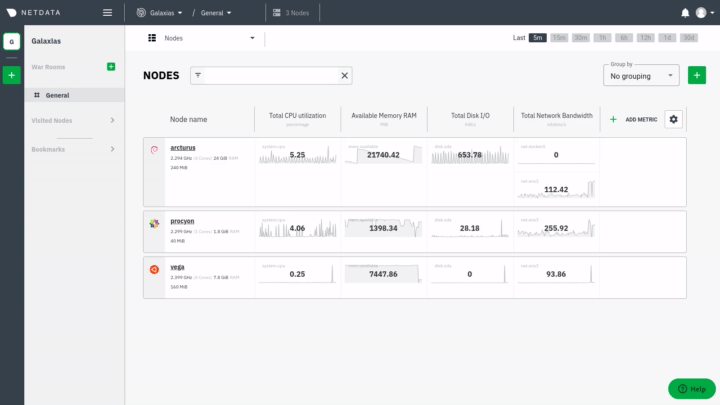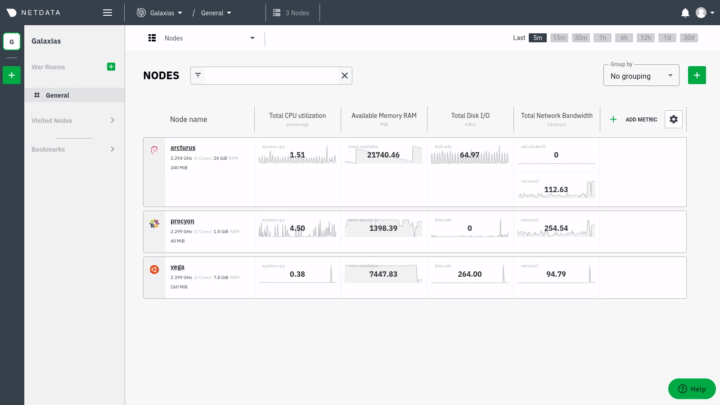
|
||||

|
||||
|
||||
[Read more about Netdata Cloud](https://learn.netdata.cloud/docs/cloud/) to better understand how it gives you real-time
|
||||
[Read more about Netdata Cloud](https://github.com/netdata/netdata/blob/master/docs/cloud/cloud.mdx) to better
|
||||
understand how it gives you real-time
|
||||
visibility into your entire infrastructure, and why you might consider using it.
|
||||
|
||||
Next, [get started in 5 minutes](https://learn.netdata.cloud/docs/cloud/get-started/), or read our [connection to Cloud
|
||||
reference](/claim/README.md) for a complete investigation of Cloud's security and encryption features, plus instructions
|
||||
for Docker containers.
|
||||
Next, [get started in 5 minutes](https://github.com/netdata/netdata/blob/master/docs/cloud/get-started.mdx), or read our
|
||||
[connection to Cloud reference](https://github.com/netdata/netdata/blob/master/claim/README.md) for a complete
|
||||
investigation of Cloud's security and encryption features, plus instructions for Docker containers.
|
||||
|
||||
## Navigate between dashboards with Visited nodes
|
||||
|
||||
|
|
@ -46,15 +46,13 @@ Netdata Cloud account, sign in with your preferred method.
|
|||
Cloud redirects you back to your node's dashboard, which is now connected to your Netdata Cloud account. You can now see
|
||||
the Visited nodes menu, which is populated by a single node.
|
||||
|
||||
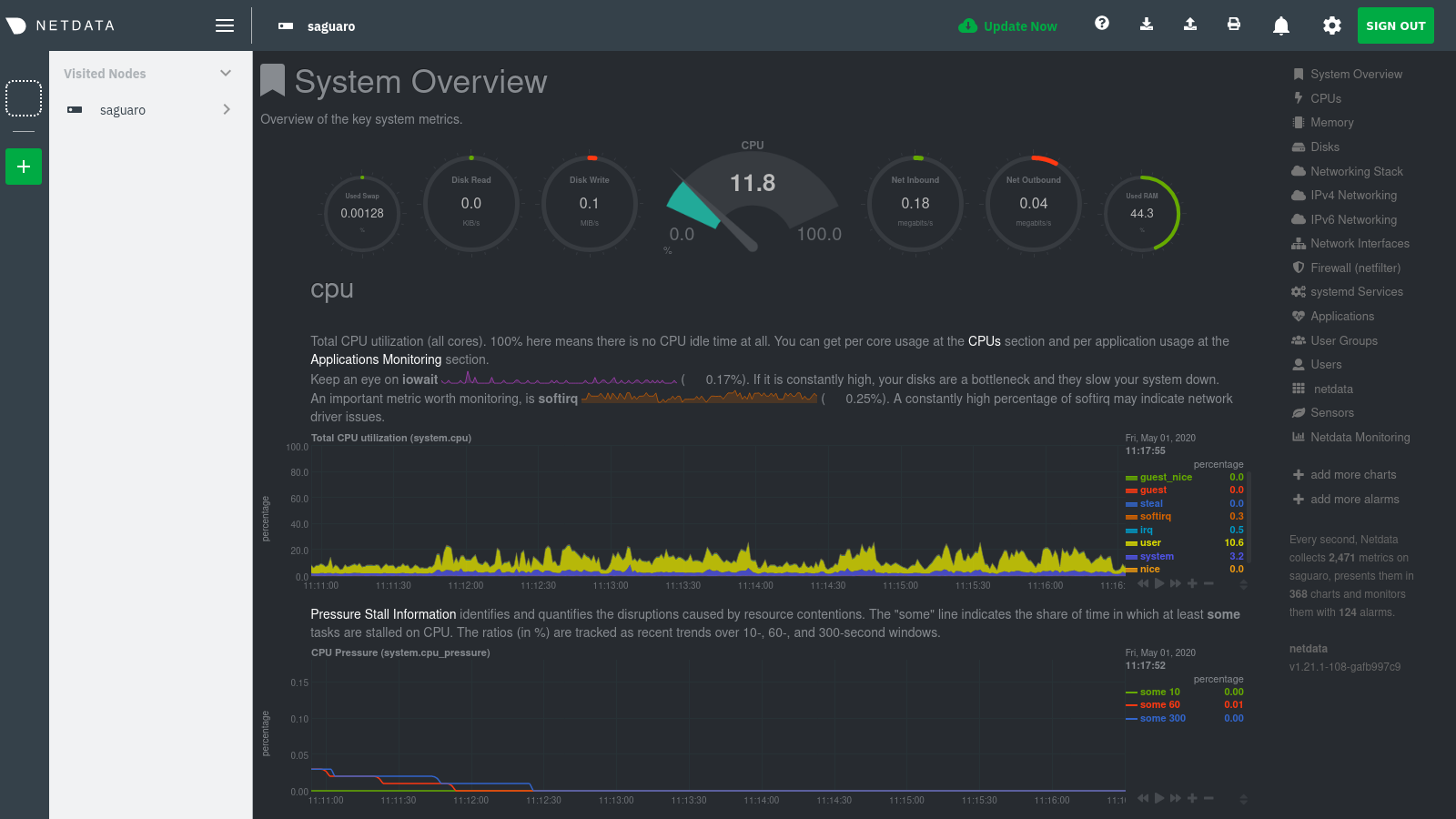
|
||||

|
||||
|
||||
If you previously went through the Cloud onboarding process to create a Space and War Room, you will also see these in
|
||||
the Visited Nodes menu. You can click on your Space or any of your War Rooms to navigate to Netdata Cloud and continue
|
||||
monitoring your infrastructure from there.
|
||||
|
||||
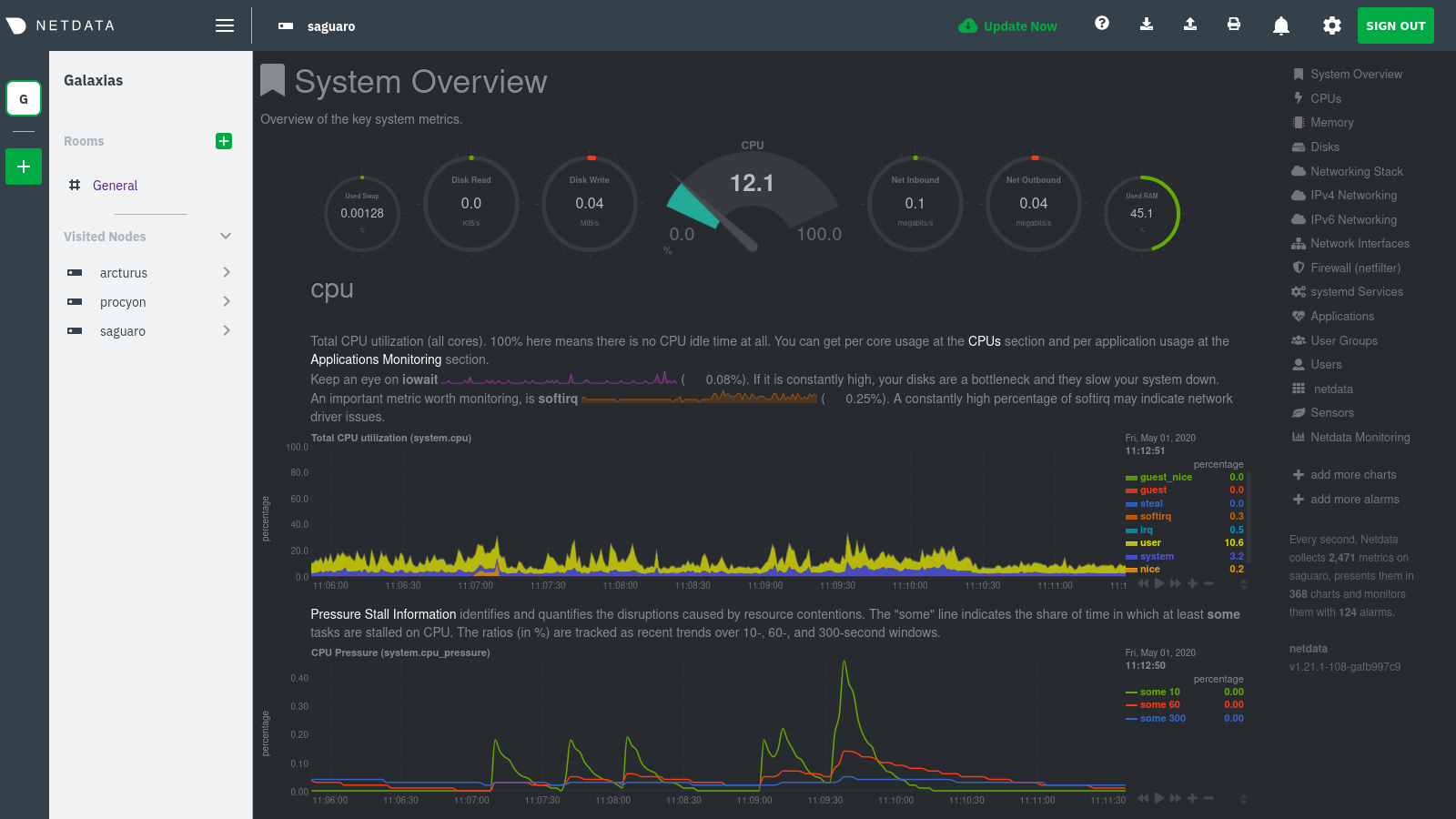
|
||||

|
||||
|
||||
To add more Agents to your Visited nodes menu, visit them and sign in again. This process connects that node to your
|
||||
Cloud account and further populates the menu.
|
||||
|
|
@ -62,16 +60,19 @@ Cloud account and further populates the menu.
|
|||
Once you've added more than one node, you can use the menu to switch between various dashboards without remembering IP
|
||||
addresses or hostnames or saving bookmarks for every node you want to monitor.
|
||||
|
||||
|
||||

