Reorg learn 021723 (#14556)
* Change titles of agent alert notifications * Reintroduce netdata for iot * Eliminate guides category, merge health config docs * Rename setup to configuration * Codacy fixes and move health config reference
This commit is contained in:
parent
851ce5a184
commit
1413b5bac3
|
|
@ -6,7 +6,7 @@ custom_edit_url: "https://github.com/netdata/netdata/edit/master/aclk/README.md"
|
|||
sidebar_label: "Agent-Cloud link (ACLK)"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Setup"
|
||||
learn_rel_path: "Configuration"
|
||||
-->
|
||||
|
||||
# Agent-cloud link (ACLK)
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ custom_edit_url: "https://github.com/netdata/netdata/edit/master/claim/README.md
|
|||
sidebar_label: "Connect Agent to Cloud"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Setup"
|
||||
learn_rel_path: "Configuration"
|
||||
-->
|
||||
|
||||
# Connect Agent to Cloud
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ custom_edit_url: "https://github.com/netdata/netdata/edit/master/collectors/REFE
|
|||
sidebar_label: "Collectors configuration"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Setup"
|
||||
learn_rel_path: "Configuration"
|
||||
-->
|
||||
|
||||
# Collectors configuration reference
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ custom_edit_url: "https://github.com/netdata/netdata/edit/master/database/README
|
|||
sidebar_label: "Database"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Setup"
|
||||
learn_rel_path: "Configuration"
|
||||
-->
|
||||
|
||||
# Database
|
||||
|
|
|
|||
|
|
@ -32,8 +32,6 @@ To enable ML on your Netdata Agent, you need to edit the `[ml]` section in your
|
|||
|
||||
At a minimum you just need to set `enabled = yes` to enable ML with default params. More details about configuration can be found in the [Netdata Agent ML docs](https://learn.netdata.cloud/docs/agent/ml#configuration).
|
||||
|
||||
**Note**: Follow [this guide](https://github.com/netdata/netdata/blob/master/docs/guides/step-by-step/step-04.md) if you are unfamiliar with making configuration changes in Netdata.
|
||||
|
||||
When you have finished your configuration, restart Netdata with a command like `sudo systemctl restart netdata` for the config changes to take effect. You can find more info on restarting Netdata [here](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md).
|
||||
|
||||
After a brief delay, you should see the number of `trained` dimensions start to increase on the "dimensions" chart of the "Anomaly Detection" menu on the Overview page. By default the `minimum num samples to train = 3600` parameter means at least 1 hour of data is required to train initial models, but you could set this to `900` if you want to train initial models quicker but on less data. Over time, they will retrain on up to `maximum num samples to train = 14400` (4 hours by default), but you could increase this is you wanted to train on more data.
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/configure/
|
|||
sidebar_label: "Common configuration changes"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Setup"
|
||||
learn_rel_path: "Configuration"
|
||||
-->
|
||||
|
||||
# Common configuration changes
|
||||
|
|
|
|||
|
|
@ -2,10 +2,10 @@
|
|||
title: "Configure the Netdata Agent"
|
||||
description: "Netdata is zero-configuration for most users, but complex infrastructures may require you to tweak some of the Agent's granular settings."
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/configure/nodes.md"
|
||||
sidebar_label: "Setup"
|
||||
sidebar_label: "Configuration"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Setup"
|
||||
learn_rel_path: "Configuration"
|
||||
sidebar_position: 30
|
||||
-->
|
||||
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/configure/
|
|||
sidebar_label: "Secure your nodes"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Setup"
|
||||
learn_rel_path: "Configuration"
|
||||
-->
|
||||
|
||||
# Secure your nodes
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/export/ena
|
|||
sidebar_label: "Enable an exporting connector"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Setup"
|
||||
learn_rel_path: "Configuration"
|
||||
-->
|
||||
|
||||
# Enable an exporting connector
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ sidebar_label: "Monitor Nginx or Apache web server log files with Netdata"
|
|||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/collect-apache-nginx-web-logs.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides"
|
||||
learn_rel_path: "Miscellaneous"
|
||||
-->
|
||||
|
||||
# Monitor Nginx or Apache web server log files with Netdata
|
||||
|
|
@ -120,12 +120,5 @@ You can also edit this file directly with `edit-config`:
|
|||
./edit-config health.d/weblog.conf
|
||||
```
|
||||
|
||||
For more information about editing the defaults or writing new alarm entities, see our [health monitoring
|
||||
documentation](https://github.com/netdata/netdata/blob/master/health/README.md).
|
||||
|
||||
## What's next?
|
||||
|
||||
Now that you have web log collection up and running, we recommend you take a look at the collector's [documentation](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md) for some ideas of how you can turn these rather "boring" logs into powerful real-time tools for keeping your servers happy.
|
||||
|
||||
Don't forget to give GitHub user [Wing924](https://github.com/Wing924) a big 👍 for his hard work in starting up the Go
|
||||
refactoring effort.
|
||||
For more information about editing the defaults or writing new alarm entities, see our
|
||||
[health monitoring documentation](https://github.com/netdata/netdata/blob/master/health/README.md).
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ date: 2020-03-31
|
|||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/collect-unbound-metrics.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides"
|
||||
learn_rel_path: "Miscellaneous"
|
||||
-->
|
||||
|
||||
# Monitor Unbound DNS servers with Netdata
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ image: /img/seo/guides/configure/performance.png
|
|||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/configure/performance.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides"
|
||||
learn_rel_path: "Configuration"
|
||||
-->
|
||||
|
||||
# How to optimize the Netdata Agent's performance
|
||||
|
|
|
|||
|
|
@ -1,162 +0,0 @@
|
|||
<!--
|
||||
title: "Netdata Longer Metrics Retention"
|
||||
sidebar_label: "Netdata Longer Metrics Retention"
|
||||
description: ""
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/longer-metrics-storage.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides"
|
||||
-->
|
||||
|
||||
# Netdata Longer Metrics Retention
|
||||
|
||||
Metrics retention affects 3 parameters on the operation of a Netdata Agent:
|
||||
|
||||
1. The disk space required to store the metrics.
|
||||
2. The memory the Netdata Agent will require to have that retention available for queries.
|
||||
3. The CPU resources that will be required to query longer time-frames.
|
||||
|
||||
As retention increases, the resources required to support that retention increase too.
|
||||
|
||||
Since Netdata Agents usually run at the edge, inside production systems, Netdata Agent **parents** should be considered. When having a **parent - child** setup, the child (the Netdata Agent running on a production system) delegates all its functions, including longer metrics retention and querying, to the parent node that can dedicate more resources to this task. A single Netdata Agent parent can centralize multiple children Netdata Agents (dozens, hundreds, or even thousands depending on its available resources).
|
||||
|
||||
|
||||
## Ephemerality of metrics
|
||||
|
||||
The ephemerality of metrics plays an important role in retention. In environments where metrics stop being collected and new metrics are constantly being generated, we are interested about 2 parameters:
|
||||
|
||||
1. The **expected concurrent number of metrics** as an average for the lifetime of the database.
|
||||
This affects mainly the storage requirements.
|
||||
|
||||
2. The **expected total number of unique metrics** for the lifetime of the database.
|
||||
This affects mainly the memory requirements for having all these metrics indexed and available to be queried.
|
||||
|
||||
## Granularity of metrics
|
||||
|
||||
The granularity of metrics (the frequency they are collected and stored, i.e. their resolution) is significantly affecting retention.
|
||||
|
||||
Lowering the granularity from per second to every two seconds, will double their retention and half the CPU requirements of the Netdata Agent, without affecting disk space or memory requirements.
|
||||
|
||||
## Which database mode to use
|
||||
|
||||
Netdata Agents support multiple database modes.
|
||||
|
||||
The default mode `[db].mode = dbengine` has been designed to scale for longer retentions.
|
||||
|
||||
The other available database modes are designed to minimize resource utilization and should usually be considered on **parent - child** setups at the children side.
|
||||
|
||||
So,
|
||||
|
||||
* On a single node setup, use `[db].mode = dbengine` to increase retention.
|
||||
* On a **parent - child** setup, use `[db].mode = dbengine` on the parent to increase retention and a more resource efficient mode (like `save`, `ram` or `none`) for the child to minimize resources utilization.
|
||||
|
||||
To use `dbengine`, set this in `netdata.conf` (it is the default):
|
||||
|
||||
```
|
||||
[db]
|
||||
mode = dbengine
|
||||
```
|
||||
|
||||
## Tiering
|
||||
|
||||
`dbengine` supports tiering. Tiering allows having up to 3 versions of the data:
|
||||
|
||||
1. Tier 0 is the high resolution data.
|
||||
2. Tier 1 is the first tier that samples data every 60 data collections of Tier 0.
|
||||
3. Tier 2 is the second tier that samples data every 3600 data collections of Tier 0 (60 of Tier 1).
|
||||
|
||||
To enable tiering set `[db].storage tiers` in `netdata.conf` (the default is 1, to enable only Tier 0):
|
||||
|
||||
```
|
||||
[db]
|
||||
mode = dbengine
|
||||
storage tiers = 3
|
||||
```
|
||||
|
||||
## Disk space requirements
|
||||
|
||||
Netdata Agents require about 1 bytes on disk per database point on Tier 0 and 4 times more on higher tiers (Tier 1 and 2). They require 4 times more storage per point compared to Tier 0, because for every point higher tiers store `min`, `max`, `sum`, `count` and `anomaly rate` (the values are 5, but they require 4 times the storage because `count` and `anomaly rate` are 16-bit integers). The `average` is calculated on the fly at query time using `sum / count`.
|
||||
|
||||
### Tier 0 - per second for a week
|
||||
|
||||
For 2000 metrics, collected every second and retained for a week, Tier 0 needs: 1 byte x 2000 metrics x 3600 secs per hour x 24 hours per day x 7 days per week = 1100MB.
|
||||
|
||||
The setting to control this is in `netdata.conf`:
|
||||
|
||||
```
|
||||
[db]
|
||||
mode = dbengine
|
||||
|
||||
# per second data collection
|
||||
update every = 1
|
||||
|
||||
# enable only Tier 0
|
||||
storage tiers = 1
|
||||
|
||||
# Tier 0, per second data for a week
|
||||
dbengine multihost disk space MB = 1100
|
||||
```
|
||||
|
||||
By setting it to `1100` and restarting the Netdata Agent, this node will start maintaining about a week of data. But pay attention to the number of metrics. If you have more than 2000 metrics on a node, or you need more that a week of high resolution metrics, you may need to adjust this setting accordingly.
|
||||
|
||||
### Tier 1 - per minute for a month
|
||||
|
||||
Tier 1 is by default sampling the data every 60 points of Tier 0. If Tier 0 is per second, then Tier 1 is per minute.
|
||||
|
||||
Tier 1 needs 4 times more storage per point compared to Tier 0. So, for 2000 metrics, with per minute resolution, retained for a month, Tier 1 needs: 4 bytes x 2000 metrics x 60 minutes per hour x 24 hours per day x 30 days per month = 330MB.
|
||||
|
||||
Do this in `netdata.conf`:
|
||||
|
||||
```
|
||||
[db]
|
||||
mode = dbengine
|
||||
|
||||
# per second data collection
|
||||
update every = 1
|
||||
|
||||
# enable only Tier 0 and Tier 1
|
||||
storage tiers = 2
|
||||
|
||||
# Tier 0, per second data for a week
|
||||
dbengine multihost disk space MB = 1100
|
||||
|
||||
# Tier 1, per minute data for a month
|
||||
dbengine tier 1 multihost disk space MB = 330
|
||||
```
|
||||
|
||||
Once `netdata.conf` is edited, the Netdata Agent needs to be restarted for the changes to take effect.
|
||||
|
||||
### Tier 2 - per hour for a year
|
||||
|
||||
Tier 2 is by default sampling data every 3600 points of Tier 0 (60 of Tier 1). If Tier 0 is per second, then Tier 2 is per hour.
|
||||
|
||||
The storage requirements are the same to Tier 1.
|
||||
|
||||
For 2000 metrics, with per hour resolution, retained for a year, Tier 2 needs: 4 bytes x 2000 metrics x 24 hours per day x 365 days per year = 67MB.
|
||||
|
||||
Do this in `netdata.conf`:
|
||||
|
||||
```
|
||||
[db]
|
||||
mode = dbengine
|
||||
|
||||
# per second data collection
|
||||
update every = 1
|
||||
|
||||
# enable only Tier 0 and Tier 1
|
||||
storage tiers = 3
|
||||
|
||||
# Tier 0, per second data for a week
|
||||
dbengine multihost disk space MB = 1100
|
||||
|
||||
# Tier 1, per minute data for a month
|
||||
dbengine tier 1 multihost disk space MB = 330
|
||||
|
||||
# Tier 2, per hour data for a year
|
||||
dbengine tier 2 multihost disk space MB = 67
|
||||
```
|
||||
|
||||
Once `netdata.conf` is edited, the Netdata Agent needs to be restarted for the changes to take effect.
|
||||
|
||||
|
||||
|
||||
|
|
@ -4,7 +4,7 @@ sidebar_label: "Monitor CockroachDB metrics with Netdata"
|
|||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor-cockroachdb.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides"
|
||||
learn_rel_path: "Miscellaneous"
|
||||
-->
|
||||
|
||||
# Monitor CockroachDB metrics with Netdata
|
||||
|
|
@ -29,7 +29,6 @@ Let's dive in and walk through the process of monitoring CockroachDB metrics wit
|
|||
- [Configure the CockroachDB collector](#configure-the-cockroachdb-collector)
|
||||
- [Manual setup for a local CockroachDB database](#manual-setup-for-a-local-cockroachdb-database)
|
||||
- [Tweak CockroachDB alarms](#tweak-cockroachdb-alarms)
|
||||
- [What's next?](#whats-next)
|
||||
|
||||
## Configure the CockroachDB collector
|
||||
|
||||
|
|
@ -117,23 +116,3 @@ cd /etc/netdata/ # Replace with your Netdata configuration directory, if not /et
|
|||
```
|
||||
|
||||
For more information about editing the defaults or writing new alarm entities, see our documentation on [configuring health alarms](https://github.com/netdata/netdata/blob/master/docs/monitor/configure-alarms.md).
|
||||
|
||||
## What's next?
|
||||
|
||||
Now that you're collecting metrics from your CockroachDB databases, let us know how it's working for you! There's always
|
||||
room for improvement or refinement based on real-world use cases. Feel free to [file an
|
||||
issue](https://github.com/netdata/netdata/issues/new?assignees=&labels=bug%2Cneeds+triage&template=BUG_REPORT.yml) with
|
||||
your
|
||||
thoughts.
|
||||
|
||||
Also, be sure to check out these useful resources:
|
||||
|
||||
- [Netdata's CockroachDB documentation](https://github.com/netdata/go.d.plugin/blob/master/modules/cockroachdb/README.md)
|
||||
- [Netdata's CockroachDB configuration](https://github.com/netdata/go.d.plugin/blob/master/config/go.d/cockroachdb.conf)
|
||||
- [Netdata's CockroachDB alarms](https://github.com/netdata/netdata/blob/29d9b5e51603792ee27ef5a21f1de0ba8e130158/health/health.d/cockroachdb.conf)
|
||||
- [CockroachDB homepage](https://www.cockroachlabs.com/product/)
|
||||
- [CockroachDB documentation](https://www.cockroachlabs.com/docs/stable/)
|
||||
- [`_status/vars` endpoint docs](https://www.cockroachlabs.com/docs/stable/monitoring-and-alerting.html#prometheus-endpoint)
|
||||
- [Monitor CockroachDB with Prometheus](https://www.cockroachlabs.com/docs/stable/monitor-cockroachdb-with-prometheus.html)
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ sidebar_label: "Monitor a Hadoop cluster with Netdata"
|
|||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor-hadoop-cluster.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides"
|
||||
learn_rel_path: "Miscellaneous"
|
||||
-->
|
||||
|
||||
# Monitor a Hadoop cluster with Netdata
|
||||
|
|
@ -188,20 +188,5 @@ sudo /etc/netdata/edit-config health.d/hdfs.conf
|
|||
sudo /etc/netdata/edit-config health.d/zookeeper.conf
|
||||
```
|
||||
|
||||
For more information about editing the defaults or writing new alarm entities, see our [health monitoring
|
||||
documentation](https://github.com/netdata/netdata/blob/master/health/README.md).