|
||||
|
||||
## What's next?
|
||||
|
||||
The Agent-Cloud integration is highly adaptable to the needs of any infrastructure or user. If you want to learn more
|
||||
about how you might want to use or configure Cloud, we recommend the following:
|
||||
|
||||
- Get an overview of Cloud's features by reading [Cloud documentation](https://learn.netdata.cloud/docs/cloud/).
|
||||
- Follow the 5-minute [get started with Cloud](https://learn.netdata.cloud/docs/cloud/get-started/) guide to finish
|
||||
onboarding and connect your first nodes.
|
||||
- Better understand how agents connect securely to the Cloud with [connect agent to Cloud](/claim/README.md) and [Agent-Cloud
|
||||
link](/aclk/README.md) documentation.
|
||||
- Get an overview of Cloud's features by
|
||||
reading [Cloud documentation](https://github.com/netdata/netdata/blob/master/docs/cloud/cloud.mdx).
|
||||
- Follow the
|
||||
5-minute [get started with Cloud](https://github.com/netdata/netdata/blob/master/docs/cloud/cloud.mdx)
|
||||
guide to finish
|
||||
onboarding and connect your first nodes.
|
||||
- Better understand how agents connect securely to the Cloud
|
||||
with [connect agent to Cloud](https://github.com/netdata/netdata/blob/master/claim/README.md) and
|
||||
[Agent-Cloud link](https://github.com/netdata/netdata/blob/master/aclk/README.md) documentation.
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ We use the statistics gathered from this information for two purposes:
|
|||
|
||||
Netdata collects usage information via two different channels:
|
||||
|
||||
- **Agent dashboard**: We use the [PostHog JavaScript integration](https://posthog.com/docs/integrations/js-integration) (with sensitive event attributes overwritten to be anonymized) to send product usage events when you access an [Agent's dashboard](/web/gui/README.md).
|
||||
- **Agent dashboard**: We use the [PostHog JavaScript integration](https://posthog.com/docs/integrations/js-integration) (with sensitive event attributes overwritten to be anonymized) to send product usage events when you access an [Agent's dashboard](https://github.com/netdata/netdata/blob/master/web/gui/README.md).
|
||||
- **Agent backend**: The `netdata` daemon executes the [`anonymous-statistics.sh`](https://github.com/netdata/netdata/blob/6469cf92724644f5facf343e4bdd76ac0551a418/daemon/anonymous-statistics.sh.in) script when Netdata starts, stops cleanly, or fails.
|
||||
|
||||
You can opt-out from sending anonymous statistics to Netdata through three different [opt-out mechanisms](#opt-out).
|
||||
|
|
@ -65,7 +65,7 @@ Starting with v1.21, we additionally collect information about:
|
|||
|
||||
- Failures to build the dependencies required to use Cloud features.
|
||||
- Unavailability of Cloud features in an agent.
|
||||
- Failures to connect to the Cloud in case the [connection process](/claim/README.md) has been completed. This includes error codes
|
||||
- Failures to connect to the Cloud in case the [connection process](https://github.com/netdata/netdata/blob/master/claim/README.md) has been completed. This includes error codes
|
||||
to inform the Netdata team about the reason why the connection failed.
|
||||
|
||||
To see exactly what and how is collected, you can review the script template `daemon/anonymous-statistics.sh.in`. The
|
||||
|
|
@ -82,13 +82,13 @@ installation, including manual, offline, and macOS installations. Create the fil
|
|||
.opt-out-from-anonymous-statistics` from your Netdata configuration directory.
|
||||
|
||||
**Pass the option `--disable-telemetry` to any of the installer scripts in the [installation
|
||||
docs](/packaging/installer/README.md).** You can append this option during the initial installation or a manual
|
||||
docs](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md).** You can append this option during the initial installation or a manual
|
||||
update. You can also export the environment variable `DISABLE_TELEMETRY` with a non-zero or non-empty value
|
||||
(e.g: `export DISABLE_TELEMETRY=1`).
|
||||
|
||||
When using Docker, **set your `DISABLE_TELEMETRY` environment variable to `1`.** You can set this variable with the following
|
||||
command: `export DISABLE_TELEMETRY=1`. When creating a container using Netdata's [Docker
|
||||
image](/packaging/docker/README.md#create-a-new-netdata-agent-container) for the first time, this variable will disable
|
||||
image](https://github.com/netdata/netdata/blob/master/packaging/docker/README.md#create-a-new-netdata-agent-container) for the first time, this variable will disable
|
||||
the anonymous statistics script inside of the container.
|
||||
|
||||
Each of these opt-out processes does the following:
|
||||
|
|
|
|||
|
|
@ -1,6 +1,8 @@
|
|||
---
|
||||
title: "Alert notifications"
|
||||
description: "Configure Netdata Cloud to send notifications to your team whenever any node on your infrastructure triggers a pre-configured or custom alert threshold."
|
||||
description: >-
|
||||
"Configure Netdata Cloud to send notifications to your team whenever any node on your infrastructure
|
||||
triggers a pre-configured or custom alert threshold."
|
||||
custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.mdx"
|
||||
sidebar_label: "Alert notifications"
|
||||
learn_status: "Published"
|
||||
|
|
@ -108,26 +110,25 @@ the local Agent dashboard at `http://NODE:19999`.
|
|||
|
||||
Email alarm notifications show the following information:
|
||||
|
||||
- The Space's name
|
||||
- The node's name
|
||||
- Alarm status: critical, warning, cleared
|
||||
- Previous alarm status
|
||||
- Time at which the alarm triggered
|
||||
- Chart context that triggered the alarm
|
||||
- Name and information about the triggered alarm
|
||||
- Alarm value
|
||||
- Total number of warning and critical alerts on that node
|
||||
- Threshold for triggering the given alarm state
|
||||
- Calculation or database lookups that Netdata uses to compute the value
|
||||
- Source of the alarm, including which file you can edit to configure this alarm on an individual node
|
||||
- The Space's name
|
||||
- The node's name
|
||||
- Alarm status: critical, warning, cleared
|
||||
- Previous alarm status
|
||||
- Time at which the alarm triggered
|
||||
- Chart context that triggered the alarm
|
||||
- Name and information about the triggered alarm
|
||||
- Alarm value
|
||||
- Total number of warning and critical alerts on that node
|
||||
- Threshold for triggering the given alarm state
|
||||
- Calculation or database lookups that Netdata uses to compute the value
|
||||
- Source of the alarm, including which file you can edit to configure this alarm on an individual node
|
||||
|
||||
Email notifications also feature a **Go to Node** button, which takes you directly to the offending chart for that node
|
||||
within Cloud's embedded dashboards.
|
||||
|
||||
Here's an example email notification for the `ram_available` chart, which is in a critical state:
|
||||
|
||||
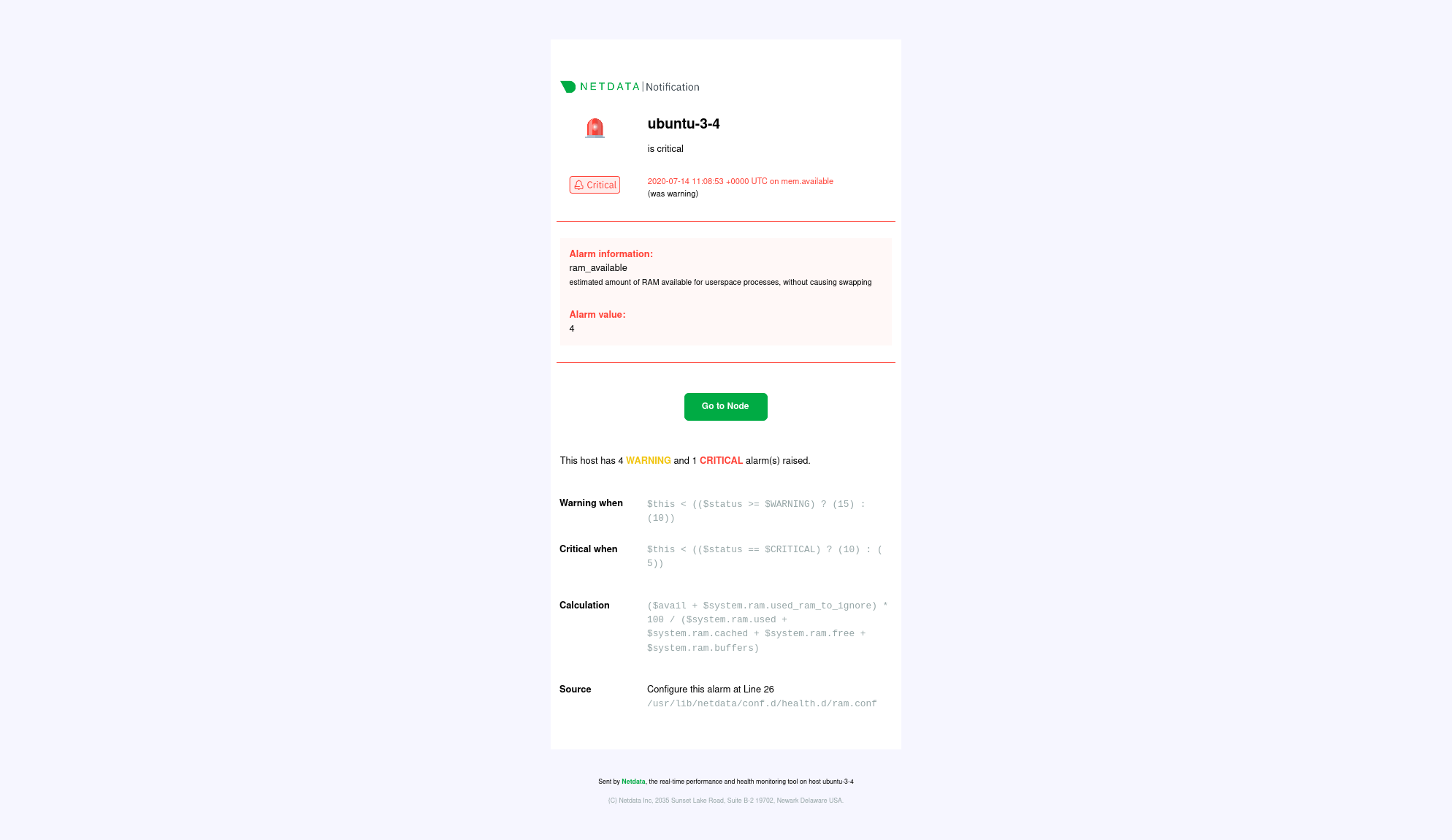
|
||||

|
||||
|
||||
## What's next?
|
||||
|
||||
|
|
@ -151,4 +152,4 @@ visualization of the health of your infrastructure.
|
|||
- [Add webhook notification configuration](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/add-webhook-notification-configuration.md)
|
||||
- [Add Discord notification configuration](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/add-discord-notification-configuration.md)
|
||||
- [Add Slack notification configuration](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/add-slack-notification-configuration.md)
|
||||
- [Add PagerDuty notification configuration](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/add-pagerduty-notification-configuration.md)
|
||||
- [Add PagerDuty notification configuration](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/add-pagerduty-notification-configuration.md)
|
||||
|
|
|
|||
|
|
@ -20,20 +20,22 @@ The Alerts view is available entirely for free to all users and for any number o
|
|||
The Alerts view shows all active alerts in your War Room, including the alert's name, the most recent value, a
|
||||
timestamp of when it became active, and the relevant node.
|
||||
|
||||
You can use the checkboxes in the filter pane on the right side of the screen to filter the alerts displayed in the table
|
||||
You can use the checkboxes in the filter pane on the right side of the screen to filter the alerts displayed in the
|
||||
table
|
||||
by Status, Class, Type & Componenet, Role, Operating System, or Node.
|
||||
|
||||
Click on any of the alert names to see the alert.
|
||||
|
||||
## View active alerts
|
||||
|
||||
In the `Active` subtab, you can see exactly how many **critical** and **warning** alerts are active across your nodes.
|
||||
In the `Active` subtab, you can see exactly how many **critical** and **warning** alerts are active across your nodes.
|
||||
|
||||
## View configured alerts
|
||||
## View configured alerts
|
||||
|
||||
You can view all the configured alerts on all the agents that belong to a War Room in the `Alert Configurations` subtab.
|
||||
From within the Alerts view, you can click the `Alert Configurations` subtab to see a high level view of the states of
|
||||
the alerts on the nodes within this War Room and drill down to the node level where each alert is configured with their latest status.
|
||||
You can view all the configured alerts on all the agents that belong to a War Room in the `Alert Configurations` subtab.
|
||||
From within the Alerts view, you can click the `Alert Configurations` subtab to see a high level view of the states of
|
||||
the alerts on the nodes within this War Room and drill down to the node level where each alert is configured with their
|
||||
latest status.
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -1,6 +1,8 @@
|
|||
---
|
||||
title: "View active alerts"
|
||||
description: "Track the health of your infrastructure in one place by taking advantage of the powerful health monitoring watchdog running on every node."
|
||||
description: >-
|
||||
"Track the health of your infrastructure in one place by taking advantage of the powerful health monitoring
|
||||
watchdog running on every node."
|
||||
type: "how-to"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/view-active-alerts.mdx"
|
||||
sidebar_label: "View active alerts"
|
||||
|
|
@ -17,23 +19,27 @@ infrastructure based on their configuration. Every node comes with hundreds of p
|
|||
tested by Netdata's community of DevOps engineers and SREs, but you may want to customize existing alerts or create new
|
||||
ones entirely.
|
||||
|
||||
Read our doc on [health alerts](/docs/monitor/configure-alarms) to learn how to tweak existing alerts or create new
|
||||
Read our doc on [health alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/configure-alarms.md) to
|
||||
learn how to tweak existing alerts or create new
|
||||
health entities based on the specific needs of your infrastructure. By taking charge of alert configuration, you'll
|
||||
ensure Netdata Cloud always delivers the most relevant alerts about the well-being of your nodes.
|
||||
|
||||
## View all active alerts
|
||||
|
||||
The [Alerts Smartboard](/docs/cloud/alerts-notifications/smartboard) provides a high-level interface for viewing the
|
||||
number of critical or warning alerts and where they are in your infrastructure.
|
||||
The [Alerts Smartboard](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/smartboard.mdx)
|
||||
provides a high-level interface for viewing the number of critical or warning alerts and where they are in your
|
||||
infrastructure.
|
||||
|
||||
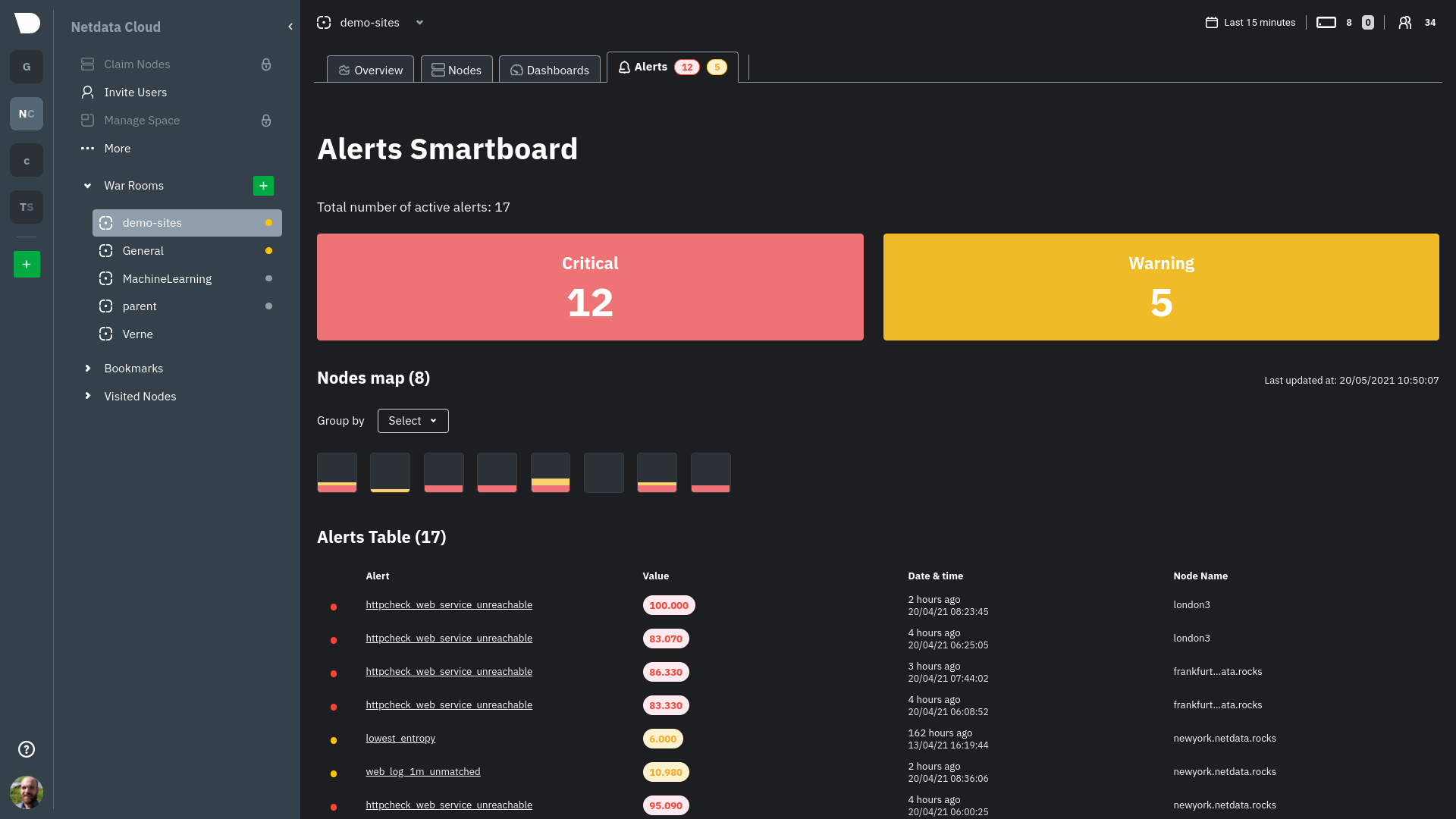
|
||||

|
||||
|
||||
Click on the **Alerts** tab in any War Room to open the Smartboard. Alternatively, click on any of the alert badges in
|
||||
the [Nodes view](/docs/cloud/visualize/nodes) to jump to the Alerts Smartboard.
|
||||
the [Nodes view](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/nodes.md) to jump to the Alerts
|
||||
Smartboard.
|
||||
|
||||
From here, filter active alerts using the **critical** or **warning** boxes, or hover over a box in the [nodes
|
||||
map](/docs/cloud/alerts-notifications/smartboard#nodes-map) to see a popup node-specific alert information.
|
||||
From here, filter active alerts using the **critical** or **warning** boxes, or hover over a box in
|
||||
the [nodes map](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/smartboard.mdx#nodes-map)
|
||||
to see a
|
||||
popup node-specific alert information.
|
||||
|
||||
## View alerts in context with charts
|
||||
|
||||
|
|
@ -41,23 +47,30 @@ If you click on any of the alerts, either in a nodes map popup or the alerts tab
|
|||
single-node dashboard and scrolls to the relevant chart. Netdata Cloud also draws a highlight and the value at the
|
||||
moment your node triggered this alert.
|
||||
|
||||
|
||||

|
||||
|
||||
You can then [select this area](/docs/dashboard/interact-charts#select) with `Alt/⌘ + mouse selection` to highlight the
|
||||
alerted timeframe while you explore other charts for root cause analysis.
|
||||
You can
|
||||
then [select this area](https://github.com/netdata/netdata/blob/master/docs/dashboard/interact-charts.mdx#select)
|
||||
with `Alt/⌘ + mouse selection` to highlight the alerted timeframe while you explore other charts for root cause
|
||||
analysis.
|
||||
|
||||
Or, select the area and run [Metric Correlations](/docs/cloud/insights/metric-correlations) to filter the single-node
|
||||
Or, select the area and
|
||||
run [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md) to
|
||||
filter the single-node
|
||||
dashboard to only those charts most likely to be connected to the alert.
|
||||
|
||||
## What's next?
|
||||
|
||||
Learn more about the features of the Smartboard in its [reference](/docs/cloud/alerts-notifications/smartboard) doc. To
|
||||
stay notified of active alerts, enable [centralized alert notifications](/docs/cloud/alerts-notifications/notifications)
|
||||
Learn more about the features of the Smartboard in
|
||||
its [reference](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/smartboard.mdx)
|
||||
doc. To stay notified of active alerts,
|
||||
enable [centralized alert notifications](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.mdx)
|
||||
from Netdata Cloud.
|
||||
|
||||
If you're through with setting up alerts, it might be time to [invite your
|
||||
team](/docs/cloud/manage/invite-your-team).
|
||||
If you're through with setting up alerts, it might be time
|
||||
to [invite your team](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/invite-your-team.md).
|
||||
|
||||
Check out our recommendations on organizing and using [Spaces](/docs/cloud/spaces) and [War
|
||||
Rooms](/docs/cloud/war-rooms) to streamline your processes once you find an alert in Netdata Cloud.
|
||||
Check out our recommendations on organizing and
|
||||
using [Spaces](https://github.com/netdata/netdata/blob/master/docs/cloud/spaces.md) and
|
||||
[War Rooms](https://github.com/netdata/netdata/blob/master/docs/cloud/war-rooms.md) to streamline your processes once
|
||||
you find an alert in Netdata Cloud.
|
||||
|
|
|
|||
|
|
@ -19,7 +19,7 @@ that you have specifically requested. Features that will be developed on the new
|
|||
## Enabling the new architecture
|
||||
|
||||
To enable the new architecture, first ensure that you have installed the latest Netdata version following
|
||||
[our guide](https://learn.netdata.cloud/docs/get-started/). Then, you or your administrator will need to retrieve the Space IDs
|
||||
[our guide](https://github.com/netdata/netdata/blob/master/docs/get-started.mdx). Then, you or your administrator will need to retrieve the Space IDs
|
||||
within Netdata Cloud by clicking `Manage Space` in the left pane, selecting the `Space` tab, and copying the value in the `Space Id` field.
|
||||
You can then send an email to [beta@Netdata.cloud](mailto:beta@netdata.cloud) requesting to be included in our beta testers, and include
|
||||
in the body of the email a list of Space IDs for any space you would like to have whitelisted for the update. If you received an email
|
||||
|
|
|
|||
|
|
@ -18,7 +18,7 @@ and metadata are streamed to Netdata Cloud, then proxied to your browser, with a
|
|||
privacy <RiExternalLinkLine className="inline-block" />](https://netdata.cloud/privacy/).
|
||||
|
||||
|
||||
Read [_What is Netdata?_](/docs/overview/what-is-netdata) for details about how Netdata and Netdata Cloud work together
|
||||
Read [_What is Netdata?_](https://github.com/netdata/netdata/blob/master/docs/overview/what-is-netdata.md) for details about how Netdata and Netdata Cloud work together
|
||||
and how they're different from other monitoring solutions, or the
|
||||
[FAQ <RiExternalLinkLine className="inline-block" />](https://community.netdata.cloud/tags/c/general/29/faq) for answers to common questions.
|
||||
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ learn_rel_path: "Concepts"
|
|||
you. This is why **we don't store any metric data in Netdata Cloud**.
|
||||
|
||||
Your local installations of the Netdata Agent form the basis for the Netdata Cloud. All the data that you see in the web browser when using Netdata Cloud, is actually streamed directly from the Netdata Agent to the Netdata Cloud dashboard.
|
||||
The data passes through our systems, but it isn't stored. You can learn more about [the Agent's security design](https://learn.netdata.cloud/docs/agent/netdata-security) in the Agent documentation.
|
||||
The data passes through our systems, but it isn't stored. You can learn more about [the Agent's security design](https://github.com/netdata/netdata/blob/master/docs/netdata-security.md) in the Agent documentation.
|
||||
|
||||
However, to be able to offer the stunning visualizations and advanced functionality of Netdata Cloud, it does store a limited number of _metadata_.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,6 +1,8 @@
|
|||
---
|
||||
title: "Get started with Netdata Cloud"
|
||||
description: "Ready to get real-time visibility into your entire infrastructure? This guide will help you get started on Netdata Cloud."
|
||||
description: >-
|
||||
"Ready to get real-time visibility into your entire infrastructure? This guide will help you get started on
|
||||
Netdata Cloud."
|
||||
image: "/img/seo/cloud_get-started.png"
|
||||
custom_edit_url: "https://github.com/netdata/learn/blob/master/docs/cloud/get-started.mdx"
|
||||
---
|
||||
|
|
@ -14,15 +16,16 @@ the onboarding process, such as setting up your Space and War Room and connectin
|
|||
## Before you start
|
||||
|
||||
Before you get started with Netdata Cloud, you should have the open-source Netdata monitoring agent installed. See our
|
||||
[installation guide](/docs/get-started) for details.
|
||||
[installation guide](https://github.com/netdata/netdata/blob/master/docs/get-started.mdx) for details.
|
||||
|
||||
If you already have the Netdata agent running on your node(s), make sure to update it to v1.32 or higher. Read the
|
||||
[updating documentation](/docs/agent/packaging/installer/update/) for information on how to update based on the method
|
||||
you used to install Netdata on that node.
|
||||
[updating documentation](https://github.com/netdata/netdata/blob/master/packaging/installer/UPDATE.md) for information
|
||||
on how to update based on the method you used to install Netdata on that node.
|
||||
|
||||
## Begin the onboarding process
|
||||
|
||||
Get started by signing in to Netdata. Read the [sign in](/docs/cloud/manage/sign-in) doc for details on the
|
||||
Get started by signing in to Netdata. Read
|
||||
the [sign in](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/sign-in.mdx) doc for details on the
|
||||
authentication methods we use.
|
||||
|
||||
<Link to="https://app.netdata.cloud" className="group">
|
||||
|
|
@ -32,33 +35,45 @@ authentication methods we use.
|
|||
</button>
|
||||
</Link>
|
||||
|
||||
Once signed in with your preferred method, a General [War Room](/docs/cloud/war-rooms) and a [Space](/docs/cloud/spaces)
|
||||
named for your login email are automatically created. You can configure more Spaces and War Rooms to help you you organize your team
|
||||
and the many systems that make up your infrastructure. For example, you can put product and infrastructure SRE teams in separate
|
||||
Spaces, and then use War Rooms to group nodes by their service (`nginx`), purpose (`webservers`), or physical location (`IAD`).
|
||||
Once signed in with your preferred method, a
|
||||
General [War Room](https://github.com/netdata/netdata/blob/master/docs/cloud/war-rooms.md) and
|
||||
a [Space](https://github.com/netdata/netdata/blob/master/docs/cloud/spaces.md)
|
||||
named for your login email are automatically created. You can configure more Spaces and War Rooms to help you you
|
||||
organize your team
|
||||
and the many systems that make up your infrastructure. For example, you can put product and infrastructure SRE teams in
|
||||
separate
|
||||
Spaces, and then use War Rooms to group nodes by their service (`nginx`), purpose (`webservers`), or physical
|
||||
location (`IAD`).
|
||||
|
||||
Don't worry! You can always add more Spaces and War Rooms later if you decide to reorganize how you use Netdata Cloud.
|
||||
|
||||
## Connect your nodes
|
||||
|
||||
From within the created War Rooms, Netdata Cloud prompts you to [connect](/docs/agent/claim) your nodes to Netdata Cloud. Non-admin
|
||||
users can users can select from existing nodes already connected to the space or select an admin from a provided list to connect node.
|
||||
You can connect any node running Netdata, whether it's a physical or virtual machine, a Docker container, IoT device, and more.
|
||||
From within the created War Rooms, Netdata Cloud prompts you
|
||||
to [connect](https://github.com/netdata/netdata/blob/master/claim/README.md) your nodes to Netdata Cloud. Non-admin
|
||||
users can users can select from existing nodes already connected to the space or select an admin from a provided list to
|
||||
connect node.
|
||||
You can connect any node running Netdata, whether it's a physical or virtual machine, a Docker container, IoT device,
|
||||
and more.
|
||||
|
||||
The connection process securely connects any node to Netdata Cloud using the [Agent-Cloud link](/docs/agent/aclk). By
|
||||
connecting a node, you prove you have write and administrative access to that node. Connecting to Cloud also prevents any third party
|
||||
The connection process securely connects any node to Netdata Cloud using
|
||||
the [Agent-Cloud link](https://github.com/netdata/netdata/blob/master/aclk/README.md). By
|
||||
connecting a node, you prove you have write and administrative access to that node. Connecting to Cloud also prevents
|
||||
any third party
|
||||
from connecting a node that you control. Keep in mind:
|
||||
|
||||
- _You can only connect any given node in a single Space_. You can, however, add that connected node to multiple War Rooms
|
||||
- _You can only connect any given node in a single Space_. You can, however, add that connected node to multiple War
|
||||
Rooms
|
||||
within that one Space.
|
||||
- You must repeat the connection process on every node you want to add to Netdata Cloud.
|
||||
|
||||
<Callout type="notice">
|
||||
|
||||
**Netdata Cloud ensures your data privacy by not storing metrics data from your nodes**. See our statement on Netdata
|
||||
Cloud [data privacy](/docs/agent/aclk/#data-privacy) for details on the data that's streamed from your nodes and the
|
||||
[connecting to cloud](/docs/agent/claim) doc for details about why we implemented the connection process and the encryption methods
|
||||
we use to secure your data in transit.
|
||||
Cloud [data privacy](https://github.com/netdata/netdata/blob/master/aclk/README.md/#data-privacy) for details on the
|
||||
data that's streamed from your nodes and the
|
||||
[connecting to cloud](https://github.com/netdata/netdata/blob/master/claim/README.md) doc for details about why we
|
||||
implemented the connection process and the encryption methods we use to secure your data in transit.
|
||||
|
||||
</Callout>
|
||||
|
||||
|
|
@ -66,23 +81,27 @@ To connect a node, select which War Rooms you want to add this node to with the
|
|||
Netdata Cloud into your node's terminal.
|
||||
|
||||
Hit **Enter**. The script should return `Agent was successfully claimed.`. If the claiming script returns errors, or if
|
||||
you don't see the node in your Space after 60 seconds, see the [troubleshooting
|
||||
information](/docs/agent/claim#troubleshooting).
|
||||
you don't see the node in your Space after 60 seconds, see
|
||||
the [troubleshooting information](https://github.com/netdata/netdata/blob/master/claim/README.md#troubleshooting).
|
||||
|
||||
Repeat this process with every node you want to add to Netdata Cloud during onboarding. You can also add more nodes once
|
||||
you've finished onboarding by clicking the **Connect Nodes** button in the [Space management
|
||||
area](/docs/cloud/spaces/#manage-spaces).
|
||||
you've finished onboarding by clicking the **Connect Nodes** button in
|
||||
the [Space management area](https://github.com/netdata/netdata/blob/master/docs/cloud/spaces.md/#manage-spaces).
|
||||
|
||||
### Alternatives and other operating systems
|
||||
|
||||
**Docker**: You can execute the claiming script Netdata running as a Docker container, or attach the claiming script
|
||||
when creating the container for the first time, such as when you're spinning up ephemeral containers. See the [connect an agent running in Docker](/docs/agent/claim#connect-an-agent-running-in-docker) documentation for details.
|
||||
when creating the container for the first time, such as when you're spinning up ephemeral containers. See
|
||||
the [connect an agent running in Docker](https://github.com/netdata/netdata/blob/master/claim/README.md#connect-an-agent-running-in-docker)
|
||||
documentation for details.
|
||||
|
||||
**Without root privileges**: If you want to connect an agent without using root privileges, see our [connect
|
||||
documentation](/docs/agent/claim#connect-an-agent-without-root-privileges).
|
||||
documentation](https://github.com/netdata/netdata/blob/master/claim/README.md#connect-an-agent-without-root-privileges).
|
||||
|
||||
**With a proxy**: If your node uses a proxy to connect to the internet, you need to configure the node's proxy settings.
|
||||
See our [connect through a proxy](/docs/agent/claim#connect-through-a-proxy) doc for details.
|
||||
See
|
||||
our [connect through a proxy](https://github.com/netdata/netdata/blob/master/claim/README.md#connect-through-a-proxy)
|
||||
doc for details.
|
||||
|
||||
## Add bookmarks to essential resources
|
||||
|
||||
|
|
@ -99,11 +118,16 @@ short description for your team's reference.
|
|||
|
||||
## What's next?
|
||||
|
||||
You finish onboarding by [inviting members of your team](/docs/cloud/manage/invite-your-team) to your Space. You
|
||||
You finish onboarding
|
||||
by [inviting members of your team](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/invite-your-team.md)
|
||||
to your Space. You
|
||||
can also invite them later. At this point, you're ready to use Cloud.
|
||||
|
||||
Next, learn about the organization and interfaces behind [Spaces](/docs/cloud/spaces) and [War
|
||||
Rooms](/docs/cloud/war-rooms).
|
||||
Next, learn about the organization and interfaces
|
||||
behind [Spaces](https://github.com/netdata/netdata/blob/master/docs/cloud/spaces.md)
|
||||
and [War
|
||||
Rooms](https://github.com/netdata/netdata/blob/master/docs/cloud/war-rooms.md).
|
||||
|
||||
If you're ready to explore, check out how to use the [Overview dashboard](/docs/cloud/visualize/overview), which is the
|
||||
If you're ready to explore, check out how to use
|
||||
the [Overview dashboard](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md), which is the
|
||||
default view for each new War Room you create.
|
||||
|
|
|
|||
|
|
@ -32,9 +32,9 @@ To enable ML on your Netdata Agent, you need to edit the `[ml]` section in your
|
|||
|
||||
At a minimum you just need to set `enabled = yes` to enable ML with default params. More details about configuration can be found in the [Netdata Agent ML docs](https://learn.netdata.cloud/docs/agent/ml#configuration).
|
||||
|
||||
**Note**: Follow [this guide](https://learn.netdata.cloud/guides/step-by-step/step-04) if you are unfamiliar with making configuration changes in Netdata.
|
||||
**Note**: Follow [this guide](https://github.com/netdata/netdata/blob/master/docs/guides/step-by-step/step-04.md) if you are unfamiliar with making configuration changes in Netdata.
|
||||
|
||||
When you have finished your configuration, restart Netdata with a command like `sudo systemctl restart netdata` for the config changes to take effect. You can find more info on restarting Netdata [here](https://learn.netdata.cloud/docs/configure/start-stop-restart).
|
||||
When you have finished your configuration, restart Netdata with a command like `sudo systemctl restart netdata` for the config changes to take effect. You can find more info on restarting Netdata [here](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md).
|
||||
|
||||
After a brief delay, you should see the number of `trained` dimensions start to increase on the "dimensions" chart of the "Anomaly Detection" menu on the Overview page. By default the `minimum num samples to train = 3600` parameter means at least 1 hour of data is required to train initial models, but you could set this to `900` if you want to train initial models quicker but on less data. Over time, they will retrain on up to `maximum num samples to train = 14400` (4 hours by default), but you could increase this is you wanted to train on more data.
|
||||
|
||||
|
|
|
|||
|
|
@ -53,7 +53,7 @@ Behind the scenes, Netdata will aggregate the raw data as needed such that arbit
|
|||
|
||||
Netdata is different from typical observability agents since, in addition to just collecting raw metric values, it will by default also assign an "[Anomaly Bit](/docs/agent/ml#anomaly-bit)" related to each collected metric each second. This bit will be 0 for "normal" and 1 for "anomalous". This means that each metric also natively has an "[Anomaly Rate](/docs/agent/ml#anomaly-rate)" associated with it and, as such, MC can be run against the raw metric values or their corresponding anomaly rates.
|
||||
|
||||
**Note**: Read more [here](https://learn.netdata.cloud/guides/monitor/anomaly-detection) to learn more about the native anomaly detection features within netdata.
|
||||
**Note**: Read more [here](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection.md) to learn more about the native anomaly detection features within netdata.
|
||||
|
||||
- `Metrics` - Run MC on the raw metric values.
|
||||
- `Anomaly Rate` - Run MC on the corresponding anomaly rate for each metric.
|
||||
|
|
@ -84,4 +84,4 @@ Should you still want to, disabling nodes for Metric Correlation on the agent is
|
|||
|
||||
## What's next?
|
||||
|
||||
You can read more about all the ML powered capabilities of Netdata [here](https://learn.netdata.cloud/guides/monitor/anomaly-detection). If you aren't yet familiar with the power of Netdata Cloud's visualization features, check out the [Nodes view](/docs/cloud/visualize/nodes) and learn how to [build new dashboards](/docs/cloud/visualize/dashboards).
|
||||
You can read more about all the ML powered capabilities of Netdata [here](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection.md). If you aren't yet familiar with the power of Netdata Cloud's visualization features, check out the [Nodes view](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/nodes.md) and learn how to [build new dashboards](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md).
|
||||
|
|
|
|||
|
|
@ -1,6 +1,8 @@
|
|||
---
|
||||
title: "Invite your team"
|
||||
description: "Invite your entire SRE, DevOPs, or ITOps team to Netdata Cloud to give everyone insights into your infrastructure from a single pane of glass."
|
||||
description: >-
|
||||
"Invite your entire SRE, DevOPs, or ITOps team to Netdata Cloud to give everyone insights into your
|
||||
infrastructure from a single pane of glass."
|
||||
custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/cloud/manage/invite-your-team.md"
|
||||
sidebar_label: "Invite your team"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,10 +10,10 @@ learn_topic_type: "Tasks"
|
|||
learn_rel_path: "Operations"
|
||||
---
|
||||
|
||||
Invite new users to your Space by clicking on **Invite Users** in the [Space](/docs/cloud/spaces) management area.
|
||||
Invite new users to your Space by clicking on **Invite Users** in
|
||||
the [Space](https://github.com/netdata/netdata/blob/master/docs/cloud/spaces.md) management area.
|
||||
|
||||
|
||||