|
||||
|
||||
## What's next?
|
||||
|
||||
If you're having issues with Netdata auto-detecting your HDFS/Zookeeper servers, or want to help improve how Netdata
|
||||
collects or presents metrics from these services, feel free to [file an
|
||||
issue](https://github.com/netdata/netdata/issues/new?assignees=&labels=bug%2Cneeds+triage&template=BUG_REPORT.yml).
|
||||
|
||||
- Read up on the [HDFS configuration
|
||||
file](https://github.com/netdata/go.d.plugin/blob/master/config/go.d/hdfs.conf) to understand how to configure
|
||||
global options or per-job options, such as username/password, TLS certificates, timeouts, and more.
|
||||
- Read up on the [Zookeeper configuration
|
||||
file](https://github.com/netdata/go.d.plugin/blob/master/config/go.d/zookeeper.conf) to understand how to configure
|
||||
global options or per-job options, timeouts, TLS certificates, and more.
|
||||
|
||||
|
||||
For more information about editing the defaults or writing new alarm entities, see our
|
||||
[health monitoring documentation](https://github.com/netdata/netdata/blob/master/health/README.md).
|
||||
|
|
|
|||
|
|
@ -1,193 +0,0 @@
|
|||
<!--
|
||||
title: "Detect anomalies in systems and applications"
|
||||
sidebar_label: "Detect anomalies in systems and applications"
|
||||
description: "Detect anomalies in any system, container, or application in your infrastructure with machine learning and the open-source Netdata Agent."
|
||||
image: /img/seo/guides/monitor/anomaly-detection.png
|
||||
author: "Joel Hans"
|
||||
author_title: "Editorial Director, Technical & Educational Resources"
|
||||
author_img: "/img/authors/joel-hans.jpg"
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/anomaly-detection-python.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides/Monitor"
|
||||
-->
|
||||
|
||||
# Detect anomalies in systems and applications
|
||||
|
||||
Beginning with v1.27, the [open-source Netdata Agent](https://github.com/netdata/netdata) is capable of unsupervised
|
||||
[anomaly detection](https://en.wikipedia.org/wiki/Anomaly_detection) with machine learning (ML). As with all things
|
||||
Netdata, the anomalies collector comes with preconfigured alarms and instant visualizations that require no query
|
||||
languages or organizing metrics. You configure the collector to look at specific charts, and it handles the rest.
|
||||
|
||||
Netdata's implementation uses a handful of functions in the [Python Outlier Detection (PyOD)
|
||||
library](https://github.com/yzhao062/pyod/tree/master), which periodically runs a `train` function that learns what
|
||||
"normal" looks like on your node and creates an ML model for each chart, then utilizes the
|
||||
[`predict_proba()`](https://pyod.readthedocs.io/en/latest/api_cc.html#pyod.models.base.BaseDetector.predict_proba) and
|
||||
[`predict()`](https://pyod.readthedocs.io/en/latest/api_cc.html#pyod.models.base.BaseDetector.predict) PyOD functions to
|
||||
quantify how anomalous certain charts are.
|
||||
|
||||
All these metrics and alarms are available for centralized monitoring in [Netdata Cloud](https://app.netdata.cloud). If
|
||||
you choose to sign up for Netdata Cloud and [connect your nodes](https://github.com/netdata/netdata/blob/master/claim/README.md), you will have the ability to run
|
||||
tailored anomaly detection on every node in your infrastructure, regardless of its purpose or workload.
|
||||
|
||||
In this guide, you'll learn how to set up the anomalies collector to instantly detect anomalies in an Nginx web server
|
||||
and/or the node that hosts it, which will give you the tools to configure parallel unsupervised monitors for any
|
||||
application in your infrastructure. Let's get started.
|
||||
|
||||
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- A node running the Netdata Agent. If you don't yet have that, [install Netdata](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md).
|
||||
- A Netdata Cloud account. [Sign up](https://app.netdata.cloud) if you don't have one already.
|
||||
- Familiarity with configuring the Netdata Agent with [`edit-config`](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md).
|
||||
- _Optional_: An Nginx web server running on the same node to follow the example configuration steps.
|
||||
|
||||
## Install required Python packages
|
||||
|
||||
The anomalies collector uses a few Python packages, available with `pip3`, to run ML training. It requires
|
||||
[`numba`](http://numba.pydata.org/), [`scikit-learn`](https://scikit-learn.org/stable/),
|
||||
[`pyod`](https://pyod.readthedocs.io/en/latest/), in addition to
|
||||
[`netdata-pandas`](https://github.com/netdata/netdata-pandas), which is a package built by the Netdata team to pull data
|
||||
from a Netdata Agent's API into a [Pandas](https://pandas.pydata.org/). Read more about `netdata-pandas` on its [package
|
||||
repo](https://github.com/netdata/netdata-pandas) or in Netdata's [community
|
||||
repo](https://github.com/netdata/community/tree/main/netdata-agent-api/netdata-pandas).
|
||||
|
||||
```bash
|
||||
# Become the netdata user
|
||||
sudo su -s /bin/bash netdata
|
||||
|
||||
# Install required packages for the netdata user
|
||||
pip3 install --user netdata-pandas==0.0.38 numba==0.50.1 scikit-learn==0.23.2 pyod==0.8.3
|
||||
```
|
||||
|
||||
> If the `pip3` command fails, you need to install it. For example, on an Ubuntu system, use `sudo apt install
|
||||
> python3-pip`.
|
||||
|
||||
Use `exit` to become your normal user again.
|
||||
|
||||
## Enable the anomalies collector
|
||||
|
||||
Navigate to your [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory) and use `edit-config`
|
||||
to open the `python.d.conf` file.
|
||||
|
||||
```bash
|
||||
sudo ./edit-config python.d.conf
|
||||
```
|
||||
|
||||
In `python.d.conf` file, search for the `anomalies` line. If the line exists, set the value to `yes`. Add the line
|
||||
yourself if it doesn't already exist. Either way, the final result should look like:
|
||||
|
||||
```conf
|
||||
anomalies: yes
|
||||
```
|
||||
|
||||
[Restart the Agent](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) with `sudo systemctl restart netdata`, or the [appropriate
|
||||
method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system, to start up the anomalies collector. By default, the
|
||||
model training process runs every 30 minutes, and uses the previous 4 hours of metrics to establish a baseline for
|
||||
health and performance across the default included charts.
|
||||
|
||||
> 💡 The anomaly collector may need 30-60 seconds to finish its initial training and have enough data to start
|
||||
> generating anomaly scores. You may need to refresh your browser tab for the **Anomalies** section to appear in menus
|
||||
> on both the local Agent dashboard or Netdata Cloud.
|
||||
|
||||
## Configure the anomalies collector
|
||||
|
||||
Open `python.d/anomalies.conf` with `edit-conf`.
|
||||
|
||||
```bash
|
||||
sudo ./edit-config python.d/anomalies.conf
|
||||
```
|
||||
|
||||
The file contains many user-configurable settings with sane defaults. Here are some important settings that don't
|
||||
involve tweaking the behavior of the ML training itself.
|
||||
|
||||
- `charts_regex`: Which charts to train models for and run anomaly detection on, with each chart getting a separate
|
||||
model.
|
||||
- `charts_to_exclude`: Specific charts, selected by the regex in `charts_regex`, to exclude.
|
||||
- `train_every_n`: How often to train the ML models.
|
||||
- `train_n_secs`: The number of historical observations to train each model on. The default is 4 hours, but if your node
|
||||
doesn't have historical metrics going back that far, consider [changing the metrics retention
|
||||
policy](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md) or reducing this window.
|
||||
- `custom_models`: A way to define custom models that you want anomaly probabilities for, including multi-node or
|
||||
streaming setups.
|
||||
|
||||
> ⚠️ Setting `charts_regex` with many charts or `train_n_secs` to a very large number will have an impact on the
|
||||
> resources and time required to train a model for every chart. The actual performance implications depend on the
|
||||
> resources available on your node. If you plan on changing these settings beyond the default, or what's mentioned in
|
||||
> this guide, make incremental changes to observe the performance impact. Considering `train_max_n` to cap the number of
|
||||
> observations actually used to train on.
|
||||
|
||||
### Run anomaly detection on Nginx and log file metrics
|
||||
|
||||
As mentioned above, this guide uses an Nginx web server to demonstrate how the anomalies collector works. You must
|
||||
configure the collector to monitor charts from the
|
||||
[Nginx](https://github.com/netdata/go.d.plugin/blob/master/modules/nginx/README.md) and [web
|
||||
log](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md) collectors.
|
||||
|
||||
`charts_regex` allows for some basic regex, such as wildcards (`*`) to match all contexts with a certain pattern. For
|
||||
example, `system\..*` matches with any chart with a context that begins with `system.`, and ends in any number of other
|
||||
characters (`.*`). Note the escape character (`\`) around the first period to capture a period character exactly, and
|
||||
not any character.
|
||||
|
||||
Change `charts_regex` in `anomalies.conf` to the following:
|
||||
|
||||
```conf
|
||||
charts_regex: 'system\..*|nginx_local\..*|web_log_nginx\..*|apps.cpu|apps.mem'
|
||||
```
|
||||
|
||||
This value tells the anomaly collector to train against every `system.` chart, every `nginx_local` chart, every
|
||||
`web_log_nginx` chart, and specifically the `apps.cpu` and `apps.mem` charts.
|
||||
|
||||
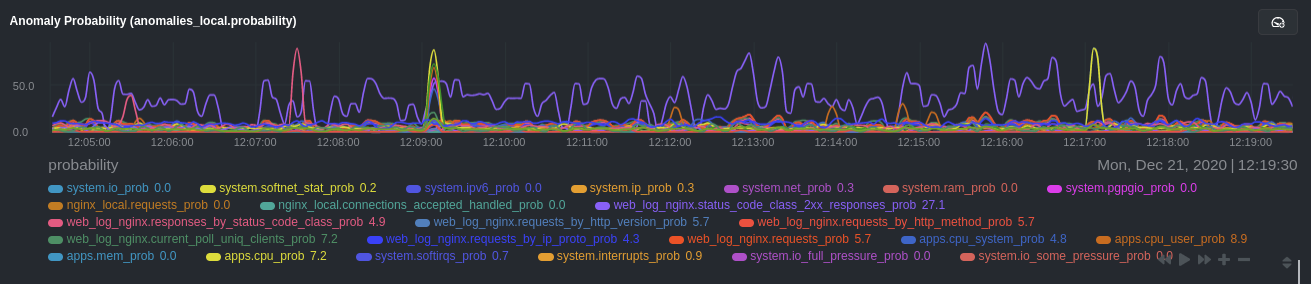
|
||||
|
||||
### Remove some metrics from anomaly detection
|
||||
|
||||
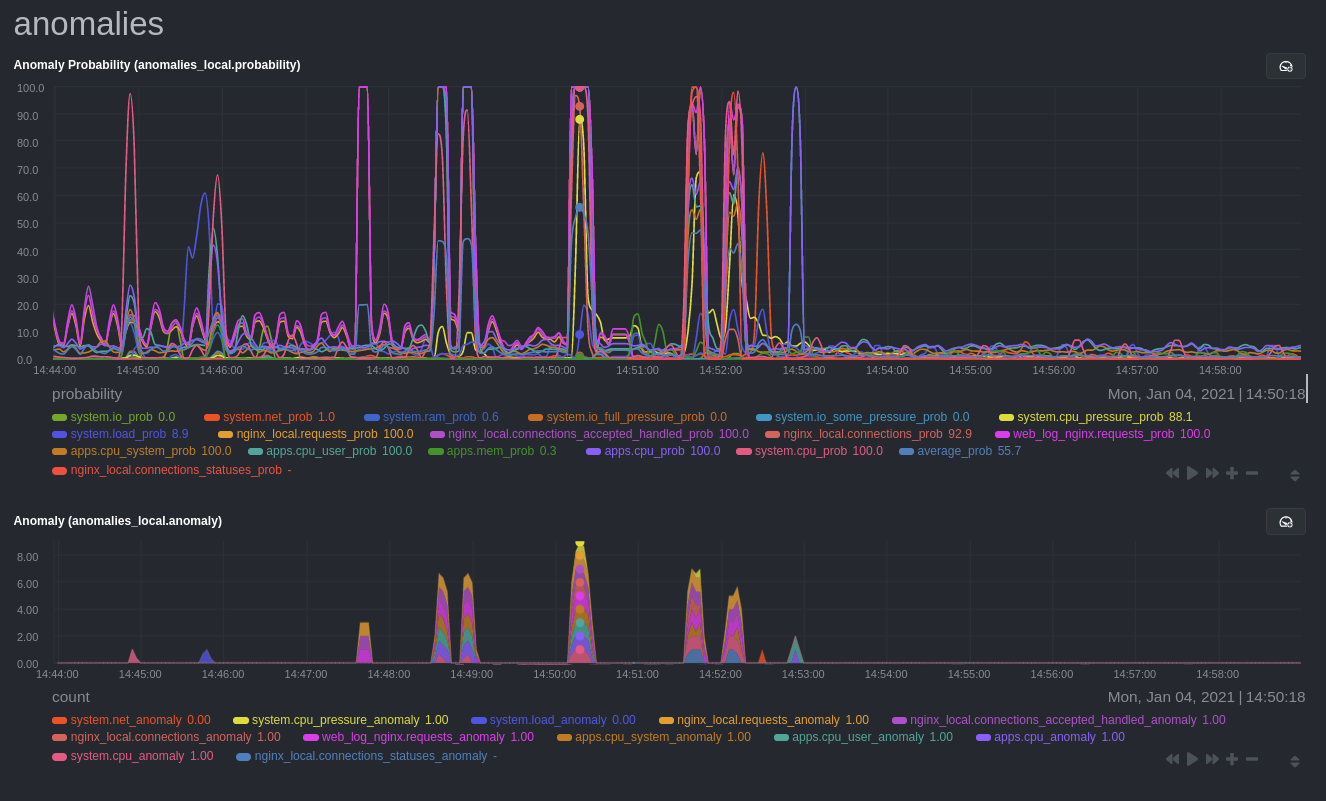
As you can see in the above screenshot, this node is now looking for anomalies in many places. The result is a single
|
||||
`anomalies_local.probability` chart with more than twenty dimensions, some of which the dashboard hides at the bottom of
|
||||
a scrollable area. In addition, training and analyzing the anomaly collector on many charts might require more CPU
|
||||
utilization that you're willing to give.
|
||||
|
||||
First, explicitly declare which `system.` charts to monitor rather than of all of them using regex (`system\..*`).
|
||||
|
||||
```conf
|
||||
charts_regex: 'system\.cpu|system\.load|system\.io|system\.net|system\.ram|nginx_local\..*|web_log_nginx\..*|apps.cpu|apps.mem'
|
||||
```
|
||||
|
||||
Next, remove some charts with the `charts_to_exclude` setting. For this example, using an Nginx web server, focus on the
|
||||
volume of requests/responses, not, for example, which type of 4xx response a user might receive.