|
||||
|
||||
Enter the email addresses for the users you want to invite to your Space. You can enter any number of email addresses,
|
||||
separated by a comma, to send multiple invitations at once.
|
||||
|
|
@ -19,17 +21,17 @@ separated by a comma, to send multiple invitations at once.
|
|||
Next, choose the War Rooms you want to invite these users to. Once logged in, these users are not restricted only to
|
||||
these War Rooms. They can be invited to others, or join any that are public.
|
||||
|
||||
Click the **Send** button to send an email invitation, which will prompt them to [sign up](/docs/cloud/manage/sign-in)
|
||||
and join your Space.
|
||||
Click the **Send** button to send an email invitation, which will prompt them
|
||||
to [sign up](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/sign-in.mdx) and join your Space.
|
||||
|
||||
|
||||

|
||||
|
||||
Any unaccepted invitations remain under **Invitations awaiting response**. These invitations can be rescinded at any
|
||||
time by clicking the trash can icon.
|
||||
|
||||
## What's next?
|
||||
|
||||
If your team members have trouble signing in, direct them to the [sign in guide](/docs/cloud/manage/sign-in). Once your
|
||||
team is onboarded to Netdata Cloud, they can view shared assets, such as [new
|
||||
dashboards](https://learn.netdata.cloud/docs/cloud/visualize/dashboards).
|
||||
If your team members have trouble signing in, direct them to
|
||||
the [sign in guide](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/sign-in.mdx). Once your
|
||||
team is onboarded to Netdata Cloud, they can view shared assets, such
|
||||
as [new dashboards](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md).
|
||||
|
|
|
|||
|
|
@ -35,7 +35,7 @@ If you don't have a Netdata Cloud account yet you won't need to worry about it.
|
|||
After your account is created and you sign in to Netdata, you first are asked to agree to Netdata Cloud's [Privacy
|
||||
Policy](https://www.netdata.cloud/privacy/) and [Terms of Use](https://www.netdata.cloud/terms/). Once you agree with these you are directed
|
||||
through the Netdata Cloud onboarding process, which is explained in the [Netdata Cloud
|
||||
quickstart](/docs/cloud/get-started).
|
||||
quickstart](https://github.com/netdata/netdata/blob/master/docs/cloud/get-started.mdx).
|
||||
|
||||
### Troubleshooting
|
||||
|
||||
|
|
@ -84,5 +84,5 @@ It is not currently possible to link an account created with `user@example.com`
|
|||
|
||||
## What's next?
|
||||
|
||||
If you haven't already onboarded to Netdata Cloud and connected your first nodes, visit the [get started
|
||||
guide](/docs/cloud/get-started).
|
||||
If you haven't already onboarded to Netdata Cloud and connected your first nodes, visit
|
||||
the [get started guide](https://github.com/netdata/netdata/blob/master/docs/cloud/get-started.mdx).
|
||||
|
|
|
|||
|
|
@ -1,6 +1,8 @@
|
|||
---
|
||||
title: "Spaces"
|
||||
description: " Organize your infrastructure monitoring on Netdata Cloud by creating Spaces, then groupingyour Agent-monitored nodes. "
|
||||
description: >-
|
||||
"Organize your infrastructure monitoring on Netdata Cloud by creating Spaces, then groupingyour
|
||||
Agent-monitored nodes."
|
||||
custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/cloud/spaces.md"
|
||||
sidebar_label: "Spaces"
|
||||
learn_status: "Published"
|
||||
|
|
@ -27,8 +29,9 @@ The other consideration for the number of Spaces you use to organize your Netdat
|
|||
complexity of your organization.
|
||||
|
||||
For small team and infrastructures we recommend sticking to a single Space so that you can keep all your nodes and their
|
||||
respective metrics in one place. You can then use multiple [War Rooms](/docs/cloud/war-rooms) to further organize your
|
||||
infrastructure monitoring.
|
||||
respective metrics in one place. You can then use
|
||||
multiple [War Rooms](https://github.com/netdata/netdata/blob/master/docs/cloud/war-rooms.md)
|
||||
to further organize your infrastructure monitoring.
|
||||
|
||||
Enterprises may want to create multiple Spaces for each of their larger teams, particularly if those teams have
|
||||
different responsibilities or parts of the overall infrastructure to monitor. For example, you might have one SRE team
|
||||
|
|
@ -57,9 +60,10 @@ will open a side tab in which you can:
|
|||
2. _Edit the War Rooms*_, click on the **War rooms** tab to add or remove War Rooms.
|
||||
|
||||
3. _Connect nodes*_, click on **Nodes** tab. Copy the claiming script to your node and run it. See the
|
||||
[connect to Cloud doc](/docs/agent/claim) for details.
|
||||
[connect to Cloud doc](https://github.com/netdata/netdata/blob/master/claim/README.md) for details.
|
||||
|
||||
4. _Manage the users*_, click on **Users**. The [invitation doc](/docs/cloud/manage/invite-your-team)
|
||||
4. _Manage the users*_, click on **Users**.
|
||||
The [invitation doc](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/invite-your-team.md)
|
||||
details the invitation process.
|
||||
|
||||
5. _Manage notification setting*_, click on **Notifications** tab to turn off/on notification methods.
|
||||
|
|
@ -83,4 +87,5 @@ Netdata admin users now have the ability to remove obsolete nodes from a space.
|
|||
|
||||
## What's next?
|
||||
|
||||
Once you configured your Spaces, it's time to set up your [War Rooms](/docs/cloud/war-rooms).
|
||||
Once you configured your Spaces, it's time to set up
|
||||
your [War Rooms](https://github.com/netdata/netdata/blob/master/docs/cloud/war-rooms.md).
|
||||
|
|
|
|||
|
|
@ -1,6 +1,8 @@
|
|||
---
|
||||
title: "Build new dashboards"
|
||||
description: "Design new dashboards that target your infrastructure's unique needs and share them with your team for targeted visual anomaly detection or incident response."
|
||||
description: >-
|
||||
"Design new dashboards that target your infrastructure's unique needs and share them with your team for
|
||||
targeted visual anomaly detection or incident response."
|
||||
custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md"
|
||||
sidebar_label: "Build new dashboards"
|
||||
learn_status: "Published"
|
||||
|
|
@ -24,7 +26,7 @@ In the modal, give your new dashboard a name, and click **+ Add**.
|
|||
|
||||
Click the **Add Chart** button to add your first chart card. From the dropdown, select either *All Nodes** or a specific
|
||||
node. If you select **All Nodes**, you will add a [composite chart](/docs/cloud/visualize/overview#composite-charts) to
|
||||
your new dashboard. Next, select the context. You'll see a preview of the chart before you finish adding it.
|
||||
your new dashboard. Next, select the context. You'll see a preview of the chart before you finish adding it.
|
||||
|
||||
The **Add Text** button creates a new card with user-defined text, which you can use to describe or document a
|
||||
particular dashboard's meaning and purpose.
|
||||
|
|
@ -46,8 +48,8 @@ node. If you select **All Nodes**, you will add a [composite chart](/docs/cloud/
|
|||
your new dashboard. Next, select the context. You'll see a preview of the chart before you finish adding it.
|
||||
|
||||
The charts you add to any dashboard are fully interactive, just like the charts in an Agent dashboard or a single node's
|
||||
dashboard in Cloud. Zoom in and out, highlight timeframes, and more. See our [Agent dashboard
|
||||
docs](https://learn.netdata.cloud/docs/agent/web#using-charts) for all the shortcuts.
|
||||
dashboard in Cloud. Zoom in and out, highlight timeframes, and more. See our
|
||||
[Agent dashboard docs](https://learn.netdata.cloud/docs/agent/web#using-charts) for all the shortcuts.
|
||||
|
||||
Charts also synchronize as you interact with them, even across contexts _or_ nodes.
|
||||
|
||||
|
|
@ -114,6 +116,7 @@ Because of the visual complexity of individual charts, dashboards require a mini
|
|||
|
||||
## What's next?
|
||||
|
||||
Once you've designed a dashboard or two, make sure to [invite your team](/docs/cloud/manage/invite-your-team) if
|
||||
Once you've designed a dashboard or two, make sure
|
||||
to [invite your team](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/invite-your-team.md) if
|
||||
you haven't already. You can add these new users to the same War Room to let them see the same dashboards without any
|
||||
effort.
|
||||
|
|
|
|||
|
|
@ -1,6 +1,8 @@
|
|||
---
|
||||
title: "Interact with charts"
|
||||
description: "Learn how to get the most out of Netdata's charts. These charts will help you make sense of all the metrics at your disposal, helping you troubleshoot with real-time, per-second metric data"
|
||||
description: >-
|
||||
"Learn how to get the most out of Netdata's charts. These charts will help you make sense of all the
|
||||
metrics at your disposal, helping you troubleshoot with real-time, per-second metric data"
|
||||
type: "how-to"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md"
|
||||
sidebar_label: "Interact with charts"
|
||||
|
|
@ -10,65 +12,85 @@ learn_rel_path: "Operations/Visualizations"
|
|||
---
|
||||
|
||||
> ⚠️ This new version of charts is currently **only** available on Netdata Cloud. We didn't want to keep this valuable
|
||||
> feature from you, so after we get this into your hands on the Cloud, we will collect and implement your feedback. Together, we will be able to provide the best possible version of charts on the Netdata Agent dashboard, as quickly as possible.
|
||||
> feature from you, so after we get this into your hands on the Cloud, we will collect and implement your feedback.
|
||||
> Together, we will be able to provide the best possible version of charts on the Netdata Agent dashboard, as quickly as
|
||||
> possible.
|
||||
|
||||
Netdata excels in collecting, storing, and organizing metrics in out-of-the-box dashboards.
|
||||
To make sense of all the metrics, Netdata offers an enhanced version of charts that update every second.
|
||||
Netdata excels in collecting, storing, and organizing metrics in out-of-the-box dashboards.
|
||||
To make sense of all the metrics, Netdata offers an enhanced version of charts that update every second.
|
||||
|
||||
These charts provide a lot of useful information, so that you can:
|
||||
|
||||
- Enjoy the high-resolution, granular metrics collected by Netdata
|
||||
- Explore visualization with more options such as _line_, _stacked_ and _area_ types (other types like _bar_, _pie_ and _gauges_ are to be added shortly)
|
||||
- Examine all the metrics by hovering over them with your cursor
|
||||
- Use intuitive tooling and shortcuts to pan, zoom or highlight your charts
|
||||
- On highlight, ease access to [Metric Correlations](/docs/cloud/insights/metric-correlations) to see other metrics with similar patterns
|
||||
- Have the dimensions sorted based on name or value
|
||||
- View information about the chart, its plugin, context, and type
|
||||
- Get the chart status and possible errors. On top, reload functionality
|
||||
- Enjoy the high-resolution, granular metrics collected by Netdata
|
||||
- Explore visualization with more options such as _line_, _stacked_ and _area_ types (other types like _bar_, _pie_ and
|
||||
_gauges_ are to be added shortly)
|
||||
- Examine all the metrics by hovering over them with your cursor
|
||||
- Use intuitive tooling and shortcuts to pan, zoom or highlight your charts
|
||||
- On highlight, ease access
|
||||
to [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md) to
|
||||
see other metrics with similar patterns
|
||||
- Have the dimensions sorted based on name or value
|
||||
- View information about the chart, its plugin, context, and type
|
||||
- Get the chart status and possible errors. On top, reload functionality
|
||||
|
||||
These charts will available on [Overview tab](/docs/cloud/visualize/overview), Single Node view and on your [Custom Dashboards](/docs/cloud/visualize/dashboards).
|
||||
These charts will available
|
||||
on [Overview tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md), Single Node view and
|
||||
on your [Custom Dashboards](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md).
|
||||
|
||||
## Overview
|
||||
|
||||
Have a look at the can see the overall look and feel of the charts for both with a composite chart from the [Overview tab](/docs/cloud/visualize/overview) and a simple chart from the single node view:
|
||||
Have a look at the can see the overall look and feel of the charts for both with a composite chart from
|
||||
the [Overview tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md) and a simple chart
|
||||
from the single node view:
|
||||
|
||||

|
||||
|
||||
With a quick glance you have immediate information available at your disposal:
|
||||
|
||||
- Chart title and units
|
||||
- Action bars
|
||||
- Chart area
|
||||
- Legend with dimensions
|
||||
- Chart title and units
|
||||
- Action bars
|
||||
- Chart area
|
||||
- Legend with dimensions
|
||||
|
||||
## Play, Pause and Reset
|
||||
|
||||
Your charts are controlled using the available [Time controls](/docs/dashboard/visualization-date-and-time-controls#time-controls). Besides these, when interacting with the chart you can also activate these controls by:
|
||||
Your charts are controlled using the
|
||||
available [Time controls](https://github.com/netdata/netdata/blob/master/docs/dashboard/visualization-date-and-time-controls.mdx#time-controls).
|
||||
Besides these, when interacting with the chart you can also activate these controls by:
|
||||
|
||||
- hovering over any chart to temporarily pause it - this momentarily switches time control to Pause, so that you can hover over a specific timeframe. When moving out of the chart time control will go back to Play (if it was it's previous state)
|
||||
- clicking on the chart to lock it - this enables the Pause option on the time controls, to the current timeframe. This is if you want to jump to a different chart to look for possible correlations.
|
||||
- double clicking to release a previously locked chart - move the time control back to Play
|
||||
- hovering over any chart to temporarily pause it - this momentarily switches time control to Pause, so that you can
|
||||
hover over a specific timeframe. When moving out of the chart time control will go back to Play (if it was it's
|
||||
previous state)
|
||||
- clicking on the chart to lock it - this enables the Pause option on the time controls, to the current timeframe. This
|
||||
is if you want to jump to a different chart to look for possible correlations.
|
||||
- double clicking to release a previously locked chart - move the time control back to Play
|
||||
|
||||

|
||||

|
||||
|
||||
| Interaction | Keyboard/mouse | Touchpad/touchscreen | Time control |
|
||||
| :---------------- | :------------- | :------------------- | :-------------------- |
|
||||
|:------------------|:---------------|:---------------------|:----------------------|
|
||||
| **Pause** a chart | `hover` | `n/a` | Temporarily **Pause** |
|
||||
| **Stop** a chart | `click` | `tap` | **Pause** |
|
||||
| **Reset** a chart | `double click` | `n/a` | **Play** |
|
||||
|
||||
Note: These interactions are available when the default "Pan" action is used. Other actions are accessible via the [Exploration action bar](#exploration-action-bar).
|
||||
Note: These interactions are available when the default "Pan" action is used. Other actions are accessible via
|
||||
the [Exploration action bar](#exploration-action-bar).
|
||||
|
||||
## Title and chart action bar
|
||||
|
||||
When you start interacting with a chart, you'll notice valuable information on the top bar. You will see information from the chart title to a chart action bar.
|
||||
When you start interacting with a chart, you'll notice valuable information on the top bar. You will see information
|
||||
from the chart title to a chart action bar.
|
||||
|
||||
The elements that you can find on this top bar are:
|
||||
|
||||
- Netdata icon: this indicates that data is continuously being updated, this happens if [Time controls](/docs/dashboard/visualization-date-and-time-controls#time-controls) are in Play or Force Play mode
|
||||
- Chart status icon: indicates the status of the chart. Possible values are: Loading, Timeout, Error or No data
|
||||
- Chart title: on the chart title you can see the title together with the metric being displayed, as well as the unit of measurement
|
||||
- Chart action bar: here you'll have access to chart info, change chart types, enables fullscreen mode, and the ability to add the chart to a custom dashboard
|
||||
- Netdata icon: this indicates that data is continuously being updated, this happens
|
||||
if [Time controls](https://github.com/netdata/netdata/blob/master/docs/dashboard/visualization-date-and-time-controls.mdx#time-controls)
|
||||
are in Play or Force Play mode
|
||||
- Chart status icon: indicates the status of the chart. Possible values are: Loading, Timeout, Error or No data
|
||||
- Chart title: on the chart title you can see the title together with the metric being displayed, as well as the unit of
|
||||
measurement
|
||||
- Chart action bar: here you'll have access to chart info, change chart types, enables fullscreen mode, and the ability
|
||||
to add the chart to a custom dashboard
|
||||
|
||||