|
||||
|
||||
```conf
|
||||
charts_to_exclude: 'web_log_nginx.excluded_requests,web_log_nginx.responses_by_status_code_class,web_log_nginx.status_code_class_2xx_responses,web_log_nginx.status_code_class_4xx_responses,web_log_nginx.current_poll_uniq_clients,web_log_nginx.requests_by_http_method,web_log_nginx.requests_by_http_version,web_log_nginx.requests_by_ip_proto'
|
||||
```
|
||||
|
||||
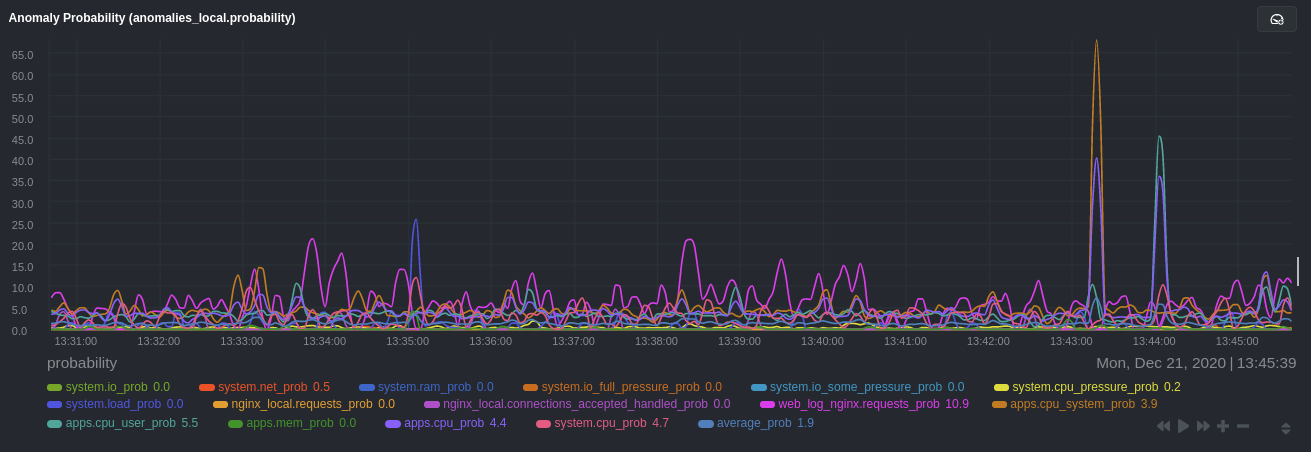
|
||||
|
||||
Apply the ideas behind the collector's regex and exclude settings to any other
|
||||
[system](https://github.com/netdata/netdata/blob/master/docs/collect/system-metrics.md), [container](https://github.com/netdata/netdata/blob/master/docs/collect/container-metrics.md), or
|
||||
[application](https://github.com/netdata/netdata/blob/master/docs/collect/application-metrics.md) metrics you want to detect anomalies for.
|
||||
|
||||
## What's next?
|
||||
|
||||
Now that you know how to set up unsupervised anomaly detection in the Netdata Agent, using an Nginx web server as an
|
||||
example, it's time to apply that knowledge to other mission-critical parts of your infrastructure. If you're not sure
|
||||
what to monitor next, check out our list of [collectors](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md) to see what kind of metrics Netdata
|
||||
can collect from your systems, containers, and applications.
|
||||
|
||||
Keep on moving to [part 2](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/visualize-monitor-anomalies.md), which covers the charts and alarms
|
||||
Netdata creates for unsupervised anomaly detection.
|
||||
|
||||
For a different troubleshooting experience, try out the [Metric
|
||||
Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md) feature in Netdata Cloud. Metric
|
||||
Correlations helps you perform faster root cause analysis by narrowing a dashboard to only the charts most likely to be
|
||||
related to an anomaly.
|
||||
|
||||
### Related reference documentation
|
||||
|
||||
- [Netdata Agent · Anomalies collector](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/anomalies/README.md)
|
||||
- [Netdata Agent · Nginx collector](https://github.com/netdata/go.d.plugin/blob/master/modules/nginx/README.md)
|
||||
- [Netdata Agent · web log collector](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md)
|
||||
- [Netdata Cloud · Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md)
|
||||
|
|
@ -3,13 +3,9 @@ title: "Machine learning (ML) powered anomaly detection"
|
|||
sidebar_label: "Machine learning (ML) powered anomaly detection"
|
||||
description: "Detect anomalies in any system, container, or application in your infrastructure with machine learning and the open-source Netdata Agent."
|
||||
image: /img/seo/guides/monitor/anomaly-detection.png
|
||||
author: "Andrew Maguire"
|
||||
author_title: "Analytics & ML Lead"
|
||||
author_img: "/img/authors/andy-maguire.jpg"
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/anomaly-detection.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides/Monitor"
|
||||
learn_rel_path: "Operations"
|
||||
-->
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -1,185 +0,0 @@
|
|||
<!--
|
||||
title: "Use dimension templates to create dynamic alarms"
|
||||
sidebar_label: "Use dimension templates to create dynamic alarms"
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/dimension-templates.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides/Monitor"
|
||||
-->
|
||||
|
||||
# Use dimension templates to create dynamic alarms
|
||||
|
||||
Your ability to monitor the health of your systems and applications relies on your ability to create and maintain
|
||||
the best set of alarms for your particular needs.
|
||||
|
||||
In v1.18 of Netdata, we introduced **dimension templates** for alarms, which simplifies the process of
|
||||
writing [alarm entities](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#health-entity-reference) for
|
||||
charts with many dimensions.
|
||||
|
||||
Dimension templates can condense many individual entities into one—no more copy-pasting one entity and changing the
|
||||
`alarm`/`template` and `lookup` lines for each dimension you'd like to monitor.
|
||||
|
||||
They are, however, an advanced health monitoring feature. For more basic instructions on creating your first alarm,
|
||||
check out our [health monitoring documentation](https://github.com/netdata/netdata/blob/master/health/README.md), which also includes
|
||||
[examples](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#example-alarms).
|
||||
|
||||
## The fundamentals of `foreach`
|
||||
|
||||
Our dimension templates update creates a new `foreach` parameter to the
|
||||
existing [`lookup` line](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alarm-line-lookup). This
|
||||
is where the magic happens.
|
||||
|
||||
You use the `foreach` parameter to specify which dimensions you want to monitor with this single alarm. You can separate
|
||||
them with a comma (`,`) or a pipe (`|`). You can also use
|
||||
a [Netdata simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to create
|
||||
many alarms with a regex-like syntax.
|
||||
|
||||
The `foreach` parameter _has_ to be the last parameter in your `lookup` line, and if you have both `of` and `foreach` in
|
||||
the same `lookup` line, Netdata will ignore the `of` parameter and use `foreach` instead.
|
||||
|
||||
Let's get into some examples so you can see how the new parameter works.
|
||||
|
||||
> ⚠️ The following entities are examples to showcase the functionality and syntax of dimension templates. They are not
|
||||
> meant to be run as-is on production systems.
|
||||
|
||||
## Condensing entities with `foreach`
|
||||
|
||||
Let's say you want to monitor the `system`, `user`, and `nice` dimensions in your system's overall CPU utilization.
|
||||
Before dimension templates, you would need the following three entities:
|
||||
|
||||
```yaml
|
||||
alarm: cpu_system
|
||||
on: system.cpu
|
||||
lookup: average -10m percentage of system
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
|
||||
alarm: cpu_user
|
||||
on: system.cpu
|
||||
lookup: average -10m percentage of user
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
|
||||
alarm: cpu_nice
|
||||
on: system.cpu
|
||||
lookup: average -10m percentage of nice
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
```
|
||||
|
||||
With dimension templates, you can condense these into a single alarm. Take note of the `alarm` and `lookup` lines.
|
||||
|
||||
```yaml
|
||||
alarm: cpu_template
|
||||
on: system.cpu
|
||||
lookup: average -10m percentage foreach system,user,nice
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
```
|
||||
|
||||
The `alarm` line specifies the naming scheme Netdata will use. You can use whatever naming scheme you'd like, with `.`
|
||||
and `_` being the only allowed symbols.
|
||||
|
||||
The `lookup` line has changed from `of` to `foreach`, and we're now passing three dimensions.
|
||||
|
||||
In this example, Netdata will create three alarms with the names `cpu_template_system`, `cpu_template_user`, and
|
||||
`cpu_template_nice`. Every minute, each alarm will use the same database query to calculate the average CPU usage for
|
||||
the `system`, `user`, and `nice` dimensions over the last 10 minutes and send out alarms if necessary.
|
||||
|
||||
You can find these three alarms active by clicking on the **Alarms** button in the top navigation, and then clicking on
|
||||
the **All** tab and scrolling to the **system - cpu** collapsible section.
|
||||
|
||||
|
||||
|
||||
Let's look at some other examples of how `foreach` works so you can best apply it in your configurations.
|
||||
|
||||
### Using a Netdata simple pattern in `foreach`
|
||||
|
||||
In the last example, we used `foreach system,user,nice` to create three distinct alarms using dimension templates. But
|
||||
what if you want to quickly create alarms for _all_ the dimensions of a given chart?
|
||||
|
||||
Use a [simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md)! One example of a simple pattern is a single wildcard
|
||||
(`*`).
|
||||
|
||||
Instead of monitoring system CPU usage, let's monitor per-application CPU usage using the `apps.cpu` chart. Passing a
|
||||
wildcard as the simple pattern tells Netdata to create a separate alarm for _every_ process on your system:
|
||||
|
||||
```yaml
|
||||
alarm: app_cpu
|
||||
on: apps.cpu
|
||||
lookup: average -10m percentage foreach *
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
```
|
||||
|
||||
This entity will now create alarms for every dimension in the `apps.cpu` chart. Given that most `apps.cpu` charts have
|
||||
10 or more dimensions, using the wildcard ensures you catch every CPU-hogging process.
|
||||
|
||||
To learn more about how to use simple patterns with dimension templates, see
|
||||
our [simple patterns documentation](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md).
|
||||
|
||||
## Using `foreach` with alarm templates
|
||||
|
||||
Dimension templates also work
|
||||
with [alarm templates](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alarm-line-alarm-or-template).
|
||||
Alarm templates help you create alarms for all the charts with a given context—for example, all the cores of your
|
||||
system's CPU.
|
||||
|
||||
By combining the two, you can create dozens of individual alarms with a single template entity. Here's how you would
|
||||
create alarms for the `system`, `user`, and `nice` dimensions for every chart in the `cpu.cpu` context—or, in other
|
||||
words, every CPU core.
|
||||
|
||||
```yaml
|
||||
template: cpu_template
|
||||
on: cpu.cpu
|
||||
lookup: average -10m percentage foreach system,user,nice
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
```
|
||||
|
||||
On a system with a 6-core, 12-thread Ryzen 5 1600 CPU, this one entity creates alarms on the following charts and
|
||||
dimensions:
|
||||
|
||||
- `cpu.cpu0`
|
||||
- `cpu_template_user`
|
||||
- `cpu_template_system`
|
||||
- `cpu_template_nice`
|
||||
- `cpu.cpu1`
|
||||
- `cpu_template_user`
|
||||
- `cpu_template_system`
|
||||
- `cpu_template_nice`
|
||||
- `cpu.cpu2`
|
||||
- `cpu_template_user`
|
||||
- `cpu_template_system`
|
||||
- `cpu_template_nice`
|
||||
- ...
|
||||
- `cpu.cpu11`
|
||||
- `cpu_template_user`
|
||||
- `cpu_template_system`
|
||||
- `cpu_template_nice`
|
||||
|
||||
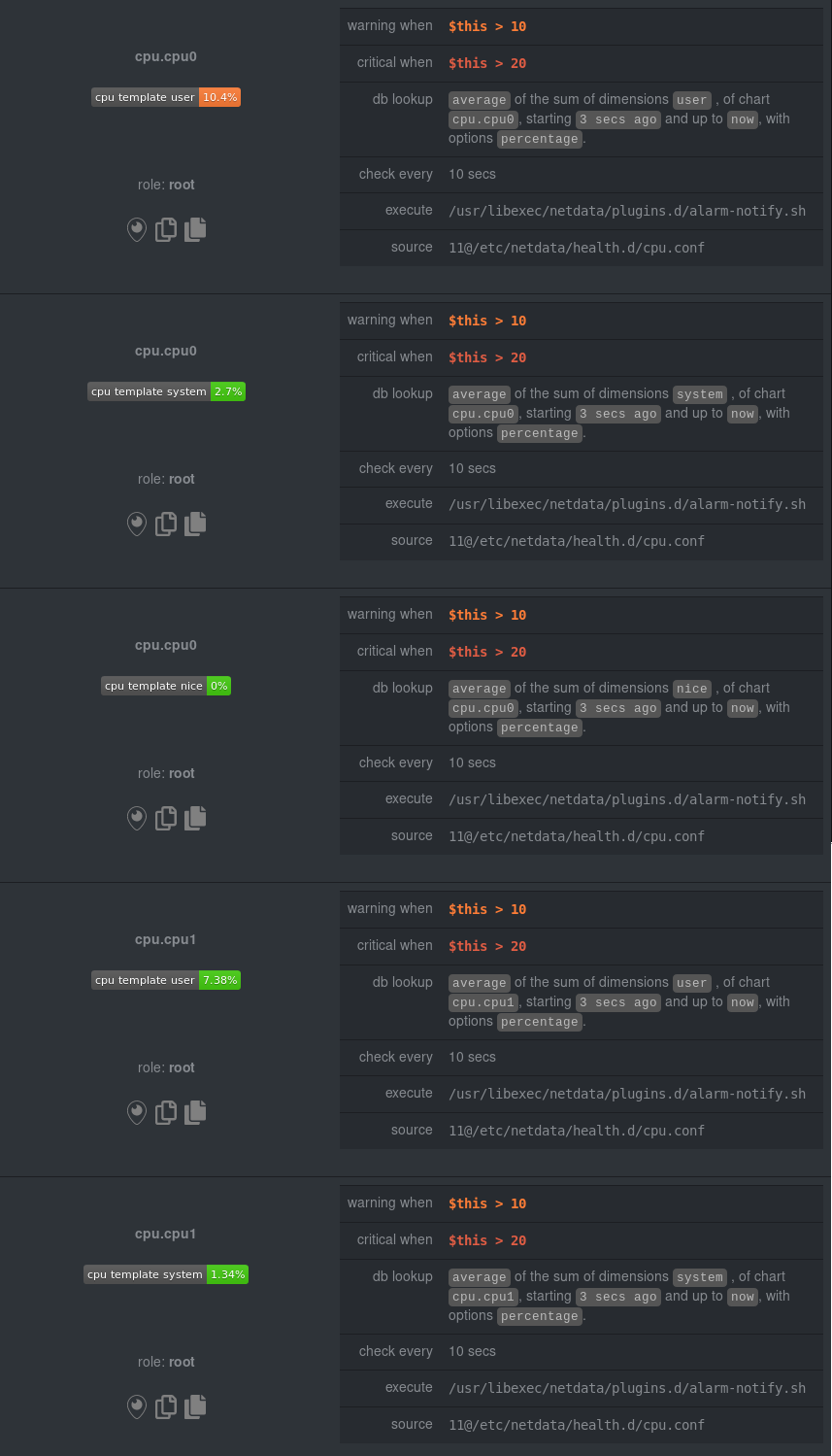
And how just a few of those dimension template-generated alarms look like in the Netdata dashboard.
|
||||
|
||||
|
||||
|
||||
All in all, this single entity creates 36 individual alarms. Much easier than writing 36 separate entities in your
|
||||
health configuration files!
|
||||
|
||||
## What's next?
|
||||
|
||||
We hope you're excited about the possibilities of using dimension templates! Maybe they'll inspire you to build new
|
||||
alarms that will help you better monitor the health of your systems.
|
||||
|
||||
Or, at the very least, simplify your configuration files.
|
||||
|
||||
For information about other advanced features in Netdata's health monitoring toolkit, check out
|
||||
our [health documentation](https://github.com/netdata/netdata/blob/master/health/README.md). And if you have some cool
|
||||
alarms you built using dimension templates,
|
||||
|
||||
|
||||
|
|
@ -3,13 +3,9 @@ title: "Kubernetes monitoring with Netdata: Overview and visualizations"
|
|||
sidebar_label: "Kubernetes monitoring with Netdata: Overview and visualizations"
|
||||
description: "Learn how to navigate Netdata's Kubernetes monitoring features for visualizing the health and performance of a Kubernetes cluster with per-second granularity."
|
||||
image: /img/seo/guides/monitor/kubernetes-k8s-netdata.png
|
||||
author: "Joel Hans"
|
||||
author_title: "Editorial Director, Technical & Educational Resources"
|
||||
author_img: "/img/authors/joel-hans.jpg"
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/kubernetes-k8s-netdata.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides/Monitor"
|
||||
learn_rel_path: "Miscellaneous"
|
||||
-->
|
||||
|
||||
# Kubernetes monitoring with Netdata: Overview and visualizations
|
||||
|
|
|
|||
|
|
@ -3,13 +3,9 @@ title: "LAMP stack monitoring (Linux, Apache, MySQL, PHP) with Netdata"
|
|||
sidebar_label: "LAMP stack monitoring (Linux, Apache, MySQL, PHP) with Netdata"
|
||||
description: "Set up robust LAMP stack monitoring (Linux, Apache, MySQL, PHP) in just a few minutes using a free, open-source monitoring tool that collects metrics every second."
|
||||
image: /img/seo/guides/monitor/lamp-stack.png
|
||||
author: "Joel Hans"
|
||||
author_title: "Editorial Director, Technical & Educational Resources"
|
||||
author_img: "/img/authors/joel-hans.jpg"
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/lamp-stack.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides/Monitor"
|
||||
learn_rel_path: "Miscellaneous"
|
||||
-->
|
||||
import { OneLineInstallWget } from '@site/src/components/OneLineInstall/'
|
||||
|
||||
|
|
|
|||
|
|
@ -5,8 +5,7 @@ description: "Monitor Pi-hole metrics, plus Raspberry Pi system metrics, in minu
|
|||
image: /img/seo/guides/monitor/netdata-pi-hole-raspberry-pi.png
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/pi-hole-raspberry-pi.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides/Monitor"
|
||||
learn_rel_path: "Miscellaneous"
|
||||
-->
|
||||
import { OneLineInstallWget } from '@site/src/components/OneLineInstall/'
|
||||
|
||||
|
|
|
|||
|
|
@ -5,8 +5,7 @@ description: "Tap into Netdata's powerful collectors, with per-second utilizatio
|
|||
image: /img/seo/guides/monitor/process.png
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/process.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides/Monitor"
|
||||
learn_rel_path: "Operations"
|
||||
-->
|
||||
|
||||
# Monitor any process in real-time with Netdata
|
||||
|
|
@ -268,45 +267,4 @@ relevant data.
|
|||
|
||||
`ebpf.plugin` visualizes additional eBPF metrics, which are system-wide and not per-process, under the **eBPF** section.
|
||||
|
||||
## What's next?
|
||||
|
||||
Now that you have `apps_groups.conf` configured correctly, and know where to find per-process visualizations throughout
|
||||
Netdata's ecosystem, you can precisely monitor the health and performance of any process on your node using per-second
|
||||
metrics.
|
||||
|
||||
For even more in-depth troubleshooting, see our guide
|
||||
on [monitoring and debugging applications with eBPF](https://github.com/netdata/netdata/blob/master/docs/guides/troubleshoot/monitor-debug-applications-ebpf.md).
|
||||
|
||||
If the process you're monitoring also has
|
||||
a [supported collector](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md), now is a great time to
|
||||
set
|
||||
that up if it wasn't autodetected. With both process utilization and application-specific metrics, you should have every
|
||||
piece of data needed to discover the root cause of an incident. See
|
||||
the [collectors configuration reference](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md) documentation for details.
|
||||
|
||||
[Create new dashboards](https://github.com/netdata/netdata/blob/master/docs/visualize/create-dashboards.md) in Netdata
|
||||
Cloud using charts from `apps.plugin`,
|
||||
`ebpf.plugin`, and application-specific collectors to build targeted dashboards for monitoring key processes across your
|
||||
infrastructure.
|
||||
|
||||
Try
|
||||
running [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md)
|
||||
on a node that's running the process(es) you're monitoring. Even if nothing is going wrong at the moment, Netdata
|
||||
Cloud's embedded intelligence helps you better understand how a MySQL database, for example, might influence a system's
|
||||
volume of memory page faults. And when an incident is afoot, use Metric Correlations to reduce mean time to resolution (
|
||||
MTTR) and cognitive load.
|
||||
|
||||
If you want more specific metrics from your custom application, check out
|
||||
Netdata's [statsd support](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/README.md). With statd, you can send detailed metrics from your
|
||||
application to Netdata and visualize them with per-second granularity. Netdata's statsd collector works with dozens of
|
||||
[statsd server implementations](https://github.com/etsy/statsd/wiki#client-implementations), which work with most application
|
||||
frameworks.
|
||||
|
||||
### Related reference documentation
|
||||
|
||||
- [Netdata Agent · `apps.plugin`](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md)
|
||||
- [Netdata Agent · `ebpf.plugin`](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md)
|
||||
- [Netdata Agent · Dashboards](https://github.com/netdata/netdata/blob/master/web/README.md#dimensions)
|
||||
- [Netdata Agent · MySQL collector](https://github.com/netdata/go.d.plugin/blob/master/modules/mysql/README.md)
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -3,13 +3,9 @@ title: "Unsupervised anomaly detection for Raspberry Pi monitoring"
|
|||
sidebar_label: "Unsupervised anomaly detection for Raspberry Pi monitoring"
|
||||
description: "Use a low-overhead machine learning algorithm and an open-source monitoring tool to detect anomalous metrics on a Raspberry Pi."
|
||||
image: /img/seo/guides/monitor/raspberry-pi-anomaly-detection.png
|
||||
author: "Andy Maguire"
|
||||
author_title: "Senior Machine Learning Engineer"
|
||||
author_img: "/img/authors/andy-maguire.jpg"
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/raspberry-pi-anomaly-detection.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides/Monitor"
|
||||
learn_rel_path: "Miscellaneous"
|
||||
-->
|
||||
|
||||
We love IoT and edge at Netdata, we also love machine learning. Even better if we can combine the two to ease the pain
|
||||
|
|
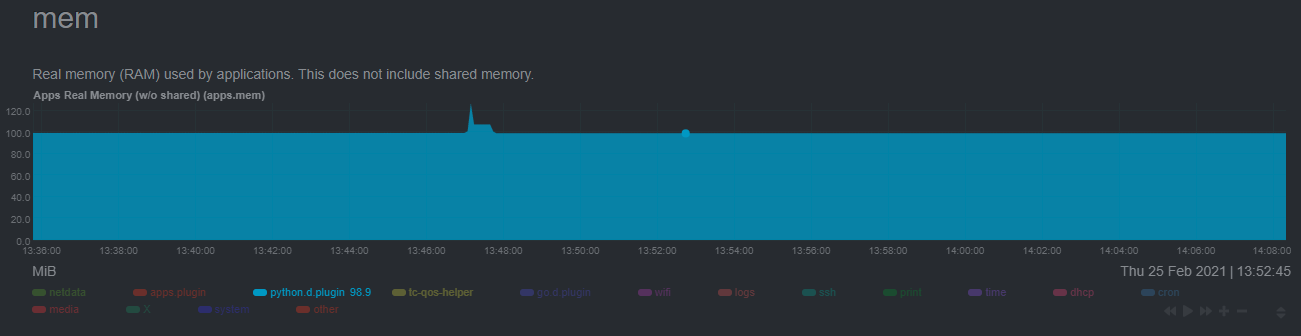
@ -104,26 +100,4 @@ during training. By default, the anomalies collector, along with all other runni
|
|||
|
||||
|
||||
## What's next?
|
||||
|
||||
So, all in all, with a small little bit of extra set up and a small overhead on the Pi itself, the anomalies collector
|
||||
looks like a potentially useful addition to enable unsupervised anomaly detection on your Pi.
|
||||
|
||||
See our two-part guide series for a more complete picture of configuring the anomalies collector, plus some best
|
||||
practices on using the charts it automatically generates:
|
||||
|
||||
- [_Detect anomalies in systems and applications_](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection-python.md)
|
||||
- [_Monitor and visualize anomalies with Netdata_](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/visualize-monitor-anomalies.md)
|
||||
|
||||
If you're using your Raspberry Pi for other purposes, like blocking ads/trackers with Pi-hole, check out our companions
|
||||
Pi guide: [_Monitor Pi-hole (and a Raspberry Pi) with Netdata_](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/pi-hole-raspberry-pi.md).
|
||||
|
||||
Once you've had a chance to give unsupervised anomaly detection a go, share your use cases and let us know of any
|
||||
feedback on our [community forum](https://community.netdata.cloud/t/anomalies-collector-feedback-megathread/767).
|
||||
|
||||
### Related reference documentation
|
||||
|
||||
- [Netdata Agent · Get Netdata](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md)
|
||||
- [Netdata Agent · Anomalies collector](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/anomalies/README.md)
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -1,94 +0,0 @@
|
|||
<!--
|
||||
title: "Stop notifications for individual alarms"
|
||||
sidebar_label: "Stop notifications for individual alarms"
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/stop-notifications-alarms.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides/Monitor"
|
||||
-->
|
||||
|
||||
# Stop notifications for individual alarms
|
||||
|
||||
In this short tutorial, you'll learn how to stop notifications for individual alarms in Netdata's health
|
||||
monitoring system. We also refer to this process as _silencing_ the alarm.
|
||||
|
||||
Why silence alarms? We designed Netdata's pre-configured alarms for production systems, so they might not be
|
||||
relevant if you run Netdata on your laptop or a small virtual server. If they're not helpful, they can be a distraction
|
||||
to real issues with health and performance.
|
||||
|
||||
Silencing individual alarms is an excellent solution for situations where you're not interested in seeing a specific
|
||||
alarm but don't want to disable a [notification system](https://github.com/netdata/netdata/blob/master/health/notifications/README.md) entirely.
|
||||
|
||||
## Find the alarm configuration file
|
||||
|
||||
To silence an alarm, you need to know where to find its configuration file.
|
||||
|
||||
Let's use the `system.cpu` chart as an example. It's the first chart you'll see on most Netdata dashboards.
|
||||
|
||||
To figure out which file you need to edit, open up Netdata's dashboard and, click the **Alarms** button at the top
|
||||
of the dashboard, followed by clicking on the **All** tab.
|
||||
|
||||
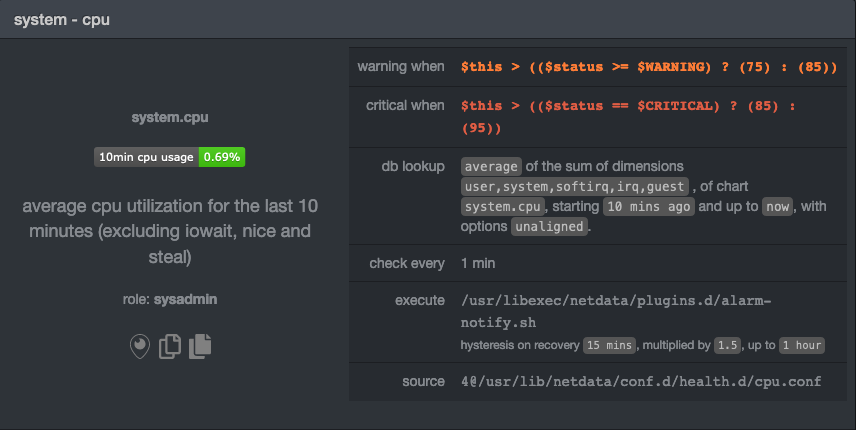
In this example, we're looking for the `system - cpu` entity, which, when opened, looks like this:
|
||||
|
||||
|
||||
|
||||
In the `source` row, you see that this chart is getting its configuration from
|
||||
`4@/usr/lib/netdata/conf.d/health.d/cpu.conf`. The relevant part of begins at `health.d`: `health.d/cpu.conf`. That's
|
||||
the file you need to edit if you want to silence this alarm.
|
||||
|
||||
For more information about editing or referencing health configuration files on your system, see the [Configure health alarms](https://github.com/netdata/netdata/blob/master/docs/monitor/configure-alarms.md#edit-health-configuration-files) and the [Health configuration reference](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) sections of our documentation.
|
||||
|
||||
## Edit the file to enable silencing
|
||||
|
||||
To edit `health.d/cpu.conf`, use `edit-config` from inside of your Netdata configuration directory.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata/ # Replace with your Netdata configuration directory, if not /etc/netdata/
|
||||
./edit-config health.d/cpu.conf
|
||||
```
|
||||
|
||||
> You may need to use `sudo` or another method of elevating your privileges.
|
||||
|
||||
The beginning of the file looks like this:
|
||||
|
||||
```yaml
|
||||
template: 10min_cpu_usage
|
||||
on: system.cpu
|
||||
os: linux
|
||||
hosts: *
|
||||
lookup: average -10m unaligned of user,system,softirq,irq,guest
|
||||
units: %
|
||||
every: 1m
|
||||
warn: $this > (($status >= $WARNING) ? (75) : (85))
|
||||
crit: $this > (($status == $CRITICAL) ? (85) : (95))
|
||||
delay: down 15m multiplier 1.5 max 1h
|
||||
info: average cpu utilization for the last 10 minutes (excluding iowait, nice and steal)
|
||||
to: sysadmin
|
||||
```
|
||||
|
||||
To silence this alarm, change `sysadmin` to `silent`.
|
||||
|
||||
```yaml
|
||||
to: silent
|
||||
```
|
||||
|
||||
Use one of the available [methods](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#reload-health-configuration) to reload your health configuration and ensure you get no more notifications about that alarm.
|
||||
|
||||
You can add `to: silent` to any alarm you'd rather not bother you with notifications.
|
||||
|
||||
## What's next?
|
||||
|
||||
You should now know the fundamentals behind silencing any individual alarm in Netdata.
|
||||
|
||||
To learn about _all_ of Netdata's health configuration possibilities, visit the [health reference
|
||||
guide](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md), or check out other [tutorials on health monitoring](https://github.com/netdata/netdata/blob/master/health/README.md#guides).
|
||||
|
||||
Or, take better control over how you get notified about alarms via the [notification
|
||||
system](https://github.com/netdata/netdata/blob/master/health/notifications/README.md).
|
||||
|
||||
You can also use Netdata's [Health Management API](https://github.com/netdata/netdata/blob/master/web/api/health/README.md#health-management-api) to control health
|
||||
checks and notifications while Netdata runs. With this API, you can disable health checks during a maintenance window or
|
||||
backup process, for example.
|
||||
|
||||
|
||||
|
|
@ -1,146 +0,0 @@
|
|||
<!--
|
||||
title: "Monitor and visualize anomalies with Netdata (part 2)"
|
||||
sidebar_label: "Monitor and visualize anomalies with Netdata (part 2)"
|
||||
description: "Using unsupervised anomaly detection and machine learning, get notified "
|
||||
image: /img/seo/guides/monitor/visualize-monitor-anomalies.png
|
||||
author: "Joel Hans"
|
||||
author_title: "Editorial Director, Technical & Educational Resources"
|
||||
author_img: "/img/authors/joel-hans.jpg"
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/visualize-monitor-anomalies.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides/Monitor"
|
||||
-->
|
||||
|
||||
Welcome to part 2 of our series of guides on using _unsupervised anomaly detection_ to detect issues with your systems,
|
||||
containers, and applications using the open-source Netdata Agent. For an introduction to detecting anomalies and
|
||||
monitoring associated metrics, see [part 1](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection-python.md), which covers prerequisites and
|
||||
configuration basics.
|
||||
|
||||
With anomaly detection in the Netdata Agent set up, you will now want to visualize and monitor which charts have
|
||||
anomalous data, when, and where to look next.