|
||||
|
||||
|
|
@ -76,48 +98,58 @@ The elements that you can find on this top bar are:
|
|||
|
||||
On this bar you have access to immediate actions over the chart, the available actions are:
|
||||
|
||||
- Chart info: you will be able to get more information relevant to the chart you are interacting with
|
||||
- Chart type: change the chart type from _line_, _stacked_ or _area_
|
||||
- Enter fullscreen mode: allows you expand the current chart to the full size of your screen
|
||||
- Add chart to dashboard: This allows you to add the chart to an existing custom dashboard or directly create a new one that includes the chart.
|
||||
- Chart info: you will be able to get more information relevant to the chart you are interacting with
|
||||
- Chart type: change the chart type from _line_, _stacked_ or _area_
|
||||
- Enter fullscreen mode: allows you expand the current chart to the full size of your screen
|
||||
- Add chart to dashboard: This allows you to add the chart to an existing custom dashboard or directly create a new one
|
||||
that includes the chart.
|
||||
|
||||
<img src="https://images.zenhubusercontent.com/60b4ebb03f4163193ec31819/65ac4fc8-3d8d-4617-8234-dbb9b31b4264" width="40%" height="40%" />
|
||||
|
||||
## Exploration action bar
|
||||
|
||||
When exploring the chart you will see a second action bar. This action bar is there to support you on this task. The available actions that you can see are:
|
||||
When exploring the chart you will see a second action bar. This action bar is there to support you on this task. The
|
||||
available actions that you can see are:
|
||||
|
||||
- Pan
|
||||
- Highlight
|
||||
- Horizontal and Vertical zooms
|
||||
- In-context zoom in and out
|
||||
- Pan
|
||||
- Highlight
|
||||
- Horizontal and Vertical zooms
|
||||
- In-context zoom in and out
|
||||
|
||||
<img src="https://images.zenhubusercontent.com/60b4ebb03f4163193ec31819/0417ad66-fcf6-42d5-9a24-e9392ec51f87" width="40%" height="40%" />
|
||||
|
||||
### Pan
|
||||
|
||||
Drag your mouse/finger to the right to pan backward through time, or drag to the left to pan forward in time. Think of it like pushing the current timeframe off the screen to see what came before or after.
|
||||
Drag your mouse/finger to the right to pan backward through time, or drag to the left to pan forward in time. Think of
|
||||
it like pushing the current timeframe off the screen to see what came before or after.
|
||||
|
||||
| Interaction | Keyboard | Mouse | Touchpad/touchscreen |
|
||||
| :---------- | :------- | :------------- | :------------------- |
|
||||
|:------------|:---------|:---------------|:---------------------|
|
||||
| **Pan** | `n/a` | `click + drag` | `touch drag` |
|
||||
|
||||
### Highlight
|
||||
|
||||
Selecting timeframes is useful when you see an interesting spike or change in a chart and want to investigate further, from looking at the same period of time on other charts/sections or triggering actions to help you troubleshoot with an in-context action bar to help you troubleshoot (currently only available on
|
||||
Single Node view). The available actions:
|
||||
Selecting timeframes is useful when you see an interesting spike or change in a chart and want to investigate further,
|
||||
from looking at the same period of time on other charts/sections or triggering actions to help you troubleshoot with an
|
||||
in-context action bar to help you troubleshoot (currently only available on
|
||||
Single Node view). The available actions:
|
||||
|
||||
- run [Metric Correlations](/docs/cloud/insights/metric-correlations)
|
||||
- zoom in on the selected timeframe
|
||||
-
|
||||
|
||||
[Metric Correlations](/docs/cloud/insights/metric-correlations) will only be available if you respect the timeframe selection limitations. The selected duration pill together with the button state helps visualize this.
|
||||
run [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md)
|
||||
|
||||
- zoom in on the selected timeframe
|
||||
|
||||
[Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md)
|
||||
will only be available if you respect the timeframe selection limitations. The selected duration pill together with the
|
||||
button state helps visualize this.
|
||||
|
||||
<img src="https://images.zenhubusercontent.com/60b4ebb03f4163193ec31819/2ffc157d-0f0f-402e-80bb-5ffa8a2091d5" width="50%" height="50%" />
|
||||
|
||||
<p/>
|
||||
|
||||
| Interaction | Keyboard/mouse | Touchpad/touchscreen |
|
||||
| :--------------------------------- | :------------------------------------------------------- | :------------------- |
|
||||
|:-----------------------------------|:---------------------------------------------------------|:---------------------|
|
||||
| **Highlight** a specific timeframe | `Alt + mouse selection` or `⌘ + mouse selection` (macOS) | `n/a` |
|
||||
|
||||
### Zoom
|
||||
|
|
@ -127,13 +159,14 @@ of an anomaly or outage. Zooming out lets you see metrics within the larger cont
|
|||
week, which is useful in understanding what "normal" looks like, or to identify long-term trends, like a slow creep in
|
||||
memory usage.
|
||||
|
||||
The actions above are _normal_ vertical zoom actions. We also provide an horizontal zoom action that helps you focus on a
|
||||
The actions above are _normal_ vertical zoom actions. We also provide an horizontal zoom action that helps you focus on
|
||||
a
|
||||
specific Y-axis area to further investigate a spike or dive on your charts.
|
||||
|
||||

|
||||
|
||||
| Interaction | Keyboard/mouse | Touchpad/touchscreen |
|
||||
| :----------------------------------------- | :----------------------------------- | :--------------------------------------------------- |
|
||||
|:-------------------------------------------|:-------------------------------------|:-----------------------------------------------------|
|
||||
| **Zoom** in or out | `Shift + mouse scrollwheel` | `two-finger pinch` <br />`Shift + two-finger scroll` |
|
||||
| **Zoom** to a specific timeframe | `Shift + mouse vertical selection` | `n/a` |
|
||||
| **Horizontal Zoom** a specific Y-axis area | `Shift + mouse horizontal selection` | `n/a` |
|
||||
|
|
@ -146,8 +179,8 @@ You also have two direct action buttons on the exploration action bar for in-con
|
|||
|
||||
The bottom legend of the chart where you can see the dimensions of the chart can now be ordered by:
|
||||
|
||||
- Dimension name (Ascending or Descending)
|
||||
- Dimension value (Ascending or Descending)
|
||||
- Dimension name (Ascending or Descending)
|
||||
- Dimension value (Ascending or Descending)
|
||||
|
||||
<img src="https://images.zenhubusercontent.com/60b4ebb03f4163193ec31819/d3031c35-37bc-46c1-bcf9-be29dea0b476" width="50%" height="50%" />
|
||||
|
||||
|
|
@ -157,29 +190,33 @@ Hiding dimensions simplifies the chart and can help you better discover exactly
|
|||
behaving strangely.
|
||||
|
||||
| Interaction | Keyboard/mouse | Touchpad/touchscreen |
|
||||
| :------------------------------------- | :-------------- | :------------------- |
|
||||
|:---------------------------------------|:----------------|:---------------------|
|
||||
| **Show one** dimension and hide others | `click` | `tap` |
|
||||
| **Toggle (show/hide)** one dimension | `Shift + click` | `n/a` |
|
||||
|
||||
### Resize
|
||||
|
||||
To resize the chart, click-and-drag the icon on the bottom-right corner of any chart. To restore the chart to its original height,
|
||||
To resize the chart, click-and-drag the icon on the bottom-right corner of any chart. To restore the chart to its
|
||||
original height,
|
||||
double-click the same icon.
|
||||
|
||||

|
||||
|
||||
## What's next?
|
||||
|
||||
We recommend you read up on the differences between [chart dimensions, contexts, and
|
||||
families](/docs/dashboard/dimensions-contexts-families) to strengthen your understanding of how Netdata organizes its
|
||||
dashboards. Another valuable way to interact with charts is to use the [date and time controls](/docs/dashboard/visualization-date-and-time-controls), which helps you visualize specific moments of historical metrics.
|
||||
We recommend you read up on the differences
|
||||
between [chart dimensions, contexts, and families](https://github.com/netdata/netdata/blob/master/docs/dashboard/dimensions-contexts-families.mdx)
|
||||
to strengthen your understanding of how Netdata organizes its dashboards. Another valuable way to interact with charts
|
||||
is to use
|
||||
the [date and time controls](https://github.com/netdata/netdata/blob/master/docs/dashboard/visualization-date-and-time-controls.mdx),
|
||||
which helps you visualize specific moments of historical metrics.
|
||||
|
||||
### Further reading & related information
|
||||
|
||||
- Dashboard
|
||||
- [How the dashboard works](/docs/dashboard/how-dashboard-works)
|
||||
- [Chart dimensions, contexts, and families](/docs/dashboard/dimensions-contexts-families)
|
||||
- [Date and Time controls](/docs/dashboard/visualization-date-and-time-controls)
|
||||
- [Customize the standard dashboard](/docs/dashboard/customize)
|
||||
- [Metric Correlations](/docs/cloud/insights/metric-correlations)
|
||||
- [Netdata Agent - Interact with charts](/docs/dashboard/interact-charts)
|
||||
- Dashboard
|
||||
- [How the dashboard works](https://github.com/netdata/netdata/blob/master/docs/dashboard/how-dashboard-works.mdx)
|
||||
- [Chart dimensions, contexts, and families](https://github.com/netdata/netdata/blob/master/docs/dashboard/dimensions-contexts-families.mdx)
|
||||
- [Date and Time controls](https://github.com/netdata/netdata/blob/master/docs/dashboard/visualization-date-and-time-controls.mdx)
|
||||
- [Customize the standard dashboard](https://github.com/netdata/netdata/blob/master/docs/dashboard/customize.mdx)
|
||||
- [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md)
|
||||
- [Netdata Agent - Interact with charts](https://github.com/netdata/netdata/blob/master/docs/dashboard/interact-charts.mdx)
|
||||
|
|
|
|||
|
|
@ -19,12 +19,12 @@ single row, first featuring that node's alarm status (yellow for warnings, red f
|
|||
system, some essential information about the node, followed by columns of user-defined key metrics represented in
|
||||
real-time charts.
|
||||
|
||||
Use the [Overview](/docs/cloud/visualize/overview) for monitoring an infrastructure in real time using
|
||||
Use the [Overview](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md) for monitoring an infrastructure in real time using
|
||||
composite charts and Netdata's familiar dashboard UI.
|
||||
|
||||
Check the [War Room docs](/docs/cloud/war-rooms) for details on the utility bar, which contains the [node
|
||||
filter](/docs/cloud/war-rooms#node-filter) and the [timeframe
|
||||
selector](/docs/cloud/war-rooms#play-pause-force-play-and-timeframe-selector).
|
||||
Check the [War Room docs](https://github.com/netdata/netdata/blob/master/docs/cloud/war-rooms.md) for details on the utility bar, which contains the [node
|
||||
filter](https://github.com/netdata/netdata/blob/master/docs/cloud/war-rooms.md#node-filter) and the [timeframe
|
||||
selector](https://github.com/netdata/netdata/blob/master/docs/cloud/war-rooms.md#play-pause-force-play-and-timeframe-selector).
|
||||
|
||||
## Add and customize metrics columns
|
||||
|
||||
|
|
@ -39,15 +39,15 @@ These customizations appear for anyone else with access to that War Room.
|
|||
## See more metrics in Netdata Cloud
|
||||
|
||||
If you want to add more metrics to your War Rooms and they don't show up when you add new metrics to Nodes, you likely
|
||||
need to configure those nodes to collect from additional data sources. See our [collectors doc](/docs/collect/enable-configure)
|
||||
need to configure those nodes to collect from additional data sources. See our [collectors doc](https://github.com/netdata/netdata/blob/master/docs/collect/enable-configure.md)
|
||||
to learn how to use dozens of pre-installed collectors that can instantly collect from your favorite services and applications.
|
||||
|
||||
If you want to see up to 30 days of historical metrics in Cloud (and more on individual node dashboards), read our guide
|
||||
on [long-term storage of historical metrics](/guides/longer-metrics-storage). Also, see our
|
||||
on [long-term storage of historical metrics](https://github.com/netdata/netdata/blob/master/docs/guides/longer-metrics-storage.md). Also, see our
|
||||
[calculator](/docs/store/change-metrics-storage#calculate-the-system-resources-RAM-disk-space-needed-to-store-metrics)
|
||||
for finding the disk and RAM you need to store metrics for a certain period of time.
|
||||
|
||||
## What's next?
|
||||
|
||||
Now that you know how to view your nodes at a glance, learn how to [track active
|
||||
alarms](/docs/cloud/alerts-notifications/view-active-alerts) with the Alerts Smartboard.
|
||||
alarms](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/view-active-alerts.mdx) with the Alerts Smartboard.
|
||||
|
|
|
|||
|
|
@ -1,6 +1,8 @@
|
|||
---
|
||||
title: "Home, Overview and Single Node view"
|
||||
description: "The Home tab automatically presents relevant information of your War Room, the Overview uses composite charts from all the nodes in a given War Room and Single Node view provides a look at a specific Node"
|
||||
description: >-
|
||||
"The Home tab automatically presents relevant information of your War Room, the Overview uses composite
|
||||
charts from all the nodes in a given War Room and Single Node view provides a look at a specific Node"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md"
|
||||
sidebar_label: "Home, Overview and Single Node view"
|
||||
learn_status: "Published"
|
||||
|
|
@ -12,13 +14,14 @@ learn_rel_path: "Operations/Visualizations"
|
|||
|
||||
The Home tab provides a predefined dashboard of relevant information about entities in the War Room.
|
||||
|
||||
This tab will
|
||||
automatically present summarized information in an easily digestible display. You can see information about your
|
||||
This tab will
|
||||
automatically present summarized information in an easily digestible display. You can see information about your
|
||||
nodes, data collection and retention stats, alerts, users and dashboards.
|
||||
|
||||
## Overview
|
||||
|
||||
The Overview tab is another great way to monitor infrastructure using Netdata Cloud. While the interface might look similar to local
|
||||
The Overview tab is another great way to monitor infrastructure using Netdata Cloud. While the interface might look
|
||||
similar to local
|
||||
dashboards served by an Agent Overview uses **composite charts**.
|
||||
These charts display real-time aggregated metrics from all the nodes (or a filtered selection) in a given War Room.
|
||||
|
||||
|
|
@ -27,12 +30,16 @@ anomalies, then drill down by grouping metrics by node and jumping to single-nod
|
|||
|
||||
## Single Node view
|
||||
|
||||
The Single Node view dashboard engine is the same as the Overview, meaning that it also uses **composite charts**, and displays real-time aggregated metrics from a specific node.
|
||||
The Single Node view dashboard engine is the same as the Overview, meaning that it also uses **composite charts**, and
|
||||
displays real-time aggregated metrics from a specific node.
|
||||
|
||||
As mentioned above, the interface is similar to local dashboards served by an Agent but this dashboard also uses **composite charts** which, in the case of a single node, will aggregate
|
||||
multiple chart _instances_ belonging to a context into a single chart. For example, on `disk.io` context it will get into a single chart an aggregated view of each disk the node has.
|
||||
As mentioned above, the interface is similar to local dashboards served by an Agent but this dashboard also uses *
|
||||
*composite charts** which, in the case of a single node, will aggregate
|
||||
multiple chart _instances_ belonging to a context into a single chart. For example, on `disk.io` context it will get
|
||||
into a single chart an aggregated view of each disk the node has.
|
||||
|
||||
Further tools provided in composite chart [definiton bar](/docs/cloud/visualize/overview#definition-bar) will allow you to explore in more detail what is happening on each _instance_.
|
||||
Further tools provided in composite chart [definiton bar](/docs/cloud/visualize/overview#definition-bar) will allow you
|
||||
to explore in more detail what is happening on each _instance_.
|
||||
|
||||
## Before you get started
|
||||
|
||||
|
|
@ -40,7 +47,8 @@ Only nodes with v1.25.0-127 or later of the the [open-source Netdata](https://gi
|
|||
agent can contribute to composite charts. If your node(s) use an earlier version of Netdata, you will see them marked as
|
||||
**needs upgrade** in various dropdowns.
|
||||
|
||||
See our [update docs](/docs/agent/packaging/installer/update) for the preferred update method based on how you installed
|
||||
See our [update docs](https://github.com/netdata/netdata/blob/master/packaging/installer/UPDATE.md) for the preferred
|
||||
update method based on how you installed
|
||||
Netdata.
|
||||
|
||||
## Composite charts
|
||||
|
|
@ -51,52 +59,64 @@ Room.
|
|||
## Definition bar
|
||||
|
||||
Each composite chart has a definition bar to provide information about the following:
|
||||
|
||||
* Grouping option
|
||||
* Aggregate function to be applied in case multiple data sources exist
|
||||
* Instances
|
||||
* Nodes
|
||||
* Dimensions, and
|
||||
* Dimensions, and
|
||||
* Aggregate function over time to be applied if one point in the chart consists of multiple data points aggregated
|
||||
|
||||
### Group by dimension, node, or chart
|
||||
|
||||
Click on the **dimension** dropdown to change how a composite chart groups metrics.
|
||||
|
||||
The default option is by _dimension_, so that each line/area in the visualization is the aggregation of a single dimension.
|
||||
This provides a per dimension view of the data from all the nodes in the War Room, taking into account filtering criteria if defined.
|
||||
The default option is by _dimension_, so that each line/area in the visualization is the aggregation of a single
|
||||
dimension.
|
||||
This provides a per dimension view of the data from all the nodes in the War Room, taking into account filtering
|
||||
criteria if defined.
|
||||
|
||||
A composite chart grouped by _node_ visualizes a single metric across contributing nodes. If the composite chart has five
|
||||
contributing nodes, there will be five lines/areas. This is typically an absolute value of the sum of the dimensions over each node but there
|
||||
A composite chart grouped by _node_ visualizes a single metric across contributing nodes. If the composite chart has
|
||||
five
|
||||
contributing nodes, there will be five lines/areas. This is typically an absolute value of the sum of the dimensions
|
||||
over each node but there
|
||||
are some opinionated-but-valuable exceptions where a specific dimension is selected.
|
||||
Grouping by nodes allows you to quickly understand which nodes in your infrastructure are experiencing anomalous behavior.
|
||||
Grouping by nodes allows you to quickly understand which nodes in your infrastructure are experiencing anomalous
|
||||
behavior.
|
||||
|
||||
A composite chart grouped by _instance_ visualizes each instance of one software or hardware on a node and displays these as a separate dimension. By grouping the
|
||||
`disk.io` chart by _instance_, you can visualize the activity of each disk on each node that contributes to the composite
|
||||
A composite chart grouped by _instance_ visualizes each instance of one software or hardware on a node and displays
|
||||
these as a separate dimension. By grouping the
|
||||
`disk.io` chart by _instance_, you can visualize the activity of each disk on each node that contributes to the
|
||||
composite
|
||||
chart.
|
||||
|
||||
Another very pertinent example is composite charts over contexts related to cgroups (VMs and containers). You have the means to change the default group by or apply filtering to
|
||||
get a better view into what data your are trying to analyze. For example, if you change the group by to _instance_ you get a view with the data of all the instances (cgroups) that
|
||||
contribute to that chart. Then you can use further filtering tools to focus the data that is important to you and even save the result to your own dashboards.
|
||||
Another very pertinent example is composite charts over contexts related to cgroups (VMs and containers). You have the
|
||||
means to change the default group by or apply filtering to
|
||||
get a better view into what data your are trying to analyze. For example, if you change the group by to _instance_ you
|
||||
get a view with the data of all the instances (cgroups) that
|
||||
contribute to that chart. Then you can use further filtering tools to focus the data that is important to you and even
|
||||
save the result to your own dashboards.
|
||||
|
||||