|
||||
|
||||
> 💡 In certain cases, the anomalies collector doesn't start immediately after restarting the Netdata Agent. If this
|
||||
> happens, you won't see the dashboard section or the relevant [charts](#visualize-anomalies-in-charts) right away. Wait
|
||||
> a minute or two, refresh, and look again. If the anomalies charts and alarms are still not present, investigate the
|
||||
> error log with `less /var/log/netdata/error.log | grep anomalies`.
|
||||
|
||||
## Test anomaly detection
|
||||
|
||||
Time to see the Netdata Agent's unsupervised anomaly detection in action. To trigger anomalies on the Nginx web server,
|
||||
use `ab`, otherwise known as [Apache Bench](https://httpd.apache.org/docs/2.4/programs/ab.html). Despite its name, it
|
||||
works just as well with Nginx web servers. Install it on Ubuntu/Debian systems with `sudo apt install apache2-utils`.
|
||||
|
||||
> 💡 If you haven't followed the guide's example of using Nginx, an easy way to test anomaly detection on your node is
|
||||
> to use the `stress-ng` command, which is available on most Linux distributions. Run `stress-ng --cpu 0` to create CPU
|
||||
> stress or `stress-ng --vm 0` for RAM stress. Each test will cause some "collateral damage," in that you may see CPU
|
||||
> utilization rise when running the RAM test, and vice versa.
|
||||
|
||||
The following test creates a minimum of 10,000,000 requests for Nginx to handle, with a maximum of 10 at any given time,
|
||||
with a run time of 60 seconds. If your system can handle those 10,000,000 in less than 60 seconds, `ab` will keep
|
||||
sending requests until the timer runs out.
|
||||
|
||||
```bash
|
||||
ab -k -c 10 -t 60 -n 10000000 http://127.0.0.1/
|
||||
```
|
||||
|
||||
Let's see how Netdata detects this anomalous behavior and propagates information to you through preconfigured alarms and
|
||||
dashboards that automatically organize anomaly detection metrics into meaningful charts to help you begin root cause
|
||||
analysis (RCA).
|
||||
|
||||
## Monitor anomalies with alarms
|
||||
|
||||
The anomalies collector creates two "classes" of alarms for each chart captured by the `charts_regex` setting. All these
|
||||
alarms are preconfigured based on your [configuration in
|
||||
`anomalies.conf`](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection-python.md#configure-the-anomalies-collector). With the `charts_regex`
|
||||
and `charts_to_exclude` settings from [part 1](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection-python.md) of this guide series, the
|
||||
Netdata Agent creates 32 alarms driven by unsupervised anomaly detection.
|
||||
|
||||
The first class triggers warning alarms when the average anomaly probability for a given chart has stayed above 50% for
|
||||
at least the last two minutes.
|
||||
|
||||
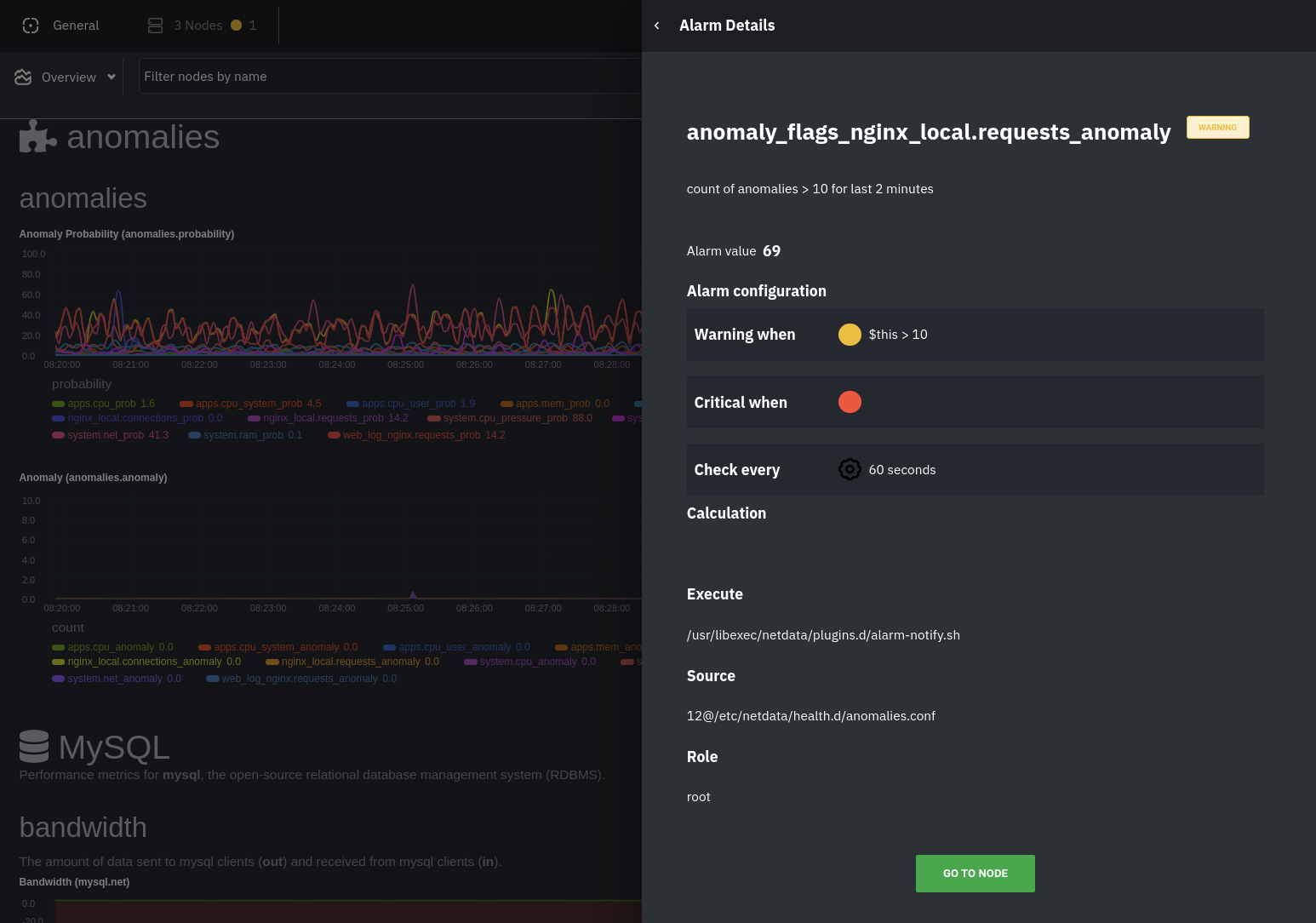
|
||||
|
||||
The second class triggers warning alarms when the number of anomalies in the last two minutes hits 10 or higher.
|
||||
|
||||
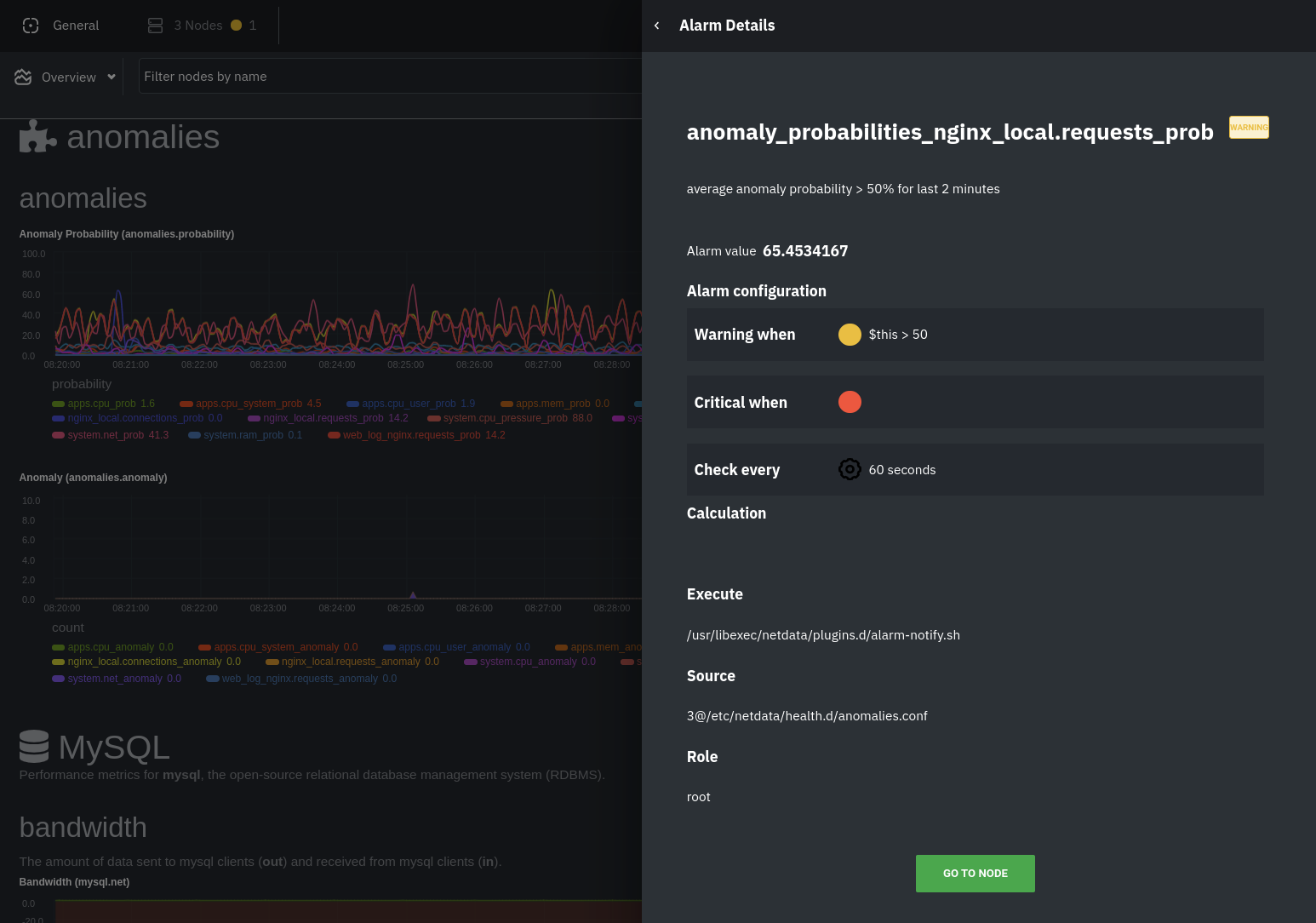
|
||||
|
||||
If you see either of these alarms in Netdata Cloud, the local Agent dashboard, or on your preferred notification
|
||||
platform, it's a safe bet that the node's current metrics have deviated from normal. That doesn't necessarily mean
|
||||
there's a full-blown incident, depending on what application/service you're using anomaly detection on, but it's worth
|
||||
further investigation.
|
||||
|
||||
As you use the anomalies collector, you may find that the default settings provide too many or too few genuine alarms.
|
||||
In this case, [configure the alarm](https://github.com/netdata/netdata/blob/master/docs/monitor/configure-alarms.md) with `sudo ./edit-config
|
||||
health.d/anomalies.conf`. Take a look at the `lookup` line syntax in the [health
|
||||
reference](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alarm-line-lookup) to understand how the anomalies collector automatically creates
|
||||
alarms for any dimension on the `anomalies_local.probability` and `anomalies_local.anomaly` charts.
|
||||
|
||||
## Visualize anomalies in charts
|
||||
|
||||
In either [Netdata Cloud](https://app.netdata.cloud) or the local Agent dashboard at `http://NODE:19999`, click on the
|
||||
**Anomalies** [section](https://github.com/netdata/netdata/blob/master/web/gui/README.md#sections) to see the pair of anomaly detection charts, which are
|
||||
preconfigured to visualize per-second anomaly metrics based on your [configuration in
|
||||
`anomalies.conf`](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection-python.md#configure-the-anomalies-collector).
|
||||
|
||||
These charts have the contexts `anomalies.probability` and `anomalies.anomaly`. Together, these charts
|
||||
create meaningful visualizations for immediately recognizing not only that something is going wrong on your node, but
|
||||
give context as to where to look next.
|
||||
|
||||
The `anomalies_local.probability` chart shows the probability that the latest observed data is anomalous, based on the
|
||||
trained model. The `anomalies_local.anomaly` chart visualizes 0→1 predictions based on whether the latest observed
|
||||
data is anomalous based on the trained model. Both charts share the same dimensions, which you configured via
|
||||
`charts_regex` and `charts_to_exclude` in [part 1](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection-python.md).
|
||||
|
||||
In other words, the `probability` chart shows the amplitude of the anomaly, whereas the `anomaly` chart provides quick
|
||||
yes/no context.
|
||||
|
||||
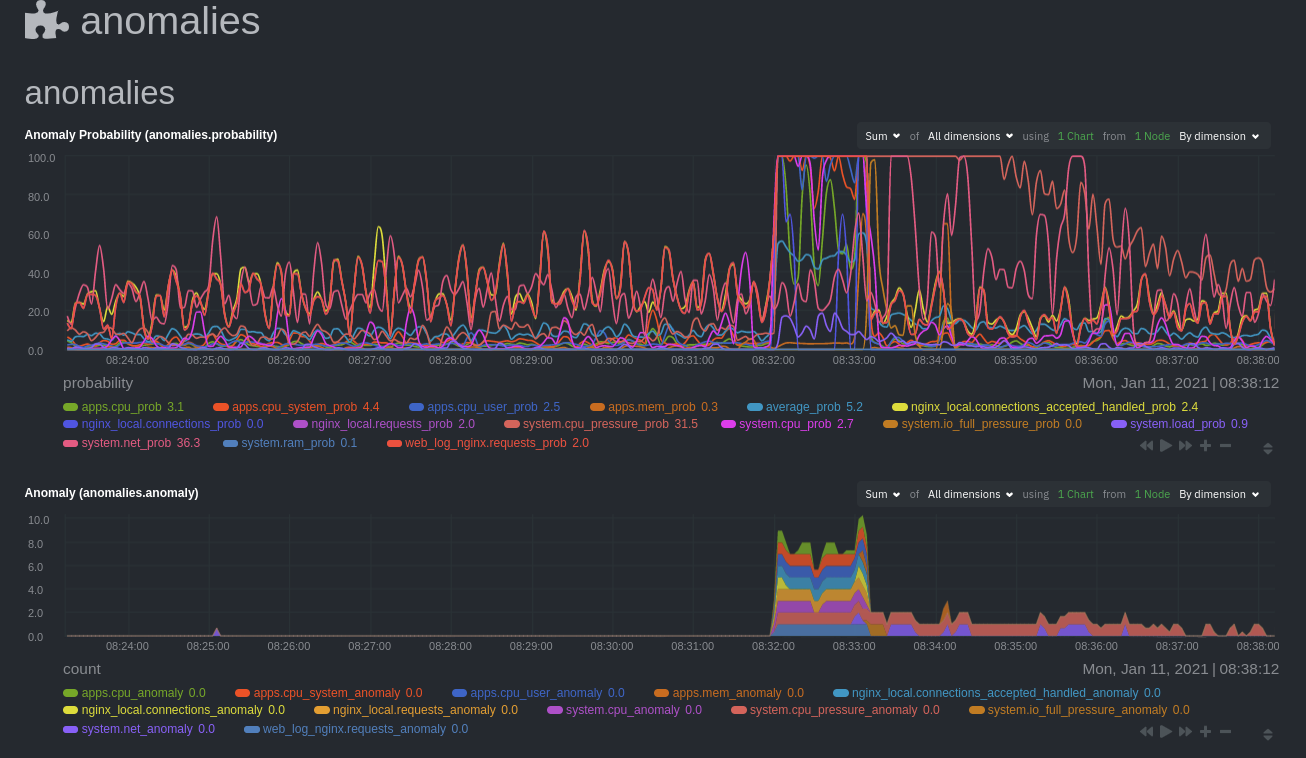
|
||||
|
||||
Before `08:32:00`, both charts show little in the way of verified anomalies. Based on the metrics the anomalies
|
||||
collector has trained on, a certain percentage of anomaly probability score is normal, as seen in the
|
||||
`web_log_nginx_requests_prob` dimension and a few others. What you're looking for is large deviations from the "noise"
|
||||
in the `anomalies.probability` chart, or any increments to the `anomalies.anomaly` chart.
|
||||
|
||||
Unsurprisingly, the stress test that began at `08:32:00` caused significant changes to these charts. The three
|
||||
dimensions that immediately shot to 100% anomaly probability, and remained there during the test, were
|
||||
`web_log_nginx.requests_prob`, `nginx_local.connections_accepted_handled_prob`, and `system.cpu_pressure_prob`.
|
||||
|
||||
## Build an anomaly detection dashboard
|
||||
|
||||
[Netdata Cloud](https://app.netdata.cloud) features a drag-and-drop [dashboard
|
||||
editor](https://github.com/netdata/netdata/blob/master/docs/visualize/create-dashboards.md) that helps you create entirely new dashboards with charts targeted for
|
||||
your specific applications.
|
||||
|
||||
For example, here's a dashboard designed for visualizing anomalies present in an Nginx web server, including
|
||||
documentation about why the dashboard exists and where to look next based on what you're seeing:
|
||||
|
||||
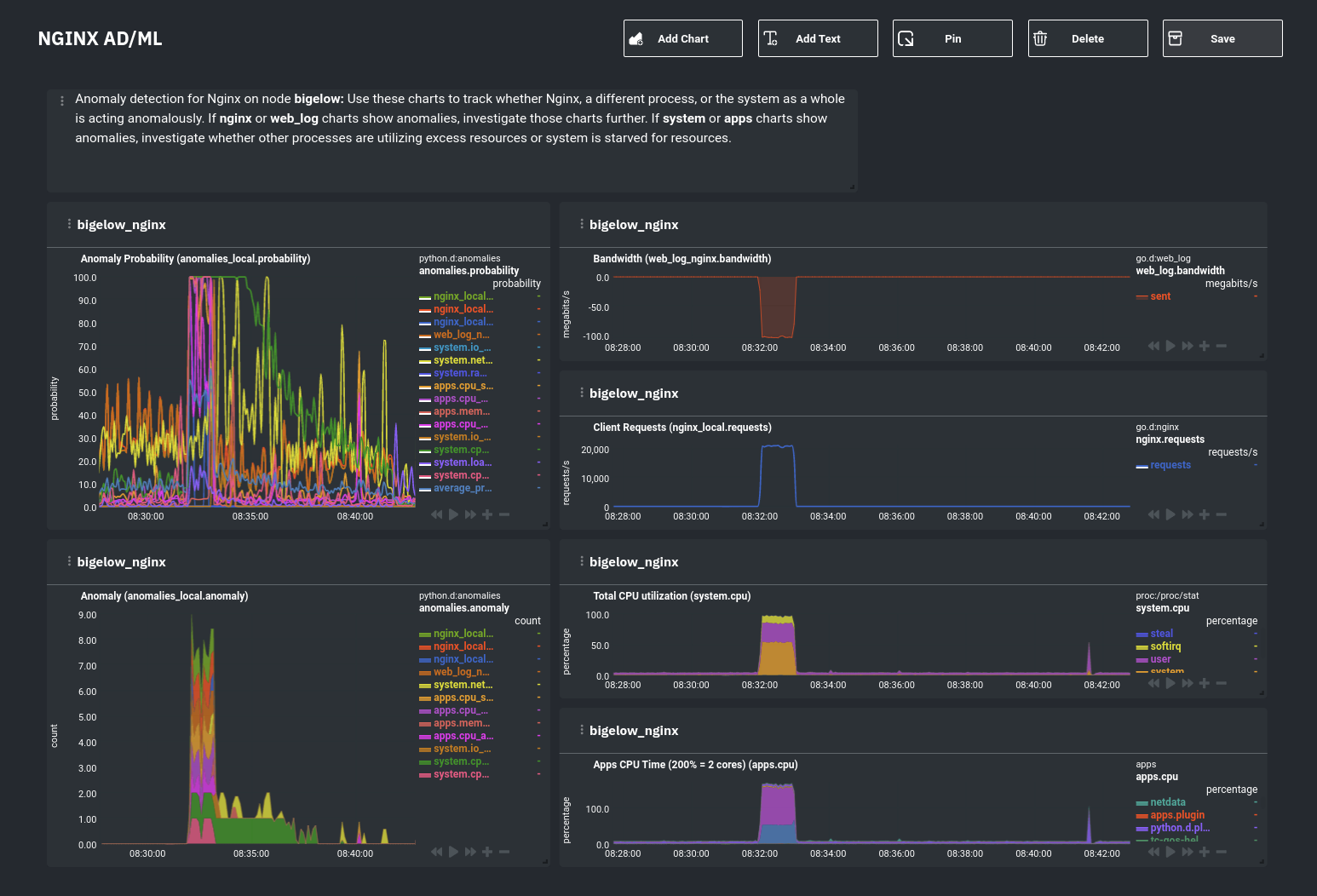
|
||||
|
||||
Use the anomaly charts for instant visual identification of potential anomalies, and then Nginx-specific charts, in the
|
||||
right column, to validate whether the probability and anomaly counters are showing a valid incident worth further
|
||||
investigation using [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md) to narrow
|
||||
the dashboard into only the charts relevant to what you're seeing from the anomalies collector.
|
||||
|
||||
## What's next?
|
||||
|
||||
Between this guide and [part 1](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection-python.md), which covered setup and configuration, you
|
||||
now have a fundamental understanding of how unsupervised anomaly detection in Netdata works, from root cause to alarms
|
||||
to preconfigured or custom dashboards.
|
||||
|
||||
We'd love to hear your feedback on the anomalies collector. Hop over to the [community
|
||||
forum](https://community.netdata.cloud/t/anomalies-collector-feedback-megathread/767), and let us know if you're already getting value from
|
||||
unsupervised anomaly detection, or would like to see something added to it. You might even post a custom configuration
|
||||
that works well for monitoring some other popular application, like MySQL, PostgreSQL, Redis, or anything else we
|
||||
[support through collectors](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md).
|
||||
|
||||
### Related reference documentation
|
||||
|
||||
- [Netdata Agent · Anomalies collector](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/anomalies/README.md)
|
||||
- [Netdata Cloud · Build new dashboards](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md)
|
||||
|
||||
|
||||
|
|
@ -5,8 +5,7 @@ description: "Use Netdata's built-in eBPF metrics collector to monitor, troubles
|
|||
image: /img/seo/guides/troubleshoot/monitor-debug-applications-ebpf.png
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/troubleshoot/monitor-debug-applications-ebpf.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides/Troubleshoot"
|
||||
learn_rel_path: "Operations"
|
||||
-->
|
||||
|
||||
# Monitor, troubleshoot, and debug applications with eBPF metrics
|
||||
|
|
@ -251,23 +250,5 @@ systems.
|
|||
Now that you can see eBPF metrics in Netdata Cloud, you can [invite your
|
||||
team](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/invite-your-team.md) and share your findings with others.
|
||||
|
||||
## What's next?
|
||||
|
||||
Debugging and troubleshooting an application takes a special combination of practice, experience, and sheer luck. With
|
||||
Netdata's eBPF metrics to back you up, you can rest assured that you see every minute detail of how your application
|
||||
interacts with the Linux kernel.
|
||||
|
||||
If you're still trying to wrap your head around what we offer, be sure to read up on our accompanying documentation and
|
||||
other resources on eBPF monitoring with Netdata:
|
||||
|
||||
- [eBPF collector](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md)
|
||||
- [eBPF's integration with `apps.plugin`](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md#integration-with-ebpf)
|
||||
- [Linux eBPF monitoring with Netdata](https://www.netdata.cloud/blog/linux-ebpf-monitoring-with-netdata/)
|
||||
|
||||
The scenarios described above are just the beginning when it comes to troubleshooting with eBPF metrics. We're excited
|
||||
to explore others and see what our community dreams up. If you have other use cases, whether simulated or real-world,
|
||||
we'd love to hear them: [info@netdata.cloud](mailto:info@netdata.cloud).
|
||||
|
||||
Happy troubleshooting!
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ description: "A simple guide to troubleshoot occurrences where the Agent is show
|
|||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/troubleshoot/troubleshooting-agent-with-cloud-connection.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides/Troubleshoot"
|
||||
learn_rel_path: "Operations"
|
||||
-->
|
||||
|
||||
# Troubleshoot Agent-Cloud connectivity issues
|
||||
|
|
|
|||
|
|
@ -3,8 +3,7 @@ title: "Use host labels to organize systems, metrics, and alarms"
|
|||
sidebar_label: "Use host labels to organize systems, metrics, and alarms"
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/using-host-labels.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides"
|
||||
learn_rel_path: "Operations"
|
||||
-->
|
||||
|
||||
# Use host labels to organize systems, metrics, and alarms
|
||||
|
|
@ -189,28 +188,4 @@ send automatic labels = yes
|
|||
By applying labels to exported metrics, you can more easily parse historical metrics with the labels applied. To learn
|
||||
more about exporting, read the [documentation](https://github.com/netdata/netdata/blob/master/exporting/README.md).
|
||||
|
||||
## What's next?
|
||||
|
||||
Host labels are a brand-new feature to Netdata, and yet they've already propagated deeply into some of its core
|
||||
functionality. We're just getting started with labels, and will keep the community apprised of additional functionality
|
||||
as it's made available. You can also track [issue #6503](https://github.com/netdata/netdata/issues/6503), which is where
|
||||
the Netdata team first kicked off this work.
|
||||
|
||||
It should be noted that while the Netdata dashboard does not expose either user-configured or automatic host labels, API
|
||||
queries _do_ showcase this information. As always, we recommend you secure Netdata
|
||||
|
||||
- [Expose Netdata only in a private LAN](https://github.com/netdata/netdata/blob/master/docs/netdata-security.md#expose-netdata-only-in-a-private-lan)
|
||||
- [Enable TLS/SSL for web/API requests](https://github.com/netdata/netdata/blob/master/web/server/README.md#enabling-tls-support)
|
||||
- Put Netdata behind a proxy
|
||||
- [Use an authenticating web server in proxy
|
||||
mode](https://github.com/netdata/netdata/blob/master/docs/netdata-security.md#use-an-authenticating-web-server-in-proxy-mode)
|
||||
- [Nginx proxy](https://github.com/netdata/netdata/blob/master/docs/Running-behind-nginx.md)
|
||||
- [Apache proxy](https://github.com/netdata/netdata/blob/master/docs/Running-behind-apache.md)
|
||||
- [Lighttpd](https://github.com/netdata/netdata/blob/master/docs/Running-behind-lighttpd.md)
|
||||
- [Caddy](https://github.com/netdata/netdata/blob/master/docs/Running-behind-caddy.md)
|
||||
|
||||
If you have issues or questions around using host labels, don't hesitate to [file an
|
||||
issue](https://github.com/netdata/netdata/issues/new?assignees=&labels=bug%2Cneeds+triage&template=BUG_REPORT.yml) on GitHub. We're
|
||||
excited to make host labels even more valuable to our users, which we can only do with your input.
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@ custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/metrics-st
|
|||
sidebar_label: "Enable streaming between nodes"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Setup"
|
||||
learn_rel_path: "Configuration"
|
||||
-->
|
||||
|
||||
# Enable streaming between nodes
|
||||
|
|
|
|||
|
|
@ -1,152 +0,0 @@
|
|||
<!--
|
||||
title: "Configure health alarms"
|
||||
description: "Netdata's health monitoring watchdog is incredibly adaptable to your infrastructure's unique needs, with configurable health alarms."
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/monitor/configure-alarms.md"
|
||||
sidebar_label: "Configure health alarms"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Setup"
|
||||
-->
|
||||
|
||||
# Configure health alarms
|
||||
|
||||
Netdata's health watchdog is highly configurable, with support for dynamic thresholds, hysteresis, alarm templates, and
|
||||
more. You can tweak any of the existing alarms based on your infrastructure's topology or specific monitoring needs, or
|
||||
create new entities.
|
||||
|
||||
You can use health alarms in conjunction with any of Netdata's [collectors](https://github.com/netdata/netdata/blob/master/collectors/README.md) (see
|
||||
the [supported collector list](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md)) to monitor the health of your systems, containers, and
|
||||
applications in real time.
|
||||
|
||||
While you can see active alarms both on the local dashboard and Netdata Cloud, all health alarms are configured _per
|
||||
node_ via individual Netdata Agents. If you want to deploy a new alarm across your
|
||||
[infrastructure](https://github.com/netdata/netdata/blob/master/docs/quickstart/infrastructure.md), you must configure each node with the same health configuration
|
||||
files.
|
||||
|
||||
## Edit health configuration files
|
||||
|
||||
All of Netdata's [health configuration files](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#health-configuration-files) are in Netdata's config
|
||||
directory, inside the `health.d/` directory. Navigate to your [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md) and
|
||||
use `edit-config` to make changes to any of these files.
|
||||
|
||||
For example, to edit the `cpu.conf` health configuration file, run:
|
||||
|
||||
```bash
|
||||
sudo ./edit-config health.d/cpu.conf
|
||||
```
|
||||
|
||||
Each health configuration file contains one or more health _entities_, which always begin with `alarm:` or `template:`.
|
||||
For example, here is the first health entity in `health.d/cpu.conf`:
|
||||
|
||||
```yaml
|
||||
template: 10min_cpu_usage
|
||||
on: system.cpu
|
||||
os: linux
|
||||
hosts: *
|
||||
lookup: average -10m unaligned of user,system,softirq,irq,guest
|
||||
units: %
|
||||
every: 1m
|
||||
warn: $this > (($status >= $WARNING) ? (75) : (85))
|
||||
crit: $this > (($status == $CRITICAL) ? (85) : (95))
|
||||
delay: down 15m multiplier 1.5 max 1h
|
||||
info: average cpu utilization for the last 10 minutes (excluding iowait, nice and steal)
|
||||
to: sysadmin
|
||||
```
|
||||
|
||||
To tune this alarm to trigger warning and critical alarms at a lower CPU utilization, change the `warn` and `crit` lines
|
||||
to the values of your choosing. For example:
|
||||
|
||||
```yaml
|
||||
warn: $this > (($status >= $WARNING) ? (60) : (75))
|
||||
crit: $this > (($status == $CRITICAL) ? (75) : (85))
|
||||
```
|
||||
|
||||
Save the file and [reload Netdata's health configuration](#reload-health-configuration) to make your changes live.
|
||||
|
||||
### Silence an individual alarm
|
||||
|
||||
Instead of disabling an alarm altogether, or even disabling _all_ alarms, you can silence individual alarms by changing
|
||||
one line in a given health entity. To silence any single alarm, change the `to:` line in its entity to `silent`.
|
||||
|
||||
```yaml
|
||||
to: silent
|
||||
```
|
||||
|
||||
## Write a new health entity
|
||||
|
||||
While tuning existing alarms may work in some cases, you may need to write entirely new health entities based on how
|
||||
your systems, containers, and applications work.
|
||||
|
||||
Read Netdata's [health reference](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#health-entity-reference) for a full listing of the format,
|
||||
syntax, and functionality of health entities.
|
||||
|
||||
To write a new health entity into a new file, navigate to your [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md),
|
||||
then use `touch` to create a new file in the `health.d/` directory. Use `edit-config` to start editing the file.
|
||||
|
||||
As an example, let's create a `ram-usage.conf` file.
|
||||
|
||||
```bash
|
||||
sudo touch health.d/ram-usage.conf
|
||||
sudo ./edit-config health.d/ram-usage.conf
|
||||
```
|
||||
|
||||
For example, here is a health entity that triggers a warning alarm when a node's RAM usage rises above 80%, and a
|
||||
critical alarm above 90%:
|
||||
|
||||
```yaml
|
||||
alarm: ram_usage
|
||||
on: system.ram
|
||||
lookup: average -1m percentage of used
|
||||
units: %
|
||||
every: 1m
|
||||
warn: $this > 80
|
||||
crit: $this > 90
|
||||
info: The percentage of RAM being used by the system.