|
||||
|
||||
### Aggregate functions over data sources
|
||||
|
||||
Each chart uses an opinionated-but-valuable default aggregate function over the data sources. For example, the `system.cpu` chart shows the
|
||||
Each chart uses an opinionated-but-valuable default aggregate function over the data sources. For example,
|
||||
the `system.cpu` chart shows the
|
||||
average for each dimension from every contributing chart, while the `net.net` chart shows the sum for each dimension
|
||||
from every contributing chart, which can also come from multiple networking interfaces.
|
||||
|
||||
The following aggregate functions are available for each selected dimension:
|
||||
|
||||
- **Average**: Displays the average value from contributing nodes. If a composite chart has 5 nodes with the following
|
||||
values for the `out` dimension—`-2.1`, `-5.5`, `-10.2`, `-15`, `-0.1`—the composite chart displays a
|
||||
value of `−6.58`.
|
||||
- **Sum**: Displays the sum of contributed values. Using the same nodes, dimension, and values as above, the composite
|
||||
chart displays a metric value of `-32.9`.
|
||||
- **Min**: Displays a minimum value. For dimensions with positive values, the min is the value closest to zero. For
|
||||
charts with negative values, the min is the value with the largest magnitude.
|
||||
- **Max**: Displays a maximum value. For dimensions with positive values, the max is the value with the largest
|
||||
magnitude. For charts with negative values, the max is the value closet to zero.
|
||||
- **Average**: Displays the average value from contributing nodes. If a composite chart has 5 nodes with the following
|
||||
values for the `out` dimension—`-2.1`, `-5.5`, `-10.2`, `-15`, `-0.1`—the composite chart displays a
|
||||
value of `−6.58`.
|
||||
- **Sum**: Displays the sum of contributed values. Using the same nodes, dimension, and values as above, the composite
|
||||
chart displays a metric value of `-32.9`.
|
||||
- **Min**: Displays a minimum value. For dimensions with positive values, the min is the value closest to zero. For
|
||||
charts with negative values, the min is the value with the largest magnitude.
|
||||
- **Max**: Displays a maximum value. For dimensions with positive values, the max is the value with the largest
|
||||
magnitude. For charts with negative values, the max is the value closet to zero.
|
||||
|
||||
### Dimensions
|
||||
|
||||
|
|
@ -105,13 +125,15 @@ number of dimensions available on that context.
|
|||
|
||||
### Instances
|
||||
|
||||
Click on **X Instances** to display a dropdown of instances and nodes contributing to that composite chart. Each line in the
|
||||
Click on **X Instances** to display a dropdown of instances and nodes contributing to that composite chart. Each line in
|
||||
the
|
||||
dropdown displays an instance name and the associated node's hostname.
|
||||
|
||||
### Nodes
|
||||
|
||||
Click on **X Nodes** to display a dropdown of nodes contributing to that composite chart. Each line displays a hostname
|
||||
to help you identify which nodes contribute to a chart. You can also use this component to filter nodes directly on the chart.
|
||||
to help you identify which nodes contribute to a chart. You can also use this component to filter nodes directly on the
|
||||
chart.
|
||||
|
||||
If one or more nodes can't contribute to a given chart, the definition bar shows a warning symbol plus the number of
|
||||
affected nodes, then lists them in the dropdown along with the associated error. Nodes might return errors because of
|
||||
|
|
@ -119,8 +141,10 @@ networking issues, a stopped `netdata` service, or because that node does not ha
|
|||
|
||||
### Aggregate functions over time
|
||||
|
||||
When the granularity of the data collected is higher than the plotted points on the chart an aggregation function over time
|
||||
is applied. By default the aggregation applied is _average_ but the user can choose different options from the following:
|
||||
When the granularity of the data collected is higher than the plotted points on the chart an aggregation function over
|
||||
time
|
||||
is applied. By default the aggregation applied is _average_ but the user can choose different options from the
|
||||
following:
|
||||
|
||||
* Min
|
||||
* Max
|
||||
|
|
@ -138,13 +162,15 @@ is applied. By default the aggregation applied is _average_ but the user can cho
|
|||
|
||||
:::info
|
||||
|
||||
- `*` For **Trimmed Median and Mean** you can choose the percentage of data tha you want to focus on: 1%, 2%, 3%, 5%, 10%, 15%, 20% and 25%.
|
||||
- `**` For **Percentile** you can specify the percentile you want to focus on: 25th, 50th, 75th, 80th, 90th, 95th, 97th, 98th and 99th.
|
||||
- `*` For **Trimmed Median and Mean** you can choose the percentage of data tha you want to focus on: 1%, 2%, 3%, 5%,
|
||||
10%, 15%, 20% and 25%.
|
||||
- `**` For **Percentile** you can specify the percentile you want to focus on: 25th, 50th, 75th, 80th, 90th, 95th, 97th,
|
||||
98th and 99th.
|
||||
|
||||
:::
|
||||
|
||||
|
||||
For more details on each, you can refer to our Agent's HTTP API details on [Data Queries - Data Grouping](/docs/agent/web/api/queries#data-grouping).
|
||||
For more details on each, you can refer to our Agent's HTTP API details
|
||||
on [Data Queries - Data Grouping](/docs/agent/web/api/queries#data-grouping).
|
||||
|
||||
### Reset to defaults
|
||||
|
||||
|
|
@ -164,7 +190,8 @@ src="https://user-images.githubusercontent.com/1153921/95762109-1d219300-0c62-11
|
|||
node you're interested in.
|
||||
|
||||
The single-node dashboard opens in a new tab. From there, you can continue to troubleshoot or run [Metric
|
||||
Correlations](/docs/cloud/insights/metric-correlations) for faster root cause analysis.
|
||||
Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md) for faster root
|
||||
cause analysis.
|
||||
|
||||
## Add composite charts to a dashboard
|
||||
|
||||
|
|
@ -175,8 +202,9 @@ entering the name and clicking **New Dashboard**.
|
|||
## Interacting with composite charts: pan, zoom, and resize
|
||||
|
||||
You can interact with composite charts as you would with other Netdata charts. You can use the controls beneath each
|
||||
chart to pan, zoom, or resize the chart, or use various combinations of the keyboard and mouse. See the [chart
|
||||
interaction doc](/docs/dashboard/interact-charts) for details.
|
||||
chart to pan, zoom, or resize the chart, or use various combinations of the keyboard and mouse. See
|
||||
the [chart interaction doc](https://github.com/netdata/netdata/blob/master/docs/dashboard/interact-charts.mdx) for
|
||||
details.
|
||||
|
||||
## Menu
|
||||
|
||||
|
|
@ -191,7 +219,8 @@ One difference between the Overview's menu and those found in single-node dashbo
|
|||
the Overview condenses multiple services, families, or instances into single sections, sub-menus, and associated charts.
|
||||
|
||||
For services, let's say you have two concurrent jobs with the [web_log
|
||||
collector](/docs/agent/collectors/go.d.plugin/modules/weblog), one for Apache and another for Nginx. A single-node or
|
||||
collector](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md), one for Apache and another for
|
||||
Nginx. A single-node or
|
||||
local dashboard shows two section, **web_log apache** and **web_log nginx**, whereas the Overview condenses these into a
|
||||
single **web_log** section containing composite charts from both jobs.
|
||||
|
||||
|
|
@ -201,7 +230,7 @@ chart. The utility bar should show that there are 8 charts from 2 nodes contribu
|
|||
|
||||
This action applies to disks, network devices, and other metric types that involve multiple instances of a piece of
|
||||
hardware or software. The Overview currently does not display metrics from filesystems. Read more about [families and
|
||||
instances](/docs/dashboard/dimensions-contexts-families)
|
||||
instances](https://github.com/netdata/netdata/blob/master/docs/dashboard/dimensions-contexts-families.mdx)
|
||||
|
||||
## Persistence of composite chart settings
|
||||
|
||||
|
|
@ -211,10 +240,11 @@ colleagues by having them copy-paste it into their browser.
|
|||
|
||||
## What's next?
|
||||
|
||||
For another way to view an infrastructure from a high level, see the [Nodes view](/docs/cloud/visualize/nodes).
|
||||
For another way to view an infrastructure from a high level, see
|
||||
the [Nodes view](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/nodes.md).
|
||||
|
||||
If you need a refresher on how Netdata's charts work, see our doc on [interacting with
|
||||
charts](/docs/dashboard/interact-charts).
|
||||
If you need a refresher on how Netdata's charts work, see our doc
|
||||
on [interacting with charts](https://github.com/netdata/netdata/blob/master/docs/dashboard/interact-charts.mdx).
|
||||
|
||||
Or, get more granular with configuring how you monitor your infrastructure by [building new
|
||||
dashboards](/docs/cloud/visualize/dashboards).
|
||||
Or, get more granular with configuring how you monitor your infrastructure
|
||||
by [building new dashboards](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md).
|
||||
|
|
|
|||
|
|
@ -1,6 +1,8 @@
|
|||
---
|
||||
title: "War Rooms"
|
||||
description: " Netdata Cloud uses War Rooms to group related nodes and create insightful compositedashboards based on their aggregate health and performance."
|
||||
description: >-
|
||||
"Netdata Cloud uses War Rooms to group related nodes and create insightful compositedashboards based on
|
||||
their aggregate health and performance."
|
||||
custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/cloud/war-rooms.md"
|
||||
sidebar_label: "War Rooms"
|
||||
learn_status: "Published"
|
||||
|
|
@ -24,30 +26,41 @@ your nodes into more War Rooms. Every War Room has its own dashboards, navigatio
|
|||
Every War Rooms provides multiple views. Each view focus on a particular area/subject of the nodes which you monitor in
|
||||
this War Rooms. Let's explore what view you have available:
|
||||
|
||||
- The default view for any War Room is the [Home tab](/docs/cloud/visualize/overview#home), which give you an overview
|
||||
- The default view for any War Room is
|
||||
the [Home tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md#home), which give you
|
||||
an overview
|
||||
of this space. Here you can see the number of Nodes claimed, data retention statics, user particate, alerts and more
|
||||
|
||||
- The second and most important view is the [Overview tab](/docs/cloud/visualize/overview#overview) which uses composite
|
||||
- The second and most important view is
|
||||
the [Overview tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md#overview) which
|
||||
uses composite
|
||||
charts to display real-time metrics from every available node in a given War Room.
|
||||
|
||||
- The [Nodes tab](/docs/cloud/visualize/nodes) gives you the ability to see the status (offline or online), host details
|
||||
- The [Nodes tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/nodes.md) gives you the ability to
|
||||
see the status (offline or online), host details
|
||||
, alarm status and also a short overview of some key metrics from all your nodes at a glance.
|
||||
|
||||
- [Kubernetes tab](/docs/cloud/visualize/kubernetes) is a logical grouping of charts regards to your Kubernetes clusters.
|
||||
- [Kubernetes tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/kubernetes.md) is a logical
|
||||
grouping of charts regards to your Kubernetes clusters.
|
||||
It contains a subset of the charts available in the _Overview tab_
|
||||
|
||||
- The [Dashboards tab](/docs/cloud/visualize/dashboards) gives you the ability to have tailored made views of
|
||||
specific/targeted interfaces for your infrastructure using any number of charts from any number of nodes.
|
||||
-
|
||||
|
||||
The [Dashboards tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md)
|
||||
gives you the ability to have tailored made views of
|
||||
specific/targeted interfaces for your infrastructure using any number of charts from any number of nodes.
|
||||
|
||||
- The **Alerts tab** provides you with an overview for all the active alerts you receive for the nodes in this War Room,
|
||||
you can also see alla the alerts that are configured to be triggered in any given moment.
|
||||
|
||||
- The **Anomalies tab** is dedicated to the [Anomaly Advisor](/docs/cloud/insights/anomaly-advisor) tool
|
||||
- The **Anomalies tab** is dedicated to
|
||||
the [Anomaly Advisor](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.mdx) tool
|
||||
|
||||
### Non static tabs
|
||||
|
||||
If you open a [new dashboard](/docs/cloud/visualize/dashboards), jump to a single-node dashboard, or navigate to a dedicated
|
||||
alert page they will open in a new War Room tab.
|
||||
If you open
|
||||
a [new dashboard](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md),
|
||||
jump to a single-node dashboard, or navigate to a dedicated alert page they will open in a new War Room tab.
|
||||
|
||||
Tabs can be rearranged with drag-and-drop or closed with the **X** button. Open tabs persist between sessions, so you
|
||||
can always come right back to your preferred setup.
|
||||
|
|
@ -55,7 +68,9 @@ can always come right back to your preferred setup.
|
|||
### Play, pause, force play, and timeframe selector
|
||||
|
||||
A War Room has three different states: playing, paused, and force playing. The default playing state refreshes charts
|
||||
every second as long as the browser tab is in focus. [Interacting with a chart](/docs/dashboard/interact-charts) pauses
|
||||
every second as long as the browser tab is in
|
||||
focus. [Interacting with a chart](https://github.com/netdata/netdata/blob/master/docs/dashboard/interact-charts.mdx)
|
||||
pauses
|
||||
the War Room. Once the tab loses focus, charts pause automatically.
|
||||
|
||||
The top navigation bar features a play/pause button to quickly change the state, and a dropdown to select **Force Play**
|
||||
|
|
@ -72,7 +87,6 @@ node. Click **Clear** to remove any changes and apply the default 15-minute time
|
|||
|
||||
The fields beneath the calendar display the beginning and ending timestamps your selected timeframe.
|
||||
|
||||
|
||||
### Node filter
|
||||
|
||||
The node filter allows you to quickly filter the nodes visualized in a War Room's views. It appears on all views, but
|
||||
|
|
@ -80,7 +94,6 @@ not on single-node dashboards.
|
|||
|
||||
|
||||
|
||||
|
||||
## War Room organization
|
||||
|
||||
We recommend a few strategies for organizing your War Rooms.
|
||||
|
|
@ -97,10 +110,10 @@ health and performance of your organization's essential services.
|
|||
|
||||
**Incident response**: You can also create new War Rooms as one of the first steps in your incident response process.
|
||||
For example, you have a user-facing web app that relies on Apache Pulsar for a message queue, and one of your nodes
|
||||
using the [Pulsar collector](/docs/agent/collectors/go.d.plugin/modules/pulsar) begins reporting a suspiciously low
|
||||
messages rate. You can create a War Room called `$year-$month-$day-pulsar-rate`, add all your Pulsar nodes in addition
|
||||
to nodes they connect to, and begin diagnosing the root cause in a War Room optimized for getting to resolution as fast
|
||||
as possible.
|
||||
using the [Pulsar collector](https://github.com/netdata/go.d.plugin/blob/master/modules/pulsar/README.md) begins
|
||||
reporting a suspiciously low messages rate. You can create a War Room called `$year-$month-$day-pulsar-rate`, add all
|
||||
your Pulsar nodes in addition to nodes they connect to, and begin diagnosing the root cause in a War Room optimized for
|
||||
getting to resolution as fast as possible.
|
||||
|
||||
## Add War Rooms
|
||||
|
||||
|
|
@ -114,34 +127,36 @@ can join public War Rooms, but can only join private War Rooms with an invitatio
|
|||
|
||||
All the users and nodes involved in a particular space can potential be part of a War Room.
|
||||
|
||||
Any user can change simple settings of a War room, like the name or the users participating in it. Click on the gear
|
||||
Any user can change simple settings of a War room, like the name or the users participating in it. Click on the gear
|
||||
icon of the War Room's name in the top of the page to do that. A sidebar will open with options for this War Room:
|
||||
|
||||
1. To _change a War Room's name, description, or public/private status_, click on **War Room** tab of the sidebar.
|
||||
|
||||
2. To _include an existing node_ to a War Room or _connect a new node*_ click on **Nodes** tab of the sidebar. Choose any
|
||||