|
||||
```
|
||||
|
||||
Let's look into each of the lines to see how they create a working health entity.
|
||||
|
||||
- `alarm`: The name for your new entity. The name needs to follow these requirements:
|
||||
- Any alphabet letter or number.
|
||||
- The symbols `.` and `_`.
|
||||
- Cannot be `chart name`, `dimension name`, `family name`, or `chart variable names`.
|
||||
- `on`: Which chart the entity listens to.
|
||||
- `lookup`: Which metrics the alarm monitors, the duration of time to monitor, and how to process the metrics into a
|
||||
usable format.
|
||||
- `average`: Calculate the average of all the metrics collected.
|
||||
- `-1m`: Use metrics from 1 minute ago until now to calculate that average.
|
||||
- `percentage`: Clarify that we're calculating a percentage of RAM usage.
|
||||
- `of used`: Specify which dimension (`used`) on the `system.ram` chart you want to monitor with this entity.
|
||||
- `units`: Use percentages rather than absolute units.
|
||||
- `every`: How often to perform the `lookup` calculation to decide whether or not to trigger this alarm.
|
||||
- `warn`/`crit`: The value at which Netdata should trigger a warning or critical alarm. This example uses simple
|
||||
syntax, but most pre-configured health entities use
|
||||
[hysteresis](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#special-use-of-the-conditional-operator) to avoid superfluous notifications.
|
||||
- `info`: A description of the alarm, which will appear in the dashboard and notifications.
|
||||
|
||||
In human-readable format:
|
||||
|
||||
> This health entity, named **ram_usage**, watches the **system.ram** chart. It looks up the last **1 minute** of
|
||||
> metrics from the **used** dimension and calculates the **average** of all those metrics in a **percentage** format,
|
||||
> using a **% unit**. The entity performs this lookup **every minute**.
|
||||
>
|
||||
> If the average RAM usage percentage over the last 1 minute is **more than 80%**, the entity triggers a warning alarm.
|
||||
> If the usage is **more than 90%**, the entity triggers a critical alarm.
|
||||
|
||||
When you finish writing this new health entity, [reload Netdata's health configuration](#reload-health-configuration) to
|
||||
see it live on the local dashboard or Netdata Cloud.
|
||||
|
||||
## Reload health configuration
|
||||
|
||||
To make any changes to your health configuration live, you must reload Netdata's health monitoring system. To do that
|
||||
without restarting all of Netdata, run `netdatacli reload-health` or `killall -USR2 netdata`.
|
||||
|
||||
## What's next?
|
||||
|
||||
With your health entities configured properly, it's time to [enable
|
||||
notifications](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md) to get notified whenever a node reaches a warning or critical
|
||||
state.
|
||||
|
||||
To build complex, dynamic alarms, read our guide on [dimension templates](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/dimension-templates.md).
|
||||
|
||||
|
||||
|
|
@ -2,9 +2,8 @@
|
|||
title: "Netdata for IoT"
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/netdata-for-IoT.md
|
||||
sidebar_label: "Netdata for IoT"
|
||||
learn_status: "Unpublished"
|
||||
learn_topic_type: "References"
|
||||
learn_rel_path: "Guides"
|
||||
learn_status: "Published"
|
||||
learn_rel_path: "Miscellaneous"
|
||||
-->
|
||||
|
||||
# Netdata for IoT
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/netdata-sec
|
|||
sidebar_label: "Security Design"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Setup"
|
||||
learn_rel_path: "Configuration"
|
||||
sidebar_position: 20
|
||||
-->
|
||||
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/store/chan
|
|||
sidebar_label: "Change how long Netdata stores metrics"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Setup"
|
||||
learn_rel_path: "Configuration"
|
||||
-->
|
||||
|
||||
# Change how long Netdata stores metrics
|
||||
|
|
|
|||
|
|
@ -1,33 +1,160 @@
|
|||
<!--
|
||||
title: "Health configuration reference"
|
||||
title: "Configure agent alerts"
|
||||
sidebar_label: "Health"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/REFERENCE.md"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Operations/Alerts"
|
||||
learn_rel_path: "Configuration"
|
||||
-->
|
||||
|
||||
# Health configuration reference
|
||||
# Configure agent alerts
|
||||
|
||||
Welcome to the health configuration reference.
|
||||
Netdata's health watchdog is highly configurable, with support for dynamic thresholds, hysteresis, alarm templates, and
|
||||
more. You can tweak any of the existing alarms based on your infrastructure's topology or specific monitoring needs, or
|
||||
create new entities.
|
||||
|
||||
This guide contains information about editing health configuration files to tweak existing alarms or create new health
|
||||
entities that are customized to the needs of your infrastructure.
|
||||
You can use health alarms in conjunction with any of Netdata's [collectors](https://github.com/netdata/netdata/blob/master/collectors/README.md) (see
|
||||
the [supported collector list](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md)) to monitor the health of your systems, containers, and
|
||||
applications in real time.
|
||||
|
||||
To learn the basics of locating and editing health configuration files, see the [Configure health alarms](https://github.com/netdata/netdata/blob/master/docs/monitor/configure-alarms.md) documentation.
|
||||
While you can see active alarms both on the local dashboard and Netdata Cloud, all health alarms are configured _per
|
||||
node_ via individual Netdata Agents. If you want to deploy a new alarm across your
|
||||
[infrastructure](https://github.com/netdata/netdata/blob/master/docs/quickstart/infrastructure.md), you must configure each node with the same health configuration
|
||||
files.
|
||||
|
||||
## Health configuration files
|
||||
## Edit health configuration files
|
||||
|
||||
You can configure the Agent's health watchdog service by editing files in two locations:
|
||||
|
||||
- The `[health]` section in `netdata.conf`. By editing the daemon's behavior, you can disable health monitoring
|
||||
altogether, run health checks more or less often, and more. See [daemon
|
||||
configuration](https://github.com/netdata/netdata/blob/master/daemon/config/README.md#health-section-options) for a table of all the available settings, their
|
||||
default values, and what they control.
|
||||
altogether, run health checks more or less often, and more. See
|
||||
[daemon configuration](https://github.com/netdata/netdata/blob/master/daemon/config/README.md#health-section-options) for a table of
|
||||
all the available settings, their default values, and what they control.
|
||||
|
||||
- The individual `.conf` files in `health.d/`. These health entity files are organized by the type of metric they are
|
||||
performing calculations on or their associated collector. You should edit these files using the `edit-config`
|
||||
script. For example: `sudo ./edit-config health.d/cpu.conf`.
|
||||
|
||||
Navigate to your [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md) and
|
||||
use `edit-config` to make changes to any of these files.
|
||||
|
||||
For example, to edit the `cpu.conf` health configuration file, run:
|
||||
|
||||
```bash
|
||||
sudo ./edit-config health.d/cpu.conf
|
||||
```
|
||||
|
||||
Each health configuration file contains one or more health _entities_, which always begin with `alarm:` or `template:`.
|
||||
For example, here is the first health entity in `health.d/cpu.conf`:
|
||||
|
||||
```yaml
|
||||
template: 10min_cpu_usage
|
||||
on: system.cpu
|
||||
os: linux
|
||||
hosts: *
|
||||
lookup: average -10m unaligned of user,system,softirq,irq,guest
|
||||
units: %
|
||||
every: 1m
|
||||
warn: $this > (($status >= $WARNING) ? (75) : (85))
|
||||
crit: $this > (($status == $CRITICAL) ? (85) : (95))
|
||||
delay: down 15m multiplier 1.5 max 1h
|
||||
info: average cpu utilization for the last 10 minutes (excluding iowait, nice and steal)
|
||||
to: sysadmin
|
||||
```
|
||||
|
||||
To tune this alarm to trigger warning and critical alarms at a lower CPU utilization, change the `warn` and `crit` lines
|
||||
to the values of your choosing. For example:
|
||||
|
||||
```yaml
|
||||
warn: $this > (($status >= $WARNING) ? (60) : (75))
|
||||
crit: $this > (($status == $CRITICAL) ? (75) : (85))
|
||||
```
|
||||
|
||||
Save the file and [reload Netdata's health configuration](#reload-health-configuration) to make your changes live.
|
||||
|
||||
### Silence an individual alarm
|
||||
|
||||
Instead of disabling an alarm altogether, or even disabling _all_ alarms, you can silence individual alarms by changing
|
||||
one line in a given health entity. To silence any single alarm, change the `to:` line in its entity to `silent`.
|
||||
|
||||
```yaml
|
||||
to: silent
|
||||
```
|
||||
|
||||
## Write a new health entity
|
||||
|
||||
While tuning existing alarms may work in some cases, you may need to write entirely new health entities based on how
|
||||
your systems, containers, and applications work.
|
||||
|
||||
Read the [health entity reference](#health-entity-reference) for a full listing of the format,
|
||||
syntax, and functionality of health entities.
|
||||
|
||||
To write a new health entity into a new file, navigate to your [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md),
|
||||
then use `touch` to create a new file in the `health.d/` directory. Use `edit-config` to start editing the file.
|
||||
|
||||
As an example, let's create a `ram-usage.conf` file.
|
||||
|
||||
```bash
|
||||
sudo touch health.d/ram-usage.conf
|
||||
sudo ./edit-config health.d/ram-usage.conf
|
||||
```
|
||||
|
||||
For example, here is a health entity that triggers a warning alarm when a node's RAM usage rises above 80%, and a
|
||||
critical alarm above 90%:
|
||||
|
||||
```yaml
|
||||
alarm: ram_usage
|
||||
on: system.ram
|
||||
lookup: average -1m percentage of used
|
||||
units: %
|
||||
every: 1m
|
||||
warn: $this > 80
|
||||
crit: $this > 90
|
||||
info: The percentage of RAM being used by the system.
|
||||
```
|
||||
|
||||
Let's look into each of the lines to see how they create a working health entity.
|
||||
|
||||
- `alarm`: The name for your new entity. The name needs to follow these requirements:
|
||||
- Any alphabet letter or number.
|
||||
- The symbols `.` and `_`.
|
||||
- Cannot be `chart name`, `dimension name`, `family name`, or `chart variable names`.
|
||||
|
||||
- `on`: Which chart the entity listens to.
|
||||
|
||||
- `lookup`: Which metrics the alarm monitors, the duration of time to monitor, and how to process the metrics into a
|
||||
usable format.
|
||||
- `average`: Calculate the average of all the metrics collected.
|
||||
- `-1m`: Use metrics from 1 minute ago until now to calculate that average.
|
||||
- `percentage`: Clarify that we're calculating a percentage of RAM usage.
|
||||
- `of used`: Specify which dimension (`used`) on the `system.ram` chart you want to monitor with this entity.
|
||||
|
||||
- `units`: Use percentages rather than absolute units.
|
||||
|
||||
- `every`: How often to perform the `lookup` calculation to decide whether or not to trigger this alarm.
|
||||
|
||||
- `warn`/`crit`: The value at which Netdata should trigger a warning or critical alarm. This example uses simple
|
||||
syntax, but most pre-configured health entities use
|
||||
[hysteresis](#special-use-of-the-conditional-operator) to avoid superfluous notifications.
|
||||
|
||||
- `info`: A description of the alarm, which will appear in the dashboard and notifications.
|
||||
|
||||
In human-readable format:
|
||||
|
||||
> This health entity, named **ram_usage**, watches the **system.ram** chart. It looks up the last **1 minute** of
|
||||
> metrics from the **used** dimension and calculates the **average** of all those metrics in a **percentage** format,
|
||||
> using a **% unit**. The entity performs this lookup **every minute**.
|
||||
>
|
||||
> If the average RAM usage percentage over the last 1 minute is **more than 80%**, the entity triggers a warning alarm.
|
||||
> If the usage is **more than 90%**, the entity triggers a critical alarm.
|
||||
|
||||
When you finish writing this new health entity, [reload Netdata's health configuration](#reload-health-configuration) to
|
||||
see it live on the local dashboard or Netdata Cloud.
|
||||
|
||||
## Reload health configuration
|
||||
|
||||
To make any changes to your health configuration live, you must reload Netdata's health monitoring system. To do that
|
||||
without restarting all of Netdata, run `netdatacli reload-health` or `killall -USR2 netdata`.
|
||||
|
||||
## Health entity reference
|
||||
|
||||
The following reference contains information about the syntax and options of _health entities_, which Netdata attaches
|
||||
|
|
@ -326,7 +453,8 @@ Everything is the same with [badges](https://github.com/netdata/netdata/blob/mas
|
|||
- `foreach DIMENSIONS` is optional, will always be the last parameter, and uses the same `,`/`|`
|
||||
rules as the `of` parameter. Each dimension you specify in `foreach` will use the same rule
|
||||
to trigger an alarm. If you set both `of` and `foreach`, Netdata will ignore the `of` parameter
|
||||
and replace it with one of the dimensions you gave to `foreach`.
|
||||
and replace it with one of the dimensions you gave to `foreach`. This option allows you to
|
||||
[use dimension templates to create dynamic alarms](#use-dimension-templates-to-create-dynamic-alarms).
|
||||
|
||||
The result of the lookup will be available as `$this` and `$NAME` in expressions.
|
||||
The timestamps of the timeframe evaluated by the database lookup is available as variables
|
||||
|
|
@ -1020,7 +1148,166 @@ expression.
|
|||
|
||||
It's currently not possible to schedule notifications from within the alarm template. For those scenarios where you need
|
||||
to temporary disable notifications (for instance when running backups triggers a disk alert) you can disable or silence
|
||||
notifications are runtime. The health checks can be controlled at runtime via the [health management
|
||||
api](https://github.com/netdata/netdata/blob/master/web/api/health/README.md).
|
||||
notifications are runtime. The health checks can be controlled at runtime via the
|
||||
[health management API](https://github.com/netdata/netdata/blob/master/web/api/health/README.md).
|
||||
|
||||
## Use dimension templates to create dynamic alarms
|
||||
|
||||
In v1.18 of Netdata, we introduced **dimension templates** for alarms, which simplifies the process of
|
||||
writing [alarm entities](#health-entity-reference) for
|
||||
charts with many dimensions.
|
||||
|
||||
Dimension templates can condense many individual entities into one—no more copy-pasting one entity and changing the
|
||||
`alarm`/`template` and `lookup` lines for each dimension you'd like to monitor.
|
||||
|
||||
### The fundamentals of `foreach`
|
||||
|
||||
Our dimension templates update creates a new `foreach` parameter to the
|
||||
existing [`lookup` line](#alarm-line-lookup). This
|
||||
is where the magic happens.
|
||||
|
||||
You use the `foreach` parameter to specify which dimensions you want to monitor with this single alarm. You can separate
|
||||
them with a comma (`,`) or a pipe (`|`). You can also use
|
||||
a [Netdata simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to create
|
||||
many alarms with a regex-like syntax.
|
||||
|
||||
The `foreach` parameter _has_ to be the last parameter in your `lookup` line, and if you have both `of` and `foreach` in
|
||||
the same `lookup` line, Netdata will ignore the `of` parameter and use `foreach` instead.
|
||||
|
||||
Let's get into some examples so you can see how the new parameter works.
|
||||
|
||||
> ⚠️ The following entities are examples to showcase the functionality and syntax of dimension templates. They are not
|
||||
> meant to be run as-is on production systems.
|
||||
|
||||
### Condensing entities with `foreach`
|
||||
|
||||
Let's say you want to monitor the `system`, `user`, and `nice` dimensions in your system's overall CPU utilization.