connected node you want to add to this War Room by clicking on the checkbox next to its hostname, then click **+ Add**
|
||||
at the top of the panel.
|
||||
2. To _include an existing node_ to a War Room or _connect a new node*_ click on **Nodes** tab of the sidebar. Choose
|
||||
any
|
||||
connected node you want to add to this War Room by clicking on the checkbox next to its hostname, then click **+ Add
|
||||
**
|
||||
at the top of the panel.
|
||||
|
||||
3. To _add existing users to a War Room_, click on **Add Users**. See our [invite doc](/docs/cloud/manage/invite-your-team)
|
||||
for details on inviting new users to your Space in Netdata Cloud.
|
||||
3. To _add existing users to a War Room_, click on **Add Users**. See
|
||||
our [invite doc](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/invite-your-team.md)
|
||||
for details on inviting new users to your Space in Netdata Cloud.
|
||||
|
||||
:::note
|
||||
\* This action requires admin rights for this space
|
||||
\* This action requires admin rights for this space
|
||||
:::
|
||||
|
||||
### More actions
|
||||
|
||||
To _view or remove nodes_ in a War Room, click on **Nodes view**. To remove a node from the current War Room, click on
|
||||
the **🗑** icon.
|
||||
the **🗑** icon.
|
||||
|
||||
:::info
|
||||
Removing a node from a War Room does not remove it from your Space.
|
||||
Removing a node from a War Room does not remove it from your Space.
|
||||
:::
|
||||
|
||||
|
||||
|
||||
## What's next?
|
||||
|
||||
Once you've figured out an organizational structure that works for your team, learn more about how you can use Netdata
|
||||
Cloud to monitor distributed nodes using [real-time composite charts](/docs/cloud/visualize/overview).
|
||||
Cloud to monitor distributed nodes
|
||||
using [real-time composite charts](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md).
|
||||
|
|
|
|||
|
|
@ -15,7 +15,7 @@ web servers, databases, message brokers, email servers, search platforms, and mu
|
|||
pre-installed with every Netdata Agent and usually require zero configuration. Netdata also collects and visualizes
|
||||
resource utilization per application on Linux systems using `apps.plugin`.
|
||||
|
||||
[**apps.plugin**](/collectors/apps.plugin/README.md) looks at the Linux process tree every second, much like `top` or
|
||||
[**apps.plugin**](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md) looks at the Linux process tree every second, much like `top` or
|
||||
`ps fax`, and collects resource utilization information on every running process. By reading the process tree, Netdata
|
||||
shows CPU, disk, networking, processes, and eBPF for every application or Linux user. Unlike `top` or `ps fax`, Netdata
|
||||
adds a layer of meaningful visualization on top of the process tree metrics, such as grouping applications into useful
|
||||
|
|
@ -24,43 +24,43 @@ charts under **Users**, and per-user group charts under **User Groups**.
|
|||
|
||||
Our most popular application collectors:
|
||||
|
||||
- [Prometheus endpoints](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/prometheus): Gathers
|
||||
- [Prometheus endpoints](https://github.com/netdata/go.d.plugin/blob/master/modules/prometheus/README.md): Gathers
|
||||
metrics from one or more Prometheus endpoints that use the OpenMetrics exposition format. Auto-detects more than 600
|
||||
endpoints.
|
||||
- [Web server logs (Apache, NGINX)](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/weblog/):
|
||||
- [Web server logs (Apache, NGINX)](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md):
|
||||
Tail access logs and provide very detailed web server performance statistics. This module is able to parse 200k+
|
||||
rows in less than half a second.
|
||||
- [MySQL](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/mysql/): Collect database global,
|
||||
- [MySQL](https://github.com/netdata/go.d.plugin/blob/master/modules/mysql/README.md): Collect database global,
|
||||
replication, and per-user statistics.
|
||||
- [Redis](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/redis): Monitor database status by
|
||||
- [Redis](https://github.com/netdata/go.d.plugin/blob/master/modules/redis/README.md): Monitor database status by
|
||||
reading the server's response to the `INFO` command.
|
||||
- [Apache](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/apache/): Collect Apache web server
|
||||
- [Apache](https://github.com/netdata/go.d.plugin/blob/master/modules/apache/README.md): Collect Apache web server
|
||||
performance metrics via the `server-status?auto` endpoint.
|
||||
- [Nginx](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/nginx/): Monitor web server status
|
||||
- [Nginx](https://github.com/netdata/go.d.plugin/blob/master/modules/nginx/README.md): Monitor web server status
|
||||
information by gathering metrics via `ngx_http_stub_status_module`.
|
||||
- [Postgres](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/postgres): Collect database health
|
||||
- [Postgres](https://github.com/netdata/go.d.plugin/blob/master/modules/postgres/README.md): Collect database health
|
||||
and performance metrics.
|
||||
- [ElasticSearch](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/elasticsearch): Collect search
|
||||
- [ElasticSearch](https://github.com/netdata/go.d.plugin/blob/master/modules/elasticsearch/README.md): Collect search
|
||||
engine performance and health statistics. Optionally collects per-index metrics.
|
||||
- [PHP-FPM](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/phpfpm/): Collect application summary
|
||||
- [PHP-FPM](https://github.com/netdata/go.d.plugin/blob/master/modules/phpfpm/README.md): Collect application summary
|
||||
and processes health metrics by scraping the status page (`/status?full`).
|
||||
|
||||
Our [supported collectors list](/collectors/COLLECTORS.md#service-and-application-collectors) shows all Netdata's
|
||||
Our [supported collectors list](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md#service-and-application-collectors) shows all Netdata's
|
||||
application metrics collectors, including those for containers/k8s clusters.
|
||||
|
||||
## Collect metrics from applications running on Windows
|
||||
|
||||
Netdata is fully capable of collecting and visualizing metrics from applications running on Windows systems. The only
|
||||
caveat is that you must [install Netdata](/docs/get-started.mdx) on a separate system or a compatible VM because there
|
||||
caveat is that you must [install Netdata](https://github.com/netdata/netdata/blob/master/docs/get-started.mdx) on a separate system or a compatible VM because there
|
||||
is no native Windows version of the Netdata Agent.
|
||||
|
||||
Once you have Netdata running on that separate system, you can follow the [enable and configure
|
||||
doc](/docs/collect/enable-configure.md) to tell the collector to look for exposed metrics on the Windows system's IP
|
||||
doc](https://github.com/netdata/netdata/blob/master/docs/collect/enable-configure.md) to tell the collector to look for exposed metrics on the Windows system's IP
|
||||
address or hostname, plus the applicable port.
|
||||
|
||||
For example, you have a MySQL database with a root password of `my-secret-pw` running on a Windows system with the IP
|
||||
address 203.0.113.0. you can configure the [MySQL
|
||||
collector](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/mysql) to look at `203.0.113.0:3306`:
|
||||
collector](https://github.com/netdata/go.d.plugin/blob/master/modules/mysql/README.md) to look at `203.0.113.0:3306`:
|
||||
|
||||
```yml
|
||||
jobs:
|
||||
|
|
@ -69,16 +69,16 @@ jobs:
|
|||
```
|
||||
|
||||
This same logic applies to any application in our [supported collectors
|
||||
list](/collectors/COLLECTORS.md#service-and-application-collectors) that can run on Windows.
|
||||
list](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md#service-and-application-collectors) that can run on Windows.
|
||||
|
||||
## What's next?
|
||||
|
||||
If you haven't yet seen the [supported collectors list](/collectors/COLLECTORS.md) give it a once-over for any
|
||||
If you haven't yet seen the [supported collectors list](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md) give it a once-over for any
|
||||
additional applications you may want to monitor using Netdata's native collectors, or the [generic Prometheus
|
||||
collector](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/prometheus).
|
||||
collector](https://github.com/netdata/go.d.plugin/blob/master/modules/prometheus/README.md).
|
||||
|
||||
Collecting all the available metrics on your nodes, and across your entire infrastructure, is just one piece of the
|
||||
puzzle. Next, learn more about Netdata's famous real-time visualizations by [seeing an overview of your
|
||||
infrastructure](/docs/visualize/overview-infrastructure.md) using Netdata Cloud.
|
||||
infrastructure](https://github.com/netdata/netdata/blob/master/docs/visualize/overview-infrastructure.md) using Netdata Cloud.
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -13,35 +13,35 @@ learn_rel_path: "Concepts"
|
|||
Thanks to close integration with Linux cgroups and the virtual files it maintains under `/sys/fs/cgroup`, Netdata can
|
||||
monitor the health, status, and resource utilization of many different types of Linux containers.
|
||||
|
||||
Netdata uses [cgroups.plugin](/collectors/cgroups.plugin/README.md) to poll `/sys/fs/cgroup` and convert the raw data
|
||||
Netdata uses [cgroups.plugin](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md) to poll `/sys/fs/cgroup` and convert the raw data
|
||||
into human-readable metrics and meaningful visualizations. Through cgroups, Netdata is compatible with **all Linux
|
||||
containers**, such as Docker, LXC, LXD, Libvirt, systemd-nspawn, and more. Read more about [Docker-specific
|
||||
monitoring](#collect-docker-metrics) below.
|
||||
|
||||
Netdata also has robust **Kubernetes monitoring** support thanks to a
|
||||
[Helmchart](/packaging/installer/methods/kubernetes.md) to automate deployment, collectors for k8s agent services, and
|
||||
[Helmchart](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/kubernetes.md) to automate deployment, collectors for k8s agent services, and
|
||||
robust [service discovery](https://github.com/netdata/agent-service-discovery/#service-discovery) to monitor the
|
||||
services running inside of pods in your k8s cluster. Read more about [Kubernetes
|
||||
monitoring](#collect-kubernetes-metrics) below.
|
||||
|
||||
A handful of additional collectors gather metrics from container-related services, such as
|
||||
[dockerd](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/docker/) or [Docker
|
||||
Engine](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/docker_engine/). You can find all
|
||||
[dockerd](https://github.com/netdata/go.d.plugin/blob/master/modules/docker/README.md) or [Docker
|
||||
Engine](https://github.com/netdata/go.d.plugin/blob/master/modules/docker_engine/README.md). You can find all
|
||||
container collectors in our supported collectors list under the
|
||||
[containers/VMs](/collectors/COLLECTORS.md#containers-and-vms) and
|
||||
[Kubernetes](/collectors/COLLECTORS.md#containers-and-vms) headings.
|
||||
[containers/VMs](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md#containers-and-vms) and
|
||||
[Kubernetes](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md#containers-and-vms) headings.
|
||||
|
||||
## Collect Docker metrics
|
||||
|
||||
Netdata has robust Docker monitoring thanks to the aforementioned
|
||||
[cgroups.plugin](/collectors/cgroups.plugin/README.md). By polling cgroups every second, Netdata can produce meaningful
|
||||
[cgroups.plugin](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md). By polling cgroups every second, Netdata can produce meaningful
|
||||
visualizations about the CPU, memory, disk, and network utilization of all running containers on the host system with
|
||||
zero configuration.
|
||||
|
||||
Netdata also collects metrics from applications running inside of Docker containers. For example, if you create a MySQL
|
||||
database container using `docker run --name some-mysql -e MYSQL_ROOT_PASSWORD=my-secret-pw -d mysql:tag`, it exposes
|
||||
metrics on port 3306. You can configure the [MySQL
|
||||
collector](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/mysql) to look at `127.0.0.0:3306` for
|
||||
collector](https://github.com/netdata/go.d.plugin/blob/master/modules/mysql/README.md) to look at `127.0.0.0:3306` for
|
||||
MySQL metrics:
|
||||
|
||||
```yml
|
||||
|
|
@ -51,18 +51,18 @@ jobs:
|
|||
```
|
||||
|
||||
Netdata then collects metrics from the container itself, but also dozens [MySQL-specific
|
||||
metrics](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/mysql#charts) as well.
|
||||
metrics](https://github.com/netdata/go.d.plugin/blob/master/modules/mysql/README.md#charts) as well.
|
||||
|
||||
### Collect metrics from applications running in Docker containers
|
||||
|
||||
You could use this technique to monitor an entire infrastructure of Docker containers. The same [enable and
|
||||
configure](/docs/collect/enable-configure.md) procedures apply whether an application runs on the host system or inside
|
||||
configure](https://github.com/netdata/netdata/blob/master/docs/collect/enable-configure.md) procedures apply whether an application runs on the host system or inside
|
||||
a container. You may need to configure the target endpoint if it's not the application's default.
|
||||
|
||||
Netdata can even [run in a Docker container](/packaging/docker/README.md) itself, and then collect metrics about the
|
||||
Netdata can even [run in a Docker container](https://github.com/netdata/netdata/blob/master/packaging/docker/README.md) itself, and then collect metrics about the
|
||||
host system, its own container with cgroups, and any applications you want to monitor.
|
||||
|
||||
See our [application metrics doc](/docs/collect/application-metrics.md) for details about Netdata's application metrics
|
||||
See our [application metrics doc](https://github.com/netdata/netdata/blob/master/docs/collect/application-metrics.md) for details about Netdata's application metrics
|
||||
collection capabilities.
|
||||
|
||||
## Collect Kubernetes metrics
|
||||
|
|
@ -77,26 +77,26 @@ your k8s infrastructure.
|
|||
configuration files for [compatible
|
||||
applications](https://github.com/netdata/helmchart#service-discovery-and-supported-services) and any endpoints
|
||||
covered by our [generic Prometheus
|
||||
collector](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/prometheus). With these
|
||||
collector](https://github.com/netdata/go.d.plugin/blob/master/modules/prometheus/README.md). With these
|
||||
configuration files, Netdata collects metrics from any compatible applications as they run _inside_ of a pod.
|
||||
Service discovery happens without manual intervention as pods are created, destroyed, or moved between nodes.
|
||||
- A [Kubelet collector](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/k8s_kubelet), which runs
|
||||
- A [Kubelet collector](https://github.com/netdata/go.d.plugin/blob/master/modules/k8s_kubelet/README.md), which runs
|
||||
on each node in a k8s cluster to monitor the number of pods/containers, the volume of operations on each container,
|
||||
and more.
|
||||
- A [kube-proxy collector](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/k8s_kubeproxy), which
|
||||
- A [kube-proxy collector](https://github.com/netdata/go.d.plugin/blob/master/modules/k8s_kubeproxy/README.md), which
|
||||
also runs on each node and monitors latency and the volume of HTTP requests to the proxy.
|
||||
- A [cgroups collector](/collectors/cgroups.plugin/README.md), which collects CPU, memory, and bandwidth metrics for
|
||||
- A [cgroups collector](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md), which collects CPU, memory, and bandwidth metrics for
|
||||
each container running on your k8s cluster.
|
||||
|
||||
For a holistic view of Netdata's Kubernetes monitoring capabilities, see our guide: [_Monitor a Kubernetes (k8s) cluster
|
||||
with Netdata_](https://learn.netdata.cloud/guides/monitor/kubernetes-k8s-netdata).
|
||||
with Netdata_](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/kubernetes-k8s-netdata.md).
|
||||
|
||||
## What's next?
|
||||
|
||||
Netdata is capable of collecting metrics from hundreds of applications, such as web servers, databases, messaging
|
||||
brokers, and more. See more in the [application metrics doc](/docs/collect/application-metrics.md).