|
||||
Before dimension templates, you would need the following three entities:
|
||||
|
||||
```yaml
|
||||
alarm: cpu_system
|
||||
on: system.cpu
|
||||
lookup: average -10m percentage of system
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
|
||||
alarm: cpu_user
|
||||
on: system.cpu
|
||||
lookup: average -10m percentage of user
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
|
||||
alarm: cpu_nice
|
||||
on: system.cpu
|
||||
lookup: average -10m percentage of nice
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
```
|
||||
|
||||
With dimension templates, you can condense these into a single alarm. Take note of the `alarm` and `lookup` lines.
|
||||
|
||||
```yaml
|
||||
alarm: cpu_template
|
||||
on: system.cpu
|
||||
lookup: average -10m percentage foreach system,user,nice
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
```
|
||||
|
||||
The `alarm` line specifies the naming scheme Netdata will use. You can use whatever naming scheme you'd like, with `.`
|
||||
and `_` being the only allowed symbols.
|
||||
|
||||
The `lookup` line has changed from `of` to `foreach`, and we're now passing three dimensions.
|
||||
|
||||
In this example, Netdata will create three alarms with the names `cpu_template_system`, `cpu_template_user`, and
|
||||
`cpu_template_nice`. Every minute, each alarm will use the same database query to calculate the average CPU usage for
|
||||
the `system`, `user`, and `nice` dimensions over the last 10 minutes and send out alarms if necessary.
|
||||
|
||||
You can find these three alarms active by clicking on the **Alarms** button in the top navigation, and then clicking on
|
||||
the **All** tab and scrolling to the **system - cpu** collapsible section.
|
||||
|
||||

|
||||
|
||||
Let's look at some other examples of how `foreach` works so you can best apply it in your configurations.
|
||||
|
||||
### Using a Netdata simple pattern in `foreach`
|
||||
|
||||
In the last example, we used `foreach system,user,nice` to create three distinct alarms using dimension templates. But
|
||||
what if you want to quickly create alarms for _all_ the dimensions of a given chart?
|
||||
|
||||
Use a [simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md)! One example of a simple pattern is a single wildcard
|
||||
(`*`).
|
||||
|
||||
Instead of monitoring system CPU usage, let's monitor per-application CPU usage using the `apps.cpu` chart. Passing a
|
||||
wildcard as the simple pattern tells Netdata to create a separate alarm for _every_ process on your system:
|
||||
|
||||
```yaml
|
||||
alarm: app_cpu
|
||||
on: apps.cpu
|
||||
lookup: average -10m percentage foreach *
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
```
|
||||
|
||||
This entity will now create alarms for every dimension in the `apps.cpu` chart. Given that most `apps.cpu` charts have
|
||||
10 or more dimensions, using the wildcard ensures you catch every CPU-hogging process.
|
||||
|
||||
To learn more about how to use simple patterns with dimension templates, see
|
||||
our [simple patterns documentation](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md).
|
||||
|
||||
### Using `foreach` with alarm templates
|
||||
|
||||
Dimension templates also work
|
||||
with [alarm templates](#alarm-line-alarm-or-template).
|
||||
Alarm templates help you create alarms for all the charts with a given context—for example, all the cores of your
|
||||
system's CPU.
|
||||
|
||||
By combining the two, you can create dozens of individual alarms with a single template entity. Here's how you would
|
||||
create alarms for the `system`, `user`, and `nice` dimensions for every chart in the `cpu.cpu` context—or, in other
|
||||
words, every CPU core.
|
||||
|
||||
```yaml
|
||||
template: cpu_template
|
||||
on: cpu.cpu
|
||||
lookup: average -10m percentage foreach system,user,nice
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
```
|
||||
|
||||
On a system with a 6-core, 12-thread Ryzen 5 1600 CPU, this one entity creates alarms on the following charts and
|
||||
dimensions:
|
||||
|
||||
- `cpu.cpu0`
|
||||
- `cpu_template_user`
|
||||
- `cpu_template_system`
|
||||
- `cpu_template_nice`
|
||||
|
||||
- `cpu.cpu1`
|
||||
- `cpu_template_user`
|
||||
- `cpu_template_system`
|
||||
- `cpu_template_nice`
|
||||
|
||||
- `cpu.cpu2`
|
||||
- `cpu_template_user`
|
||||
- `cpu_template_system`
|
||||
- `cpu_template_nice`
|
||||
|
||||
- ...
|
||||
|
||||
- `cpu.cpu11`
|
||||
- `cpu_template_user`
|
||||
- `cpu_template_system`
|
||||
- `cpu_template_nice`
|
||||
|
||||
And how just a few of those dimension template-generated alarms look like in the Netdata dashboard.
|
||||
|
||||

|
||||
|
||||
All in all, this single entity creates 36 individual alarms. Much easier than writing 36 separate entities in your
|
||||
health configuration files!
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "alerta.io"
|
||||
title: "Alerta agent alert notifications"
|
||||
sidebar_label: "Alerta"
|
||||
description: "Send alarm notifications to Alerta to see the latest health status updates from multiple nodes in a single interface."
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/alerta/README.md"
|
||||
|
|
@ -9,7 +9,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# alerta.io
|
||||
# Alerta agent alert notifications
|
||||
|
||||
The [Alerta](https://alerta.io) monitoring system is a tool used to
|
||||
consolidate and de-duplicate alerts from multiple sources for quick
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Amazon SNS"
|
||||
title: "Amazon SNS agent alert notifications"
|
||||
sidebar_label: "Amazon SNS"
|
||||
description: "hello"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/awssns/README.md"
|
||||
|
|
@ -9,7 +9,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Amazon SNS
|
||||
# Amazon SNS agent alert notifications
|
||||
|
||||
As part of its AWS suite, Amazon provides a notification broker service called 'Simple Notification Service' (SNS). Amazon SNS works similarly to Netdata's own notification system, allowing to dispatch a single notification to multiple subscribers of different types. While Amazon SNS supports sending differently formatted messages for different delivery methods, Netdata does not currently support this functionality.
|
||||
Among other things, SNS supports sending notifications to:
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Custom"
|
||||
title: "Custom agent alert notifications"
|
||||
sidebar_label: "Custom endpoint"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/custom/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Custom
|
||||
# Custom agent alert notifications
|
||||
|
||||
Netdata allows you to send custom notifications to any endpoint you choose.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Discord.com"
|
||||
title: "Discord agent alert notifications"
|
||||
sidebar_label: "Discord"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/discord/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Discord.com
|
||||
# Discord agent alert notifications
|
||||
|
||||
This is what you will get:
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Dynatrace"
|
||||
title: "Dynatrace agent alert notifications"
|
||||
sidebar_label: "Dynatrace Events"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/dynatrace/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Dynatrace
|
||||
# Dynatrace agent alert notifications
|
||||
|
||||
Dynatrace allows you to receive notifications using their Events REST API.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Email"
|
||||
title: "Email agent alert notifications"
|
||||
sidebar_label: "Email"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/email/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': True, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Email
|
||||
# Email agent alert notifications
|
||||
|
||||
You need a working `sendmail` command for email alerts to work. Almost all MTAs provide a `sendmail` interface.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Flock"
|
||||
title: "Flock agent alert notifications"
|
||||
sidebar_label: "Flock"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/flock/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Flock
|
||||
# Flock agent alert notifications
|
||||
|
||||
This is what you will get:
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Send notifications to Gotify"
|
||||
title: "Gotify agent alert notifications"
|
||||
description: "Send alerts to your Gotify instance when an alert gets triggered in Netdata."
|
||||
sidebar_label: "Gotify"
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/health/notifications/gotify/README.md
|
||||
|
|
@ -9,7 +9,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Send notifications to Gotify
|
||||
# Gotify agent alert notifications
|
||||
|
||||
[Gotify](https://gotify.net/) is a self-hosted push notification service created for sending and receiving messages in real time.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Send notifications to Google Hangouts"
|
||||
title: "Google Hangouts agent alert notifications"
|
||||
description: "Send alerts to Send notifications to Google Hangouts any time an anomaly or performance issue strikes a node in your infrastructure."
|
||||
sidebar_label: "Google Hangouts"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/hangouts/README.md"
|
||||
|
|
@ -9,7 +9,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Send notifications to Google Hangouts
|
||||
# Google Hangouts agent alert notifications
|
||||
|
||||
[Google Hangouts](https://hangouts.google.com/) is a cross-platform messaging app developed by Google. You can configure
|
||||
Netdata to send alarm notifications to a Hangouts room in order to stay aware of possible health or performance issues
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "IRC"
|
||||
title: "IRC agent alert notifications"
|
||||
sidebar_label: "IRC"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/irc/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# IRC
|
||||
# IRC agent alert notifications
|
||||
|
||||
This is what you will get:
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Kavenegar"
|
||||
title: "Kavenegar agent alert notifications"
|
||||
sidebar_label: "Kavenegar"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/kavenegar/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Kavenegar
|
||||
# Kavenegar agent alert notifications
|
||||
|
||||
[Kavenegar](https://kavenegar.com/) as service for software developers, based in Iran, provides send and receive SMS, calling voice by using its APIs.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,15 +1,14 @@
|
|||
<!--
|
||||
title: "Send Netdata notifications to Matrix network rooms"
|
||||
title: "Matrix agent alert notifications"
|
||||
description: "Stay aware of warning or critical anomalies by sending health alarms to Matrix network rooms with Netdata's health monitoring watchdog."
|
||||
sidebar_label: "Matrix"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/matrix/README.md"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
||||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Matrix
|
||||
# Matrix agent alert notifications
|
||||
|
||||
Send notifications to [Matrix](https://matrix.org/) network rooms.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,14 +1,13 @@
|
|||
<!--
|
||||
title: "Messagebird"
|
||||
title: "Messagebird agent alert notifications"
|
||||
sidebar_label: "Messagebird"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/messagebird/README.md"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
||||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Messagebird
|
||||
# Messagebird agent alert notifications
|
||||
|
||||
The messagebird notifications will look like this on your Android device:
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Microsoft Teams"
|
||||
title: "Microsoft Teams agent alert notifications"
|
||||
sidebar_label: "Microsoft Teams"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/msteams/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Microsoft Teams
|
||||
# Microsoft Teams agent alert notifications
|
||||
|
||||
This is what you will get:
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Send notifications to Opsgenie"
|
||||
title: "Opsgenie agent alert notifications"
|
||||
description: "Send alerts to your Opsgenie incident response account any time an anomaly or performance issue strikes a node in your infrastructure."
|
||||
sidebar_label: "Opsgenie"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/opsgenie/README.md"
|
||||
|
|
@ -9,7 +9,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Send notifications to Opsgenie
|
||||
# Opsgenie agent alert notifications
|
||||
|
||||
[Opsgenie](https://www.atlassian.com/software/opsgenie) is an alerting and incident response tool. It is designed to
|
||||
group and filter alarms, build custom routing rules for on-call teams, and correlate deployments and commits to
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Send alert notifications to PagerDuty"
|
||||
title: "PagerDuty agent alert notifications"
|
||||
description: "Send alerts to your PagerDuty dashboard any time an anomaly or performance issue strikes a node in your infrastructure."
|
||||
sidebar_label: "PagerDuty"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/pagerduty/README.md"
|
||||
|
|
@ -9,7 +9,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Send alert notifications to PagerDuty
|
||||
# PagerDuty agent alert notifications
|
||||
|
||||
[PagerDuty](https://www.pagerduty.com/company/) is an enterprise incident resolution service that integrates with ITOps
|
||||
and DevOps monitoring stacks to improve operational reliability and agility. From enriching and aggregating events to
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Prowl"
|
||||
title: "Prowl agent alert notifications"
|
||||
sidebar_label: "Prowl"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/prowl/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Prowl
|
||||
# Prowl agent alert notifications
|
||||
|
||||
[Prowl](https://www.prowlapp.com/) is a push notification service for iOS devices. Netdata
|
||||
supports delivering notifications to iOS devices through Prowl.
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "PushBullet"
|
||||
title: "PushBullet agent alert notifications"
|
||||
sidebar_label: "PushBullet"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/pushbullet/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# PushBullet
|
||||
# PushBullet agent alert notifications
|
||||
|
||||
Will look like this on your browser:
|
||||

|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "PushOver"
|
||||
title: "PushOver agent alert notifications"
|
||||
sidebar_label: "PushOver"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/pushover/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# PushOver
|
||||
# PushOver agent alert notifications
|
||||
|
||||
pushover.net allows you to receive push notifications on your mobile phone. The service seems free for up to 7.500 messages per month.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Rocket.Chat"
|
||||
title: "Rocket.Chat agent alert notifications"
|
||||
sidebar_label: "Rocket Chat"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/rocketchat/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Rocket.Chat
|
||||
# Rocket.Chat agent alert notifications
|
||||
|
||||
This is what you will get:
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Slack"
|
||||
title: "Slack agent alert notifications"
|
||||
sidebar_label: "Slack"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/slack/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Slack
|
||||
# Slack agent alert notifications
|
||||
|
||||
This is what you will get:
|
||||

|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "SMS Server Tools 3"
|
||||
title: "SMS Server Tools 3 agent alert notifications"
|
||||
sidebar_label: "SMS server"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/smstools3/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# SMS Server Tools 3
|
||||
# SMS Server Tools 3 agent alert notifications
|
||||
|
||||
The [SMS Server Tools 3](http://smstools3.kekekasvi.com/) is a SMS Gateway software which can send and receive short messages through GSM modems and mobile phones.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Send notifications to StackPulse"
|
||||
title: "StackPulse agent alert notifications"
|
||||
description: "Send alerts to your StackPulse Netdata integration any time an anomaly or performance issue strikes a node in your infrastructure."
|
||||
sidebar_label: "StackPulse"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/stackpulse/README.md"
|
||||
|
|
@ -9,7 +9,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Send notifications to StackPulse
|
||||
# StackPulse agent alert notifications
|
||||
|
||||
[StackPulse](https://stackpulse.com/) is a software-as-a-service platform for site reliability engineering.
|
||||
It helps SREs, DevOps Engineers and Software Developers reduce toil and alert fatigue while improving reliability of
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Syslog"
|
||||
title: "Syslog agent alert notifications"
|
||||
sidebar_label: "Syslog"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/syslog/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Syslog
|
||||
# Syslog agent alert notifications
|
||||
|
||||
You need a working `logger` command for this to work. This is the case on pretty much every Linux system in existence, and most BSD systems.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Telegram"
|
||||
title: "Telegram agent alert notifications"
|
||||
sidebar_label: "Telegram"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/telegram/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Telegram
|
||||
# Telegram agent alert notifications
|
||||
|
||||
[Telegram](https://telegram.org/) is a messaging app with a focus on speed and security, it’s super-fast, simple and free. You can use Telegram on all your devices at the same time — your messages sync seamlessly across any number of your phones, tablets or computers.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<!--
|
||||
title: "Twilio"
|
||||
title: "Twilio agent alert notifications"
|
||||
sidebar_label: "Twilio"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/twilio/README.md"
|
||||
learn_status: "Published"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Twilio
|
||||
# Twilio agent alert notifications
|
||||
|
||||
Will look like this on your Android device:
|
||||
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
<!--
|
||||
title: "Pop up"
|
||||
sidebar_label: "Pop up notifications"
|
||||
title: "Browser pop up agent alert notifications"
|
||||
sidebar_label: "Browser pop ups"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/health/notifications/web/README.md"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
|
|
@ -8,7 +8,7 @@ learn_rel_path: "Integrations/Notify/Agent alert notifications"
|
|||
learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
||||
-->
|
||||
|
||||
# Pop up notifications
|
||||
# Broser pop up agent alert notifications
|
||||
|
||||
The Netdata dashboard shows HTML notifications, when it is open.
|
||||
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ description: "This is an in-depth look at how Netdata uses ML to detect anomalie
|
|||
sidebar_label: "Configure machine learning (ML) powered anomaly detection"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Setup"
|
||||
learn_rel_path: "Configuration"
|
||||
-->
|
||||
|
||||
# Machine learning (ML) powered anomaly detection
|
||||
|
|
|
|||
Loading…
Reference in New Issue