|
||||
brokers, and more. See more in the [application metrics doc](https://github.com/netdata/netdata/blob/master/docs/collect/application-metrics.md).
|
||||
|
||||
If you already have all the information you need about collecting metrics, move into Netdata's meaningful visualizations
|
||||
with [seeing an overview of your infrastructure](/docs/visualize/overview-infrastructure.md) using Netdata Cloud.
|
||||
with [seeing an overview of your infrastructure](https://github.com/netdata/netdata/blob/master/docs/visualize/overview-infrastructure.md) using Netdata Cloud.
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ learn_rel_path: "Setup"
|
|||
|
||||
When Netdata starts up, each collector searches for exposed metrics on the default endpoint established by that service
|
||||
or application's standard installation procedure. For example, the [Nginx
|
||||
collector](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/nginx) searches at
|
||||
collector](https://github.com/netdata/go.d.plugin/blob/master/modules/nginx/README.md) searches at
|
||||
`http://127.0.0.1/stub_status` for exposed metrics in the correct format. If an Nginx web server is running and exposes
|
||||
metrics on that endpoint, the collector begins gathering them.
|
||||
|
||||
|
|
@ -24,7 +24,7 @@ enable or configure a collector to gather all available metrics from your system
|
|||
You can enable/disable collectors individually, or enable/disable entire orchestrators, using their configuration files.
|
||||
For example, you can change the behavior of the Go orchestrator, or any of its collectors, by editing `go.d.conf`.
|
||||
|
||||
Use `edit-config` from your [Netdata config directory](/docs/configure/nodes.md#the-netdata-config-directory) to open
|
||||
Use `edit-config` from your [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory) to open
|
||||
the orchestrator primary configuration file:
|
||||
|
||||
```bash
|
||||
|
|
@ -37,14 +37,14 @@ enable/disable it with `yes` and `no` settings. Uncomment any line you change to
|
|||
start.
|
||||
|
||||
After you make your changes, restart the Agent with `sudo systemctl restart netdata`, or the [appropriate
|
||||
method](/docs/configure/start-stop-restart.md) for your system.
|
||||
method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system.
|
||||
|
||||
## Configure a collector
|
||||
|
||||
First, [find the collector](/collectors/COLLECTORS.md) you want to edit and open its documentation. Some software has
|
||||
First, [find the collector](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md) you want to edit and open its documentation. Some software has
|
||||
collectors written in multiple languages. In these cases, you should always pick the collector written in Go.
|
||||
|
||||
Use `edit-config` from your [Netdata config directory](/docs/configure/nodes.md#the-netdata-config-directory) to open a
|
||||
Use `edit-config` from your [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory) to open a
|
||||
collector's configuration file. For example, edit the Nginx collector with the following:
|
||||
|
||||
```bash
|
||||
|
|
@ -57,16 +57,16 @@ configure that collector. Uncomment any line you change to ensure the collector'
|
|||
read it on start.
|
||||
|
||||
After you make your changes, restart the Agent with `sudo systemctl restart netdata`, or the [appropriate
|
||||
method](/docs/configure/start-stop-restart.md) for your system.
|
||||
method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system.
|
||||
|
||||
## What's next?
|
||||
|
||||
Read high-level overviews on how Netdata collects [system metrics](/docs/collect/system-metrics.md), [container
|
||||
metrics](/docs/collect/container-metrics.md), and [application metrics](/docs/collect/application-metrics.md).
|
||||
Read high-level overviews on how Netdata collects [system metrics](https://github.com/netdata/netdata/blob/master/docs/collect/system-metrics.md), [container
|
||||
metrics](https://github.com/netdata/netdata/blob/master/docs/collect/container-metrics.md), and [application metrics](https://github.com/netdata/netdata/blob/master/docs/collect/application-metrics.md).
|
||||
|
||||
If you're already collecting all metrics from your systems, containers, and applications, it's time to move into
|
||||
Netdata's visualization features. [See an overview of your infrastructure](/docs/visualize/overview-infrastructure.md)
|
||||
Netdata's visualization features. [See an overview of your infrastructure](https://github.com/netdata/netdata/blob/master/docs/visualize/overview-infrastructure.md)
|
||||
using Netdata Cloud, or learn how to [interact with dashboards and
|
||||
charts](/docs/visualize/interact-dashboards-charts.md).
|
||||
charts](https://github.com/netdata/netdata/blob/master/docs/visualize/interact-dashboards-charts.md).
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ When Netdata starts, and with zero configuration, it auto-detects thousands of d
|
|||
per-second metrics.
|
||||
|
||||
Netdata can immediately collect metrics from these endpoints thanks to 300+ **collectors**, which all come pre-installed
|
||||
when you [install Netdata](/docs/get-started.mdx).
|
||||
when you [install Netdata](https://github.com/netdata/netdata/blob/master/docs/get-started.mdx).
|
||||
|
||||
Every collector has two primary jobs:
|
||||
|
||||
|
|
@ -23,15 +23,15 @@ Every collector has two primary jobs:
|
|||
|
||||
If the collector finds compatible metrics exposed on the configured endpoint, it begins a per-second collection job. The
|
||||
Netdata Agent gathers these metrics, sends them to the [database engine for
|
||||
storage](/docs/store/change-metrics-storage.md), and immediately [visualizes them
|
||||
meaningfully](/docs/visualize/interact-dashboards-charts.md) on dashboards.
|
||||
storage](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md), and immediately [visualizes them
|
||||
meaningfully](https://github.com/netdata/netdata/blob/master/docs/visualize/interact-dashboards-charts.md) on dashboards.
|
||||
|
||||
Each collector comes with a pre-defined configuration that matches the default setup for that application. This endpoint
|
||||
can be a URL and port, a socket, a file, a web page, and more.
|
||||
|
||||
For example, the [Nginx collector](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/nginx) searches
|
||||
For example, the [Nginx collector](https://github.com/netdata/go.d.plugin/blob/master/modules/nginx/README.md) searches
|
||||
at `http://127.0.0.1/stub_status`, which is the default endpoint for exposing Nginx metrics. The [web log collector for
|
||||
Nginx or Apache](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/weblog) searches at
|
||||
Nginx or Apache](https://github.com/netdata/go.d.plugin/blob/master/README.mdmodules/weblog) searches at
|
||||
`/var/log/nginx/access.log` and `/var/log/apache2/access.log`, respectively, both of which are standard locations for
|
||||
access log files on Linux systems.
|
||||
|
||||
|
|
@ -39,15 +39,15 @@ The endpoint is user-configurable, as are many other specifics of what a given c
|
|||
|
||||
## What can Netdata collect?
|
||||
|
||||
To quickly find your answer, see our [list of supported collectors](/collectors/COLLECTORS.md).
|
||||
To quickly find your answer, see our [list of supported collectors](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md).
|
||||
|
||||
Generally, Netdata's collectors can be grouped into three types:
|
||||
|
||||
- [Systems](/docs/collect/system-metrics.md): Monitor CPU, memory, disk, networking, systemd, eBPF, and much more.
|
||||
- [Systems](https://github.com/netdata/netdata/blob/master/docs/collect/system-metrics.md): Monitor CPU, memory, disk, networking, systemd, eBPF, and much more.
|
||||
Every metric exposed by `/proc`, `/sys`, and other Linux kernel sources.
|
||||
- [Containers](/docs/collect/container-metrics.md): Gather metrics from container agents, like `dockerd` or `kubectl`,
|
||||
- [Containers](https://github.com/netdata/netdata/blob/master/docs/collect/container-metrics.md): Gather metrics from container agents, like `dockerd` or `kubectl`,
|
||||
along with the resource usage of containers and the applications they run.
|
||||
- [Applications](/docs/collect/application-metrics.md): Collect per-second metrics from web servers, databases, logs,
|
||||
- [Applications](https://github.com/netdata/netdata/blob/master/docs/collect/application-metrics.md): Collect per-second metrics from web servers, databases, logs,
|
||||
message brokers, APM tools, email servers, and much more.
|
||||
|
||||
## Collector architecture and terminology
|
||||
|
|
@ -60,11 +60,11 @@ terms related to collecting metrics.
|
|||
- **Modules** are a type of collector.
|
||||
- **Orchestrators** are external plugins that run and manage one or more modules. They run as independent processes.
|
||||
The Go orchestrator is in active development.
|
||||
- [go.d.plugin](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/): An orchestrator for data
|
||||
- [go.d.plugin](https://github.com/netdata/go.d.plugin/blob/master/README.md): An orchestrator for data
|
||||
collection modules written in `go`.
|
||||
- [python.d.plugin](/collectors/python.d.plugin/README.md): An orchestrator for data collection modules written in
|
||||
- [python.d.plugin](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/README.md): An orchestrator for data collection modules written in
|
||||
`python` v2/v3.
|
||||
- [charts.d.plugin](/collectors/charts.d.plugin/README.md): An orchestrator for data collection modules written in
|
||||
- [charts.d.plugin](https://github.com/netdata/netdata/blob/master/collectors/charts.d.plugin/README.md): An orchestrator for data collection modules written in
|
||||
`bash` v4+.
|
||||
- **External plugins** gather metrics from external processes, such as a webserver or database, and run as independent
|
||||
processes that communicate with the Netdata daemon via pipes.
|
||||
|
|
@ -73,10 +73,10 @@ terms related to collecting metrics.
|
|||
|
||||
## What's next?
|
||||
|
||||
[Enable or configure a collector](/docs/collect/enable-configure.md) if the default settings are not compatible with
|
||||
[Enable or configure a collector](https://github.com/netdata/netdata/blob/master/docs/collect/enable-configure.md) if the default settings are not compatible with
|
||||
your infrastructure.
|
||||
|
||||
See our [collectors reference](/collectors/REFERENCE.md) for detailed information on Netdata's collector architecture,
|
||||
See our [collectors reference](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md) for detailed information on Netdata's collector architecture,
|
||||
troubleshooting a collector, developing a custom collector, and more.
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -11,53 +11,53 @@ learn_rel_path: "Concepts"
|
|||
# Collect system metrics with Netdata
|
||||
|
||||
Netdata collects thousands of metrics directly from the operating systems of physical and virtual systems, IoT/edge
|
||||
devices, and [containers](/docs/collect/container-metrics.md) with zero configuration.
|
||||
devices, and [containers](https://github.com/netdata/netdata/blob/master/docs/collect/container-metrics.md) with zero configuration.
|
||||
|
||||
To gather system metrics, Netdata uses roughly a dozen plugins, each of which has one or more collectors for very
|
||||
specific metrics exposed by the host. The system metrics Netdata users interact with most for health monitoring and
|
||||
performance troubleshooting are collected and visualized by `proc.plugin`, `cgroups.plugin`, and `ebpf.plugin`.
|
||||
|
||||
[**proc.plugin**](/collectors/proc.plugin/README.md) gathers metrics from the `/proc` and `/sys` folders in Linux
|
||||
[**proc.plugin**](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md) gathers metrics from the `/proc` and `/sys` folders in Linux
|
||||
systems, along with a few other endpoints, and is responsible for the bulk of the system metrics collected and
|
||||
visualized by Netdata. It collects CPU, memory, disks, load, networking, mount points, and more with zero configuration.
|
||||
It even allows Netdata to monitor its own resource utilization!
|
||||
|
||||
[**cgroups.plugin**](/collectors/cgroups.plugin/README.md) collects rich metrics about containers and virtual machines
|
||||
[**cgroups.plugin**](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md) collects rich metrics about containers and virtual machines
|
||||
using the virtual files under `/sys/fs/cgroup`. By reading cgroups, Netdata can instantly collect resource utilization
|
||||
metrics for systemd services, all containers (Docker, LXC, LXD, Libvirt, systemd-nspawn), and more. Learn more in the
|
||||
[collecting container metrics](/docs/collect/container-metrics.md) doc.
|
||||
[collecting container metrics](https://github.com/netdata/netdata/blob/master/docs/collect/container-metrics.md) doc.
|
||||
|
||||
[**ebpf.plugin**](/collectors/ebpf.plugin/README.md): Netdata's extended Berkeley Packet Filter (eBPF) collector
|
||||
[**ebpf.plugin**](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md): Netdata's extended Berkeley Packet Filter (eBPF) collector
|
||||
monitors Linux kernel-level metrics for file descriptors, virtual filesystem IO, and process management. You can use our
|
||||
eBPF collector to analyze how and when a process accesses files, when it makes system calls, whether it leaks memory or
|
||||
creating zombie processes, and more.
|
||||
|
||||
While the above plugins and associated collectors are the most important for system metrics, there are many others. You
|
||||
can find all system collectors in our [supported collectors list](/collectors/COLLECTORS.md#system-collectors).
|
||||
can find all system collectors in our [supported collectors list](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md#system-collectors).
|
||||
|
||||
## Collect Windows system metrics
|
||||
|
||||
Netdata is also capable of monitoring Windows systems. The [WMI
|
||||
collector](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/wmi) integrates with
|
||||
collector](https://github.com/netdata/go.d.plugin/blob/master/modules/wmi/README.md) integrates with
|
||||
[windows_exporter](https://github.com/prometheus-community/windows_exporter), a small Go-based binary that you can run
|
||||
on Windows systems. The WMI collector then gathers metrics from an endpoint created by windows_exporter, for more
|
||||
details see [the requirements](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/wmi#requirements).
|
||||
details see [the requirements](https://github.com/netdata/go.d.plugin/blob/master/modules/wmi/README.md#requirements).
|
||||
|
||||
Next, [configure the WMI
|
||||
collector](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/wmi#configuration) to point to the URL
|
||||
collector](https://github.com/netdata/go.d.plugin/blob/master/modules/wmi/README.md#configuration) to point to the URL
|
||||
and port of your exposed endpoint. Restart Netdata with `sudo systemctl restart netdata`, or the [appropriate
|
||||
method](/docs/configure/start-stop-restart.md) for your system. You'll start seeing Windows system metrics, such as CPU
|
||||
method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system. You'll start seeing Windows system metrics, such as CPU
|
||||
utilization, memory, bandwidth per NIC, number of processes, and much more.
|
||||
|
||||
For information about collecting metrics from applications _running on Windows systems_, see the [application metrics
|
||||
doc](/docs/collect/application-metrics.md#collect-metrics-from-applications-running-on-windows).
|
||||
doc](https://github.com/netdata/netdata/blob/master/docs/collect/application-metrics.md#collect-metrics-from-applications-running-on-windows).
|
||||
|
||||
## What's next?
|
||||
|
||||
Because there's some overlap between system metrics and [container metrics](/docs/collect/container-metrics.md), you
|
||||
Because there's some overlap between system metrics and [container metrics](https://github.com/netdata/netdata/blob/master/docs/collect/container-metrics.md), you
|
||||
should investigate Netdata's container compatibility if you use them heavily in your infrastructure.
|
||||
|
||||
If you don't use containers, skip ahead to collecting [application metrics](/docs/collect/application-metrics.md) with
|
||||
If you don't use containers, skip ahead to collecting [application metrics](https://github.com/netdata/netdata/blob/master/docs/collect/application-metrics.md) with
|
||||
Netdata.
|
||||
|
||||
|
||||
|
|
|
|||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